标签:实例 术语 -- persist set 失败 划算 作业 ack
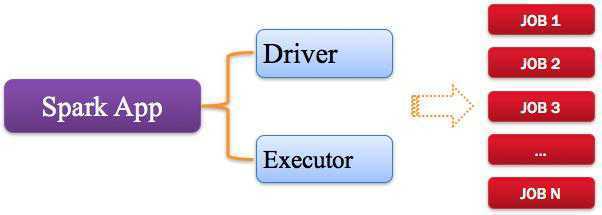
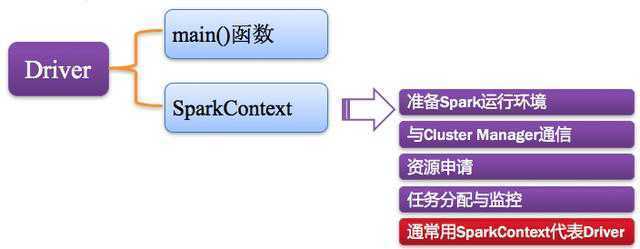
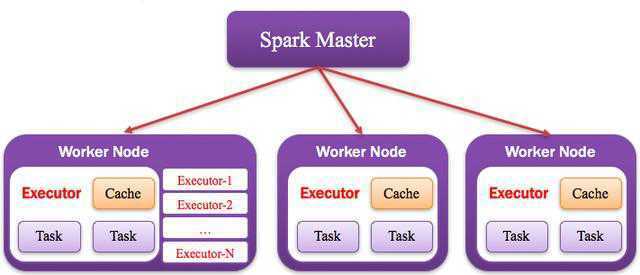
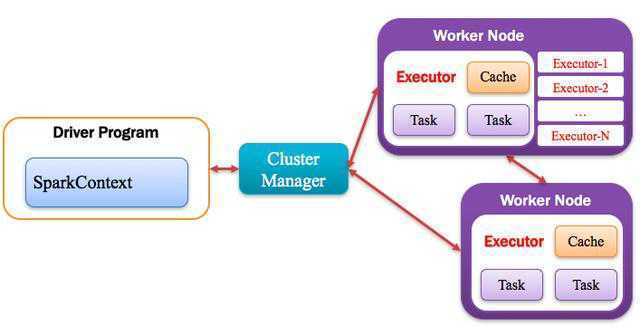
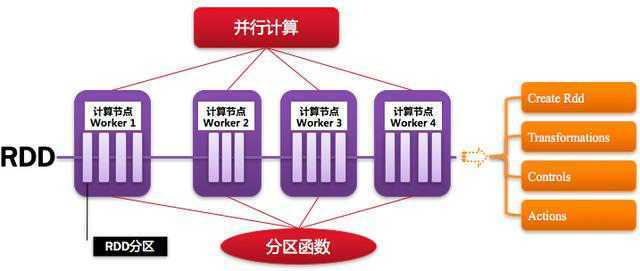
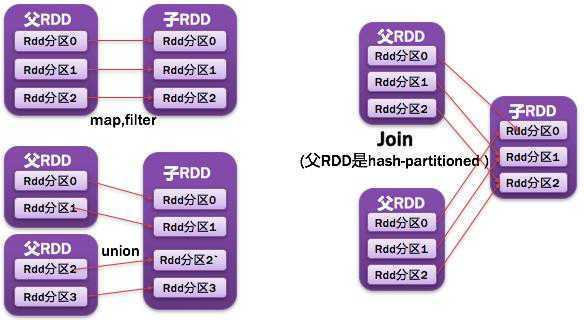
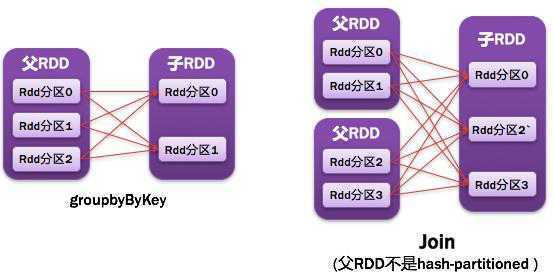
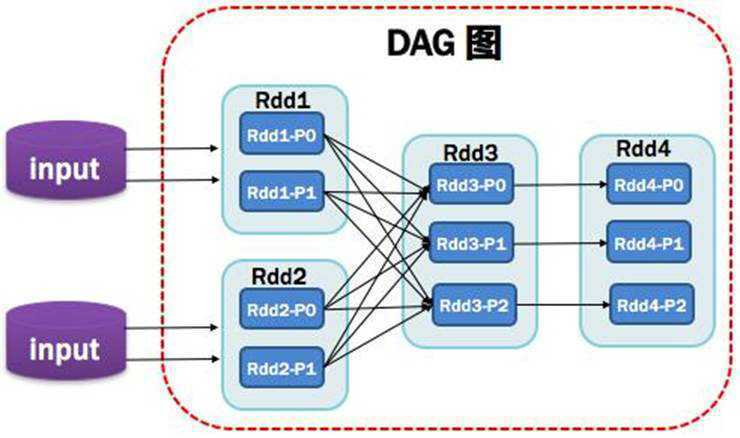
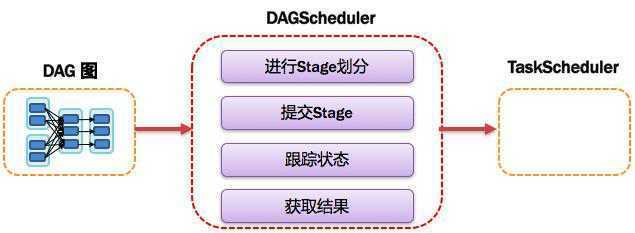
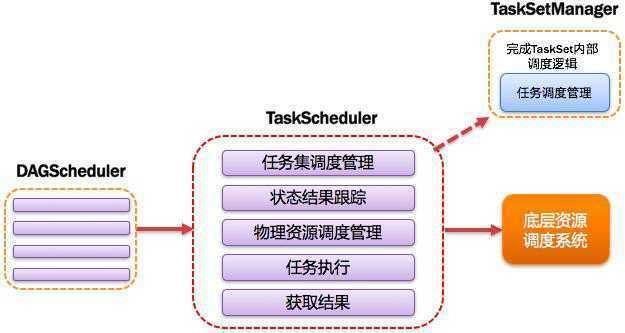
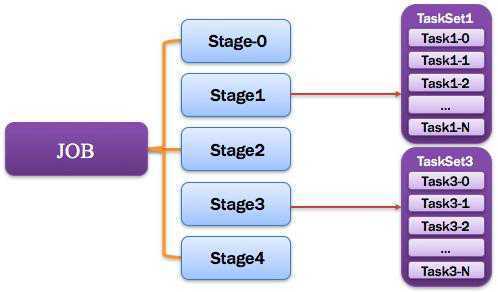
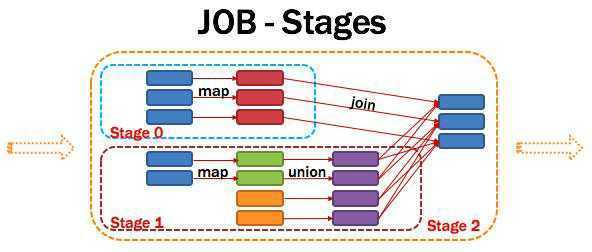
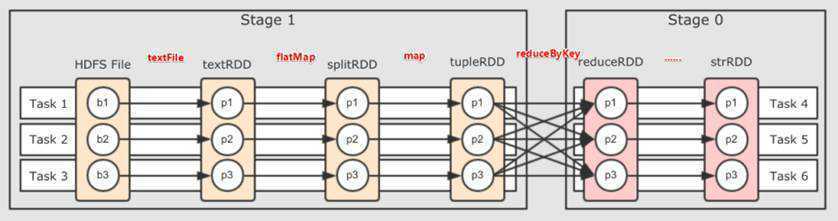
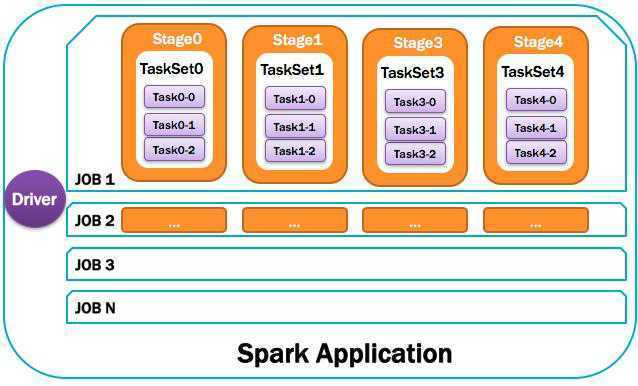
如下图所示:
将Taskset提交给worker(集群)运行并回报结果;
负责每个具体任务的实际物理调度。
Spark专业术语定义
原文地址:https://www.cnblogs.com/TiePiHeTao/p/a92136128fc931d9e9f3eae1a5ae1701.html