标签:发布 article detail name loading 图片 instance ring spring
原地址 https://www.cnblogs.com/devilwind/p/6902037.html
今天在新环境里部署tomcat, 刚开始启动很快,关闭之后再启动,却发现启动日志打印到
00:25:14.144 [localhost-startStop-1] INFO o.s.web.context.ContextLoader - Root WebApplicationContext: initialization completed in 6287 ms
一直hold着,tomcat程序也无法访问,以为是程序哪里配置错了,找了半天,甚至把spring的配置加载完全去掉才能启动,why, 程序在开发环境可是刷刷刷就跑起来的
后来一直没管这程序过了几分钟去看日志,发现tomcat 程序才启动完毕,why?原来不是卡住,而是慢
用jstack 观察一下启动线程, 发现 C2 CompilerThread 占用cpu很高, 同时 org.apache.catalina.util.SessionIdGeneratorBase.createSecureRandom这里读文件也产生阻塞,占用CPU也很高, 百度一下,以下转载其他人的两篇文章
在发布或重启某线上某服务时(jetty8作为服务器),常常发现有些机器的load会飙到非常高(高达70),并持续较长一段时间(5分钟)后回落(图1),与此同时响应时间曲线(图2)也与load曲线一致。注:load飙高的初始时刻是应用服务端口打开,流量打入时(load具体指什么可参考http://www.cnblogs.com/amsun/p/3155246.html)。
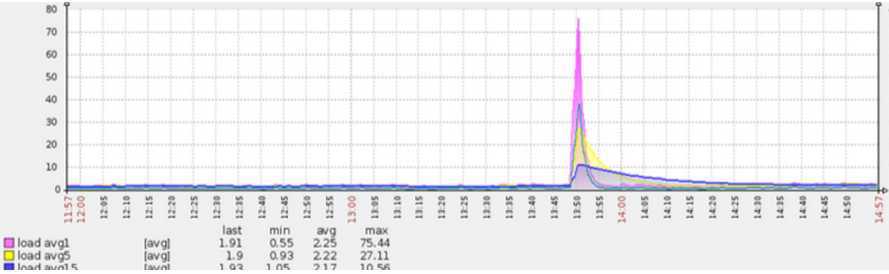
图1 发布时候load飙高
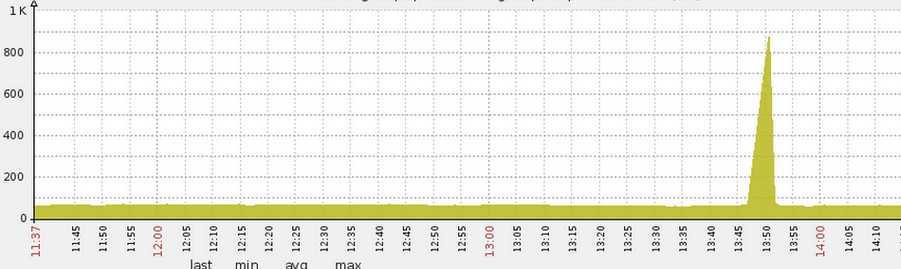
图2 发布时候响应时间飙高
发布时对资源使用情况进行监控。
1)通过top -H -p 查找cpu使用率较高的线程,发现2129和2130这两个线程cpu使用较高。
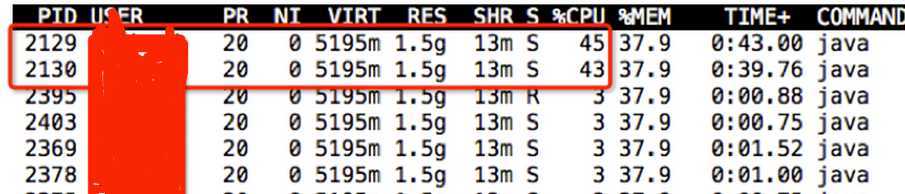
图3 查找cpu使用率较高的线程
2)通过jstack打印栈信息,并将线程号2129和2130转换成16进制(printf "%x\n" 2129),分别为851和852,发现这两个线程是编译线程(表1)。此外当这两个线程cpu使用率降低后load以及响应时间也马上恢复了正常,时间点非常吻合。
表1 cpu使用率较高的两个线程详细信息
"C2 CompilerThread1" daemon prio=10 tid=0x00007fce48125800 nid=0x852 waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE Locked ownable synchronizers: - None "C2 CompilerThread0" daemon prio=10 tid=0x00007fce48123000 nid=0x851 waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE Locked ownable synchronizers: - None
C2 CompilerThread线程项目启动初期cpu使用率那么高,它在干什么呢?
Java程序在启动的时候所有代码的执行都处于解释执行模式,只有在运行了一段时间后,根据代码方法执行的次数,或代码里循环的执行次数等达到一定的阈值才会编译成机器码,编译成机器码后执行效率会得到大幅提升,而随着执行时间进一步拉长,JVM的各种更高级的编译优化手段就会逐渐加上,例如if条件的执行状况,逃逸分析等。这里的C2 CompilerThread线程干的就是编译优化的活。
现在貌似可以解释之前的现象了。
在程序刚启动的时候,java还处于解释执行模式,因此服务效率很低,响应时间缓慢,处理得慢了,load自然也就高了。而当流量持续不断导入时,我们代码的很多方法执行次数不断增多,此时C2 CompilerThread线程不断收集优化信息,并且开始将一些热点代码优化编译成本地机器码,因此该线程的cpu使用率增高。而当C2 CompilerThread线程完成初始编译优化过程后,C2 CompilerThread线程的cpu使用率开始下降,与此同时优化后服务的性能大幅提升,服务响应时间也大大缩短,load也下降。
现在的症结在于编译优化过程持续时间较长,引起抖动。如何降低编译优化的持续时间呢?
如果在服务接受线上请求之前提前完成编译优化过程,那么将能避免此种抖动情况。一般的做法是预热,有两种方法:
a)程序主动预热:在启动完成后,程序主动的访问热点的代码,确保主要的热点代码已被编译成机器码后再放入流量,可通过-XX:+PrintCompilation来确认。
b)复制流量预热:通过tcpcopy软件拷贝一份线上nginx的流量进行预热,完成之后再导入线上流量。
如果能加快编译优化速度,那也能降低解释执行阶段导致的抖动时间。因此可以多拿几个线程来做编译,加快达到高峰性能的速度。
可以使用-XX:CICompilerCount参数来设置编译线程数目,这个值默认是2(之前在栈里看到有两个编译线程),我们可以加到4。
编译方式有三种:1)Client模式;2)Server模式;3)Tiered模式。我们服务默认是Server模式。
Server模式是采用c2高级编译的,会比较耗时且要运行一段时间才会触发编译。 Server模式的优点是编译后程序效率较高;
Client模式比较轻量也比较快触发(比Server模式触发快),编译优化后程序效率不如Server模式;
Tiered模式是Client模式和Server模式的折中,一开始会启用Client模式,可以在启动后更快的让部分代码先进入编译优化阶段,之后会启动Server模式,达到程序效率最大优化的目的。
Oracle JDK 7里的HotSpot VM已经开始有比较好的Tiered编译(tiered compilation)支持,可以设置参数-XX:+TieredCompilation来启动Tiered模式,java 8默认就是Tiered模式。
图4是到http://www.javaworld.com/article/2078635/enterprise-middleware/jvm-performance-optimization--part-2--compilers.html截取的不同编译方式的性能比较图,横坐标是时间,纵坐标是性能。可以看出Tired模式开始阶段性能与C1相当,当到达某一时刻后性能与C2相当。
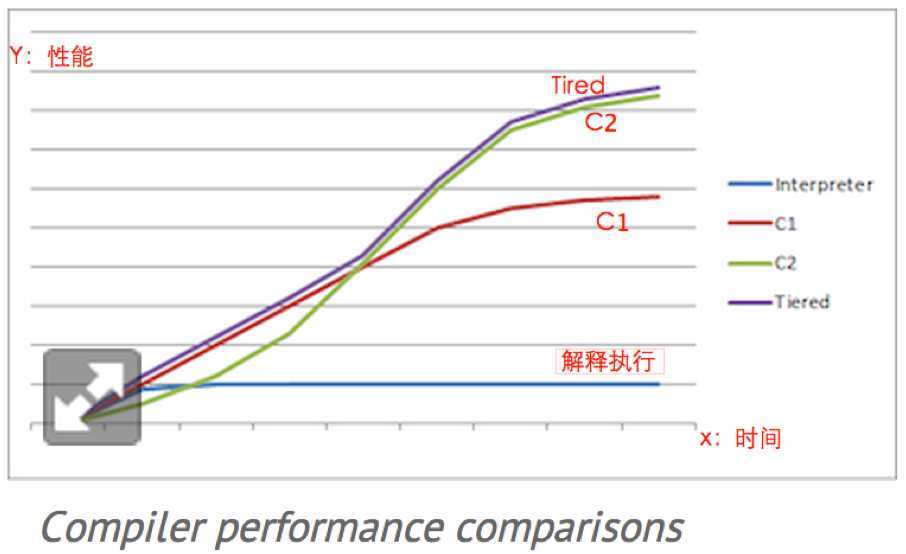
图4 不同编译模式的性能比较
简单起见采用方案2和方案3来进行优化。
采用方案2和3之后进行了多次发布,发布时除个别机器load达到10之外,基本没有过高现象(在2~4范围内),并且短时间(2分钟)内,load都会降到较合理水平(2左右),较发布时的load来看,比优化前要好很多。
方案2和方案3只是降低了抖动持续的时间以及抖动强度,并不能完全避免抖动。真正能避免抖动的方案应该是方案1,通过预热的方式实现平滑发布或重启
##########################################################################################################
通常情况下,tomcat启动只要2~3秒钟,突然有一天,tomcat启动非常慢,要花5~6分钟,查了很久,终于在这篇文章找到了解决方案,博主牛人啊。
原文参见:http://blog.csdn.net/chszs/article/details/49494701
Tomcat 8启动很慢,且日志上无任何错误,在日志中查看到如下信息:
Log4j:[2015-10-29 15:47:11] INFO ReadProperty:172 - Loading properties file from class path resource [resources/jdbc.properties] Log4j:[2015-10-29 15:47:11] INFO ReadProperty:172 - Loading properties file from class path resource [resources/common.properties] 29-Oct-2015 15:52:53.587 INFO [localhost-startStop-1] org.apache.catalina.util.SessionIdGeneratorBase.createSecureRandom Creation of SecureRandom instance for session ID generation using [SHA1PRNG] took [342,445] milliseconds.
Tomcat 7/8都使用org.apache.catalina.util.SessionIdGeneratorBase.createSecureRandom类产生安全随机类SecureRandom的实例作为会话ID,这里花去了342秒,也即接近6分钟。
SHA1PRNG算法是基于SHA-1算法实现且保密性较强的伪随机数生成器。
在SHA1PRNG中,有一个种子产生器,它根据配置执行各种操作。
1)如果Java.security.egd 属性或securerandom.source属性指定的是”file:/dev/random”或”file:/dev/urandom”,那么JVM 会使用本地种子产生器NativeSeedGenerator,它会调用super()方法,即调用 SeedGenerator.URLSeedGenerator(/dev/random)方法进行初始化。
2)如果java.security.egd属性或securerandom.source属性指定的是其它已存在的URL,那么会调用SeedGenerator.URLSeedGenerator(url)方法进行初始化。
这就是为什么我们设置值为”file:///dev/urandom”或者值为”file:/./dev/random”都会起作用的原因。
在这个实现中,产生器会评估熵池(entropy pool)中的噪声数量。随机数是从熵池中进行创建的。当读操作时,/dev/random设备会只返回熵池中噪声的随机字节。/dev/random非 常适合那些需要非常高质量随机性的场景,比如一次性的支付或生成密钥的场景。
当熵池为空时,来自/dev/random的读操作将被阻塞,直到熵池收集到足够的环境噪声数据。这么做的目的是成为一个密码安全的伪随机数发生器,熵池要有尽可能大的输出。对于生成高质量的加密密钥或者是需要长期保护的场景,一定要这么做。
那么什么是环境噪声?
随机数产生器会手机来自设备驱动器和其它源的环境噪声数据,并放入熵池中。产生器会评估熵池中的噪声数据的数量。当熵池为空时,这个噪声数据的收集是比较花时间的。这就意味着,Tomcat在生产环境中使用熵池时,会被阻塞较长的时间。
有两种解决办法:
1)在Tomcat环境中解决
可以通过配置JRE使用非阻塞的Entropy Source。
在catalina.sh中加入这么一行:-Djava.security.egd=file:/dev/./urandom 即可。
if [[ "$JAVA_OPTS" != *-Djava.security.egd=* ]]; then JAVA_OPTS="$JAVA_OPTS -Djava.security.egd=file:/dev/./urandom" fi
加入后再启动Tomcat,整个启动耗时下降到Server startup in 2912 ms。
2)在JVM环境中解决
打开$JAVA_PATH/jre/lib/security/java.security这个文件,找到下面的内容:
securerandom.source=file:/dev/urandom
替换成
securerandom.source=file:/dev/./urandom标签:发布 article detail name loading 图片 instance ring spring
原文地址:https://www.cnblogs.com/jackcui/p/11504295.html