标签:调用 不可用 依次 效率 lock inf image 回调 有向无环图
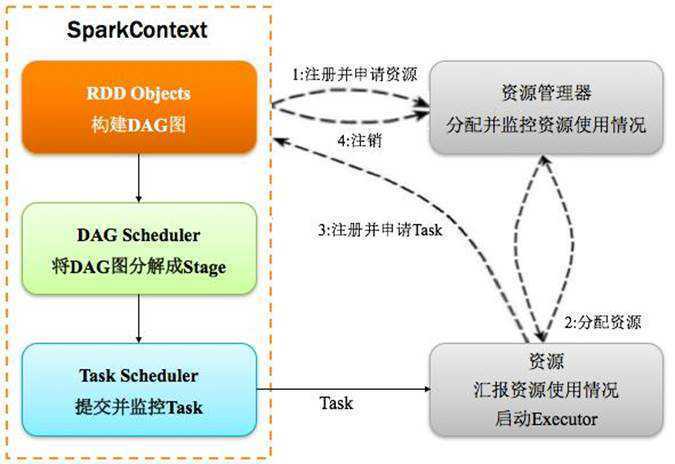
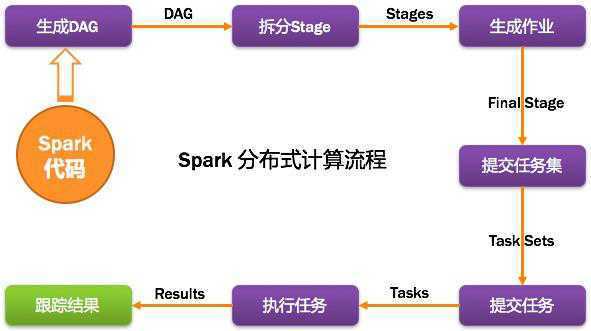
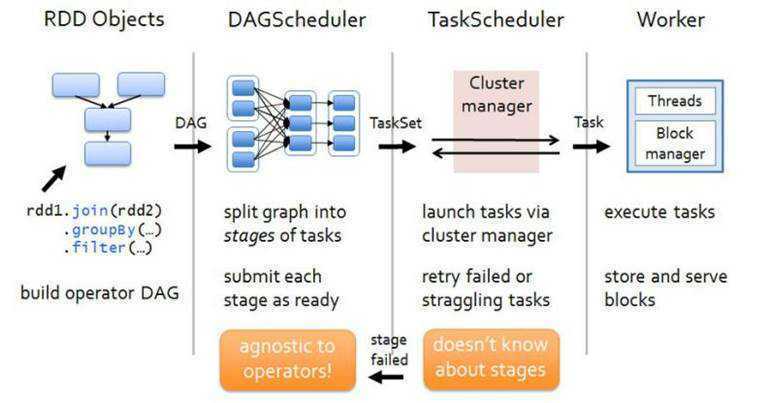
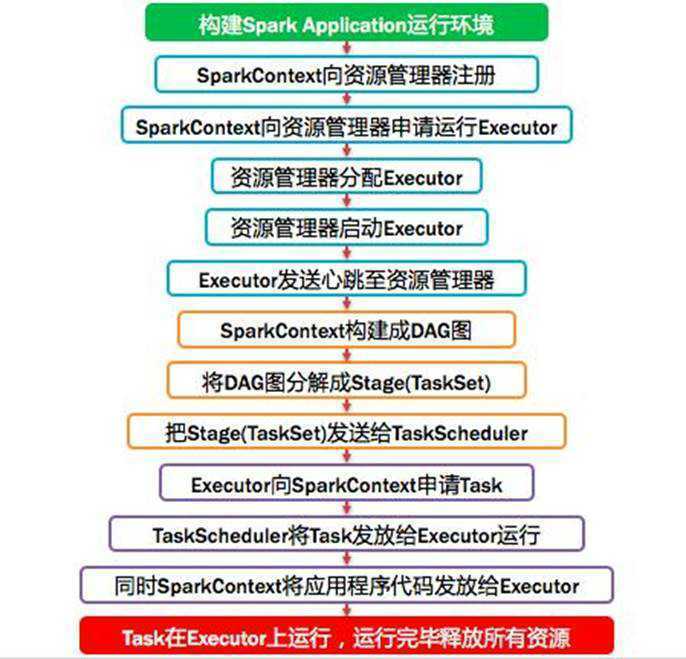
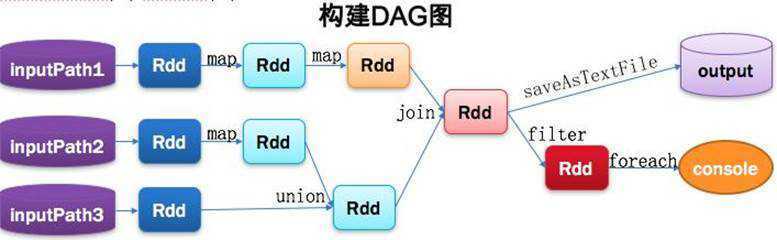
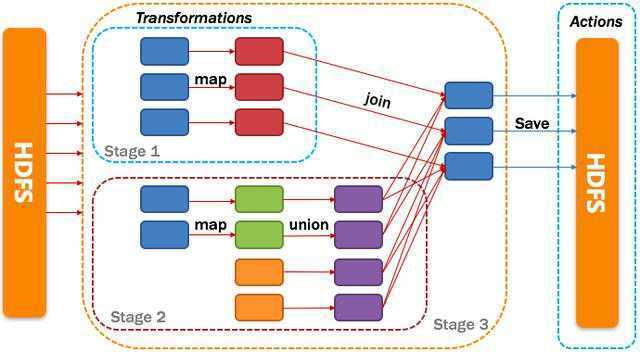
Spark program
Val lines1 = sc.textFile(inputPath1).map(...).map(...)
Val lines2 = sc.textFile(inputPath2).map(...)
Val lines3 = sc.textFile(inputPath3)
Val dtinone1 = lines2.union(lines3)
Val dtinone = lines1.join(dtinone1)
dtinone.saveAsTextFile(...)
dtinone.filter(...).foreach(...)
标签:调用 不可用 依次 效率 lock inf image 回调 有向无环图
原文地址:https://www.cnblogs.com/TiePiHeTao/p/bd6b2eac4d02c5279e702eb3b71a3d89.html