标签:frame 数据一致性 表示 sql spark 动态 通过 table 图片
一个流的数据源从逻辑上来说就是一个不断增长的动态表格,随着时间的推移,新数据被持续不断地添加到表格的末尾。
用户可以使用 Dataset/DataFrame 函数式API或者 SQL 来对这个动态数据源进行实时查询。每次查询在逻辑上就是对当前的表格内容执行一次 SQL 查询。什么时候执行查询则是由用户通过触发器(Trigger)来设定时间(毫秒级)。用户既可以设定执行周期让查询尽可能快地执行,从而达到实时的效果也可以使用默认的触发。
一个流的输出有多种模式,既可以是基于整个输入执行查询后的完整结果,也可以选择只输出与上次查询相比的差异,或者就是简单地追加最新的结果。
这个模型对于熟悉 SQL 的用户来说很容易掌握,对流的查询跟查询一个表格几乎完全一样,十分简洁,易于理解
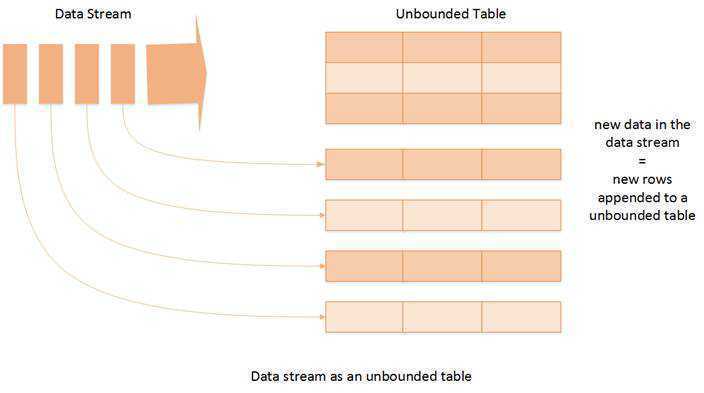
Structured Streaming最核心的思想就是将实时到达的数据看作是一个不断追加的unbound table无界表,到达流的每个数据项(RDD)就像是表中的一个新行被附加到无边界的表中.这样用户就可以用静态结构化数据的批处理查询方式进行流计算,如可以使用SQL对到来的每一行数据进行实时查询处理;
Structured Streaming将数据源映射为类似于关系数据库中的表,然后将经过计算得到的结果映射为另一张表,完全以结构化的方式去操作流式数据,这种编程模型非常有利于处理分析结构化的实时数据;
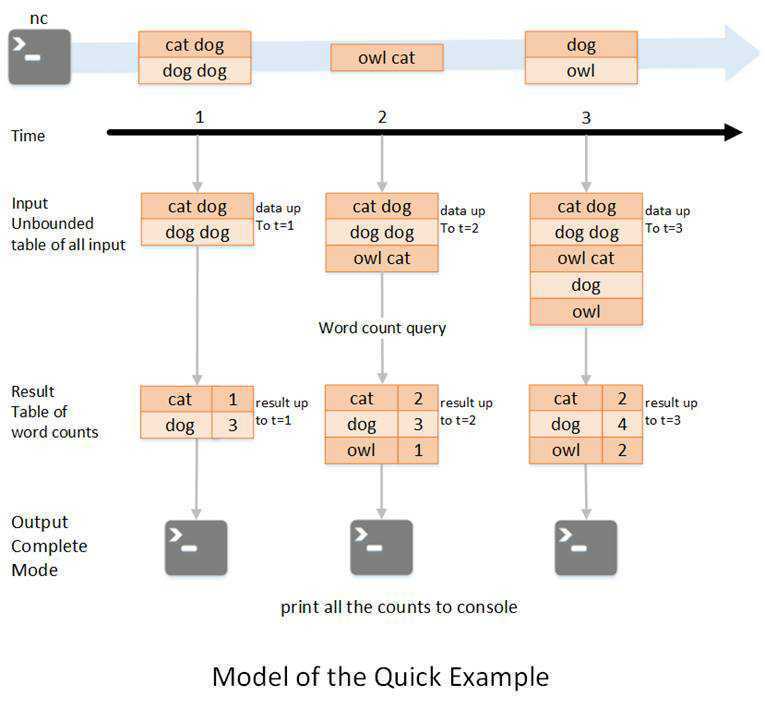
如图所示,
第一行表示从socket不断接收数据,
第二行是时间轴,表示每隔1秒进行一次数据处理,
第三行可以看成是之前提到的“unbound table",
第四行为最终的wordCounts是结果集。
当有新的数据到达时,Spark会执行“增量"查询,并更新结果集;
该示例设置为Complete Mode,因此每次都将所有数据输出到控制台;
1.在第1秒时,此时到达的数据为"cat dog"和"dog dog",因此我们可以得到第1秒时的结果集cat=1 dog=3,并输出到控制台;
2.当第2秒时,到达的数据为"owl cat",此时"unbound table"增加了一行数据"owl cat",执行word count查询并更新结果集,可得第2秒时的结果集为cat=2 dog=3 owl=1,并输出到控制台;
3.当第3秒时,到达的数据为"dog"和"owl",此时"unbound table"增加两行数据"dog"和"owl",执行word count查询并更新结果集,可得第3秒时的结果集为cat=2 dog=4 owl=2;
这种模型跟其他很多流式计算引擎都不同。大多数流式计算引擎都需要开发人员自己来维护新数据与历史数据的整合并进行聚合操作。然后我们就需要自己去考虑和实现容错机制、数据一致性的语义等。然而在structured streaming的这种模式下,spark会负责将新到达的数据与历史数据进行整合,并完成正确的计算操作,同时更新result table,不需要我们去考虑这些事情。
标签:frame 数据一致性 表示 sql spark 动态 通过 table 图片
原文地址:https://www.cnblogs.com/TiePiHeTao/p/ed75a58a6292aa8e0832ad41112152be.html