标签:miss logs ade export call 指标 headers -name cgo
Buffer 和Cache 的设计目的,是为了提升系统的 I/O 性能。它们利用内存,充当起慢速磁盘与快速
CPU 之间的桥梁,可以加速 I/O 的访问速度
buffers是内核缓存区用到的内存,对应的是/pro/meminfo中的buffers值
cache是内核页缓存和Slab用到的内存,对应的是/proc/meminfo中的cached和SReclaimable的和Buffer 和 Cache 分别缓存的是对磁盘和文件系统的读写数据。
直接通过缓存获取数据的请求次数,占所有数据请求次数的百分比 ,命中率越高,表示使用缓存带来的收益越高,应用程序的性能也就越好。
cachestat 提供了整个操作系统缓存的读写命中情况。
cachetop 提供了每个进程的缓存命中情况
这两个工具都是 bcc 软件包的一部分,它们基于 Linux 内核的 eBPF(extended Berkeley Packet Filters)机制,来跟踪内核中管理的缓存,并输出缓存的使用和命中情况
ubuntu 安装bcc-tools
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD
echo "deb https://repo.iovisor.org/apt/xenial xenial main" | sudo tee /etc/apt/sources.list
sudo apt-get update
sudo apt-get install -y bcc-tools libbcc-examples linux-headers-$(uname -r)手动配置bcc软件包到PATH
$ export PATH=$PATH:/usr/share/bcc/toolsroot@ubuntu:apt# cachestat 1 3
HITS MISSES DIRTIES HITRATIO BUFFERS_MB CACHED_MB
0 0 0 0.00% 108 818
0 0 0 0.00% 108 818
0 0 0 0.00% 108 818
root@ubuntu:apt# 我得这个版本没有显示总的io数
TOTAL ,表示总的 I/O 次数;
MISSES ,表示缓存未命中的次数;
HITS ,表示缓存命中的次数;
DIRTIES, 表示新增到缓存中的脏页数;
BUFFERS_MB 表示 Buffers 的大小,以 MB 为单位;
CACHED_MB 表示 Cache 的大小,以 MB 为单位。
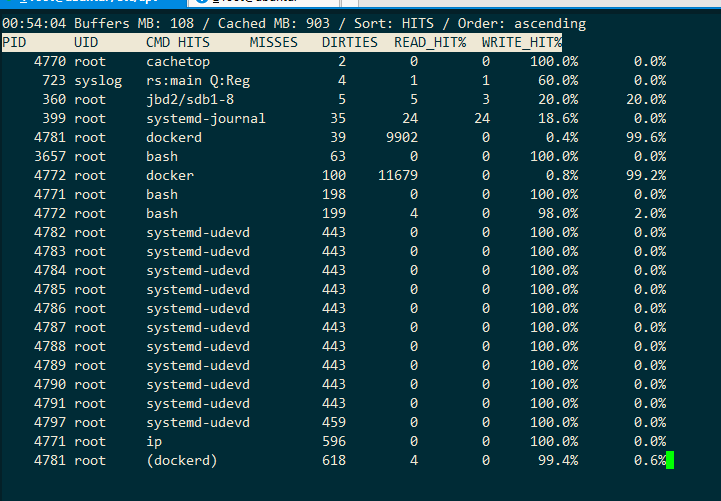
输出跟 top 类似,默认按照缓存的命中次数(HITS)排序,展示了每个进程的缓存命中情况。具体到每一个指标,这里的 HITS、MISSES 和 DIRTIES ,跟 cachestat 里的含义一样,分别代表间隔时间内的缓存命中次数、未命中次数以及新增到缓存中的脏页数。而 READ_HIT 和 WRITE_HIT ,分别表示读和写的缓存命中率
需要使用 pcstat 这个工具,来查看文件在内存中的缓存大小以及缓存比例 ,pcstat 是一个基于 Go 语言开发的工具,所以安装它之前,应该安装 Go 语言 :
sudo apt-get install golang安装完 Go 语言,再运行下面的命令安装 pcstat:
$ export GOPATH=~/go
$ export PATH=~/go/bin:$PATH
#最好环境变量的配置写进 .bashrc中,不然重启后失效
$ go get golang.org/x/sys/unix
$ go get github.com/tobert/pcstat/pcstat多数情况下会被墙,采用以下方法安装
root@ubuntu:src# mkdir -p golang.org/x
root@ubuntu:src# cd golang.org/x
root@ubuntu:x# git clone https://github.com/golang/sys.git
Cloning into 'sys'...
remote: Enumerating objects: 155, done.
remote: Counting objects: 100% (155/155), done.
remote: Compressing objects: 100% (101/101), done.
remote: Total 8244 (delta 101), reused 85 (delta 54), pack-reused 8089
Receiving objects: 100% (8244/8244), 6.64 MiB | 148.00 KiB/s, done.
Resolving deltas: 100% (7057/7057), done.
root@ubuntu:x# go get github.com/tobert/pcstat/pcstat安装后可查看文件的缓存情况:
root@ubuntu:x# pcstat /bin/ls
+---------+----------------+------------+-----------+---------+
| Name | Size (bytes) | Pages | Cached | Percent |
|---------+----------------+------------+-----------+---------|
| /bin/ls | 133792 | 33 | 33 | 100.000 |
+---------+----------------+------------+-----------+---------+这个输出中,Cached 就是 /bin/ls 在缓存中的大小,而 Percent 则是缓存的百分比。看到它们都是 33,这说明 /bin/ls 占用缓存的33%
机器配置:2 CPU,8GB 内存。
预先按照上面的步骤安装 bcc 和 pcstat 软件包,并把这些工具的安装路径添加到到PATH 环境变量中。
预先安装 Docker 软件包,比如 apt-get install docker.io
1,使用 dd 命令生成一个临时文件,用于后面的文件读取测试:
# 生成一个 512MB 的临时文件
$ dd if=/dev/sda1 of=file bs=1M count=512
# 清理缓存
$ echo 3 > /proc/sys/vm/drop_caches使用pcstat查看file的缓存
root@ubuntu:cache_test# pcstat file
+-------+----------------+------------+-----------+---------+
| Name | Size (bytes) | Pages | Cached | Percent |
|-------+----------------+------------+-----------+---------|
| file | 536870912 | 131072 | 0 | 000.000 |
+-------+----------------+------------+-----------+---------+
root@ubuntu:cache_test# 运行 cachetop 命令: cachetop 5
然后读这个文件,写道/dev/null中
root@ubuntu:cache_test# dd if=file of=/dev/null bs=1M
512+0 records in
512+0 records out
536870912 bytes (537 MB, 512 MiB) copied, 0.405824 s, 1.3 GB/s查看该进程的缓存命中率
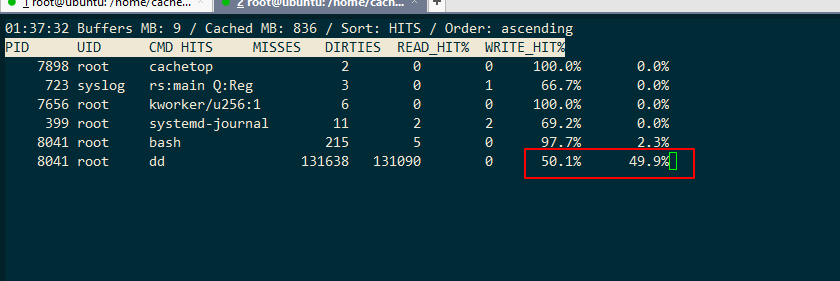
查看结果并不是所有的读都落到了磁盘上,事实上读请求的缓存命中率只有 50% 。
dd命令前清理了缓存,为什么缓存命中率是百分之49.8呢?(都已经没有缓存了,按理说是0)
因为预读
对于文件请求,Linux内核提供了预读策略,比要求长度多读一些,存储在page cache里,后续读是顺序的,马上可以利用page cache的数据返回,不必再次读硬盘。对于硬盘这种慢速设备而言,利用缓存数据大大提升I/O效率。再次执行刚才的 dd 命令:
root@ubuntu:cache_test# dd if=file of=/dev/null bs=1M
512+0 records in
512+0 records out
536870912 bytes (537 MB, 512 MiB) copied, 0.0814252 s, 6.6 GB/s
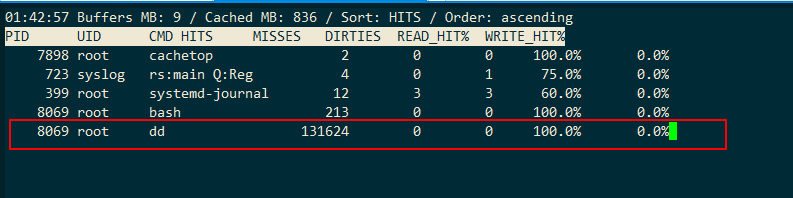
root@ubuntu:cache_test# 这次的读的缓存命中率是 100.0%,也就是说这次的 dd 命令全部命中了缓存,所以才会看到那么高的性能。
再次执行 pcstat 查看文件 file 的缓存情况:
root@ubuntu:cache_test# pcstat file
+-------+----------------+------------+-----------+---------+
| Name | Size (bytes) | Pages | Cached | Percent |
|-------+----------------+------------+-----------+---------|
| file | 536870912 | 131072 | 131072 | 100.000 |
+-------+----------------+------------+-----------+---------+
从 pcstat 的结果你可以发现,测试文件 file 已经被全部缓存了起来
$\color{red}{注意:dd 当成测试文件系统性能的工具,由于缓存的存在,就会导致测试结果严重失真 }$
文件读写的案例
每秒从磁盘分区 /dev/sda1 中读取 32MB 的数据,并打印出读取数据花费的时间。
此案例被打包为一个docker镜像,提供了下面两个选项,你可以根据系统配置,自行调整磁盘分区的路径以及 I/O 的大小 :
-d 选项,设置要读取的磁盘或分区路径,默认是查找前缀为 /dev/sd 或者 /dev/xvd 的磁盘。
-s 选项,设置每次读取的数据量大小,单位为字节,默认为 33554432(也就是32MB)1,开启一个终端执行cachetop 命令:
# 每隔 5 秒刷新一次数据
$ cachetop 52,开启一个终端,运行docker
docker run --privileged --name=app02 -itd feisky/app:io-direct /app -d /dev/sdb -s 335544323,查看日志输出
$ docker logs app
Reading data from disk /dev/sdb1 with buffer size 33554432
Time used: 0.929935 s to read 33554432 bytes
Time used: 0.949625 s to read 33554432 bytes从这里你可以看到,每读取 32 MB 的数据,就需要花 0.9 秒。 查看cachetop输出,app的缓存命中率是100%
16:39:18 Buffers MB: 73 / Cached MB: 281 / Sort: HITS / Order: ascending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
21881 root app 1024 0 0 100.0% 0.0%HITS 代表缓存的命中次数 ,内存以页为单位进行管理,而每个页的大小是 4KB。所以,在 5 秒的时间间隔里,命中的缓存为 1024*4K/1024 = 4MB,再除以 5 秒,可以得到每秒读的缓存是0.8MB,显然跟案例应用的 32 MB/s 相差太多
从结果可以看出,没有充分利用系统缓存。系统调用设置直接 I/O 的标志,可以绕过系统缓存
使用strace 分析
# strace -p $(pgrep app)
strace: Process 4988 attached
restart_syscall(<\.\.\. resuming interrupted nanosleep \.\.\.>) = 0
openat(AT_FDCWD, "/dev/sdb1", O_RDONLY|O_DIRECT) = 4
mmap(NULL, 33558528, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f448d2
read(4, "8vq\213\314\264u\373\4\336K\224\25@\371\1\252\2\262\252q\221\n0\30\225bD\252\26
write(1, "Time used: 0.948897 s to read 33"\.\.\., 45) = 45
close(4) = 0从 strace 的结果可以看到,案例应用调用了 openat 来打开磁盘分区 /dev/sdb1,并且传入的参数为 O_RDONLY|O_DIRECT(中间的竖线表示或)。O_RDONLY 表示以只读方式打开,而 O_DIRECT 则表示以直接读取的方式打开,这会绕过系统的缓存,查看源代码,过真如此

Buffers 和 Cache 可以极大提升系统的 I/O 性能。通常,我们用缓存命中率,来衡量缓存的使用效率。命中率越高,表示缓存被利用得越充分,应用程序的性能也就越好。
可以用achestat 和 cachetop 这两个工具,观察系统和进程的缓存命中情况。其中
cachestat 提供了整个系统缓存的读写命中情况。
cachetop 提供了每个进程的缓存命中情况
Buffers 和 Cache 都是操作系统来管理的,应用程序并不能直接控制这些缓存的内容和生命周期。所以,在应用程序开发中,一般要用专门的缓存组件,来进一步提升性能。
标签:miss logs ade export call 指标 headers -name cgo
原文地址:https://www.cnblogs.com/mrwuzs/p/11514268.html