标签:ade 分隔符 内容 apt 步骤 text 判断 排序 alt
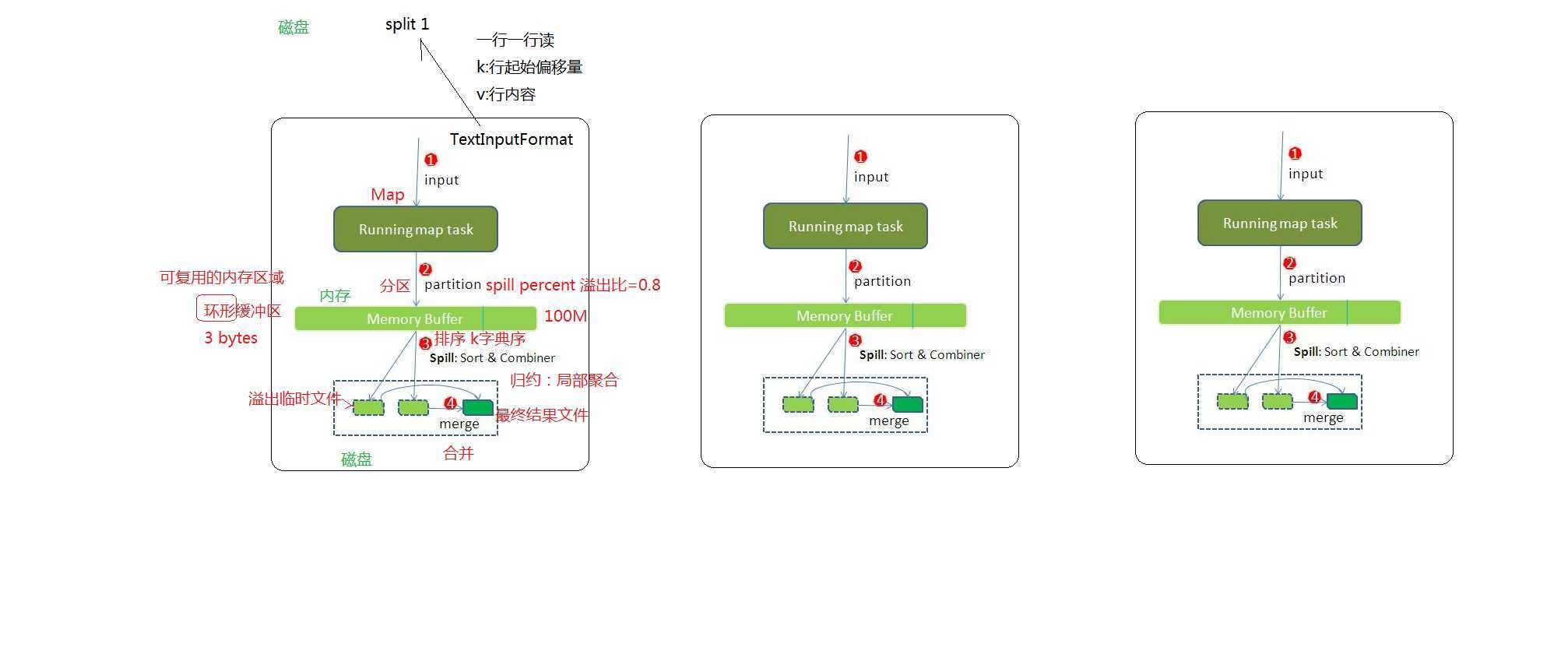
Map阶段流程:input File通过split被逻辑切分为多个split文件,通过Record按行读取内容给map(用户自己实现的)进行处理,数据被map处理结束之后交给OutputCollector收集器,对其结果key进行分区(默认使用hash分区),然后写入buffer,每个map task都有一个内存缓冲区,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据。
详细步骤:
标签:ade 分隔符 内容 apt 步骤 text 判断 排序 alt
原文地址:https://www.cnblogs.com/TiePiHeTao/p/b538975b98d02effba4b125491f5d398.html