标签:操作 主题 写日志 方式 读取 text 开发 offset span
★面试题:Receiver & Direct
开发中我们经常会利用SparkStreaming实时地读取kafka中的数据然后进行处理,在spark1.3版本后,kafkaUtils里面提供了两种创建DStream的方法:
KafkaUtils.createDstream(开发中不用,了解即可,但是面试可能会问)
Receiver作为常驻的Task运行在Executor等待数据,但是一个Receiver效率低,需要开启多个,再手动合并数据,再进行处理,很麻烦
Receiver那台机器挂了,可能会丢失数据,所以需要开启WAL(预写日志)保证数据安全,那么效率又会降低!
Receiver方式是通过zookeeper来连接kafka队列,调用Kafka高阶API,offset存储在zookeeper,由Receiver维护,
spark在消费的时候为了保证数据不丢也会在Checkpoint中存一份offset,可能会出现数据不一致
所以不管从何种角度来说,Receiver模式都不适合在开发中使用
Direct方式调用Kafka低阶API,offset自己存储和维护,默认由Spark维护在checkpoint中,消除了与zk不一致的情况
当然也可以自己手动维护,把offset存在mysql、redis中
所以基于Direct模式可以在开发中使用,且借助Direct模式的特点+手动操作可以保证数据的Exactly once 精准一次
●扩展:关于消息语义
|
实现方式 |
消息语义 |
存在的问题 |
|
Receiver |
at most once 最多被处理一次 |
会丢失数据 |
|
Receiver+WAL |
at least once 最少被处理一次 |
不会丢失数据,但可能会重复消费,且效率低 |
|
Direct+手动操作 |
exactly once 只被处理一次 |
不会丢失数据,也不会重复消费,且效率高 |
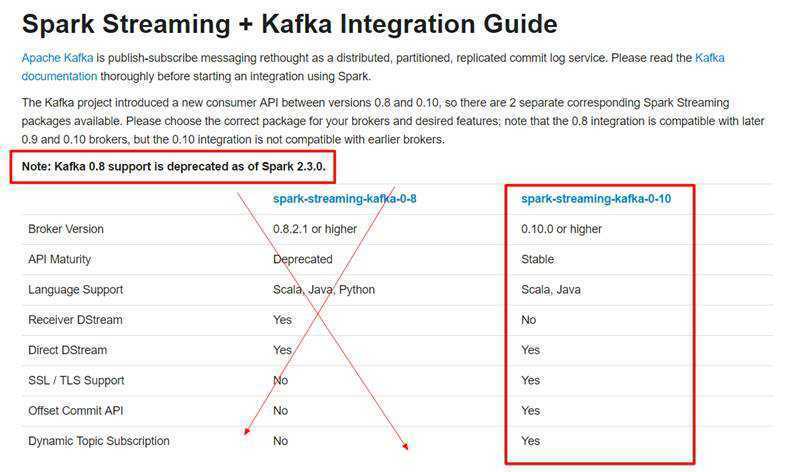
开发中SparkStreaming和kafka集成有两个版本:0.8及0.10+
0.8版本有Receiver和Direct模式(但是0.8版本生产环境问题较多,在Spark2.3之后不支持0.8版本了)
0.10以后只保留了direct模式(Reveiver模式不适合生产环境),并且API有变化(更加强大)

http://spark.apache.org/docs/latest/streaming-kafka-integration.html

标签:操作 主题 写日志 方式 读取 text 开发 offset span
原文地址:https://www.cnblogs.com/TiePiHeTao/p/35a269ecd1fda1e0e2ab3be025ab7cb7.html