标签:资源 浏览器 复用 提高 分布式 调度 计算 pre 包含
CDN 一般缓存的是静态资源。
CDN 的本质仍然是一个缓存,而且将数据缓存在离用户最近的地方,使用户已最快速度获取数据,即所谓网络访问第一跳。
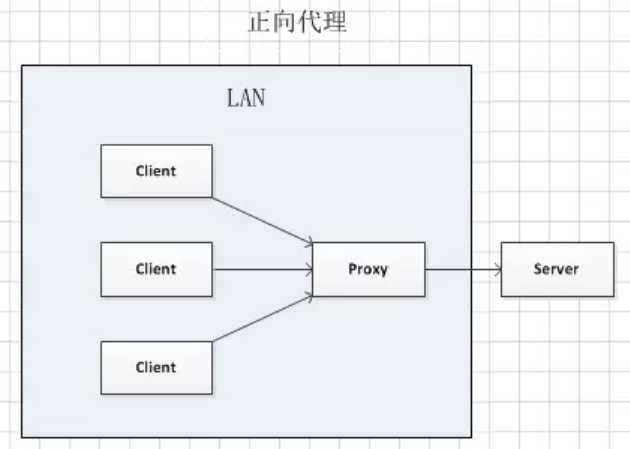
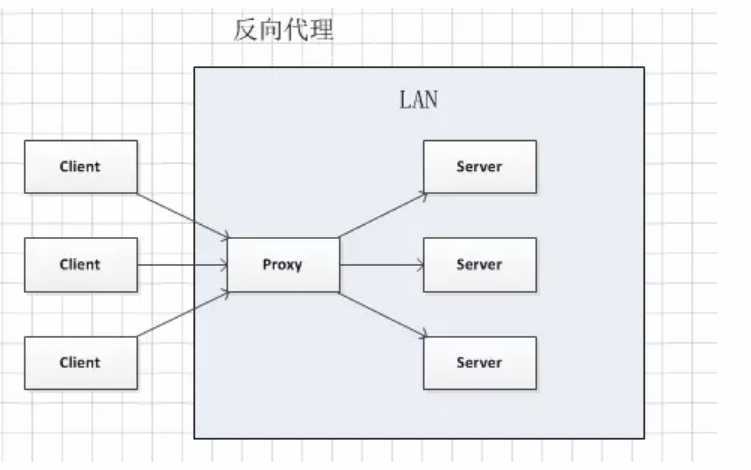
网站性能优化第一定律:优先考虑使用缓存优化性能。
缓存指将数据存储在相对较高访问速度的存储介质中,以供系统处理。一方面缓存访问速度快,可以减少数据访问的时间,另一方面如果缓存的数据是经过计算处理得到的,那么被缓存的数据无需重复计算即可直接使用,因此缓存还起到减少计算时间的作用。
缓存的本质是一个内存 HASH 表。
缓存主要用来存放那些读写比很高、很少变化的数据,如商品的类目信息,热门词的搜索列表信息、热门商品信息等。
缓存数据的选择:
数据不一致和脏读:
需要考虑缓存问题:缓存雪崩、缓存穿透、缓存预热
异步处理一般是通过分布式消息队列的方式。
异步处理可以解决一下问题:
在高并发场景下,使用负载均衡技术为一个应用构建一个由多台服务器组成的服务器集群,将并发访问请求分发到多台服务器上处理,避免单一服务器因负载压力过大而响应缓慢,使用户请求具有更好的响应延迟特性。
从资源利用的角度看,使用多线程的原因主要有两个:IO 阻塞和多 CPU。
线程数并非越多越好,那么启动多少线程合适呢?
有个参考公式:
启动线程数 = (任务执行时间 / (任务执行时间 - IO 等待时间)) * CPU 内核数
最佳启动线程数和 CPU 内核数成正比,和 IO 阻塞时间成反比。如果任务都是 CPU 计算型任务,那么线程数最多不要超过 CPU 内核数,因为启动再多线程,CPU 也来不及调度;相反如果是任务需要等待磁盘操作,网络响应,那么多启动线程有助于任务并罚赌,提高系统吞吐量。
线程安全问题
应该尽量减少那些开销很大的系统资源的创建和销毁,如数据库连接、网络通信连接、线程、复杂对象等。从编程角度,资源复用主要有两种模式:单例模式和对象池。
根据具体场景,选择合适的数据结构。
如果 Web 应用运行在 JVM 等具有垃圾回收功能的环境中,那么垃圾回收可能会对系统的性能特性产生巨大影响。立即垃圾回收机制有助于程序优化和参数调优,以及编写内存安全的代码。
考虑使用固态硬盘替代机械键盘,因为它的读写速度更快。
传统关系数据库的数据库索引一般都使用两级索引的 B+ 树结构,树的层次最多三层。因此可能需要 5 次磁盘访问才能更新一条记录(三次磁盘访问获得数据索引及行 ID,然后再进行一次数据文件读操作及一次数据文件写操作)。
由于磁盘访问是随机的,传统机械键盘在数据随机访问时性能较差,每次数据访问都需要多次访问磁盘影响数据访问性能。
许多 Nosql 数据库中的索引采用 LSM 树作为主要数据结构。LSM 树可视为一个 N 阶合并树。数据写操作都在内存中进行。在 LSM 树上进行一次数据更新不需要磁盘访问,速度远快于 B+ 树。
HDFS(分布式文件系统) 更被大型网站所青睐。它可以配合 MapReduce 并发计算任务框架进行大数据处理,可以在整个集群上并发访问所有磁盘,无需 RAID 支持。
标签:资源 浏览器 复用 提高 分布式 调度 计算 pre 包含
原文地址:https://www.cnblogs.com/yanhuidj/p/11541239.html