标签:contain 声明式 swarm 标准 rac 设计 公众 可靠 标准输出
 作者 |? 元乙? 阿里云日志服务数据采集客户端负责人,目前采集客户端 logtail 在集团百万规模部署,每天采集上万应用数 PB 数据,经历多次双 11、双 12 考验。
作者 |? 元乙? 阿里云日志服务数据采集客户端负责人,目前采集客户端 logtail 在集团百万规模部署,每天采集上万应用数 PB 数据,经历多次双 11、双 12 考验。
导读:随着 K8s 不断更新迭代,使用?K8s 日志系统建设的开发者,逐渐遇到了各种复杂的问题和挑战。本篇文章中,作者结合自己多年经验,分析 K8s 日志系统建设难点,期待为读者提供有益参考。
在 Logging 这块做了几年,最近 1 年来越来越多的同学来咨询如何为 Kubernetes 构建一个日志系统,或者是来求助在这过程中遇到一系列问题如何解决,授人以鱼不如授人以渔,于是想把我们这些年积累的经验以文章的形式发出来,让看到这篇文章的同学能少走弯路。这个系列文章定位为长篇连载,内容偏向落地实操以及经验分享,且内容会随着技术的迭代而不定期更新。
第一次听到 Kubernetes 的名字是在 2016 年,那个时候 Kubernetes 还处于和 Docker Swarm、Mesos 方案的“三国鼎立时代”,Kubernetes 由于一系列优势(可扩展、声明式接口、云友好)在这一竞争中崭露头角,最终获得统治地位。
Kubernetes 作为 CNCF 最核心的项目(没有之一),是 Cloud Native(云原生)落地的底座,目前阿里已经全面基于 Kubernetes 在开展全站的云原生改造,在 1-2 年内,阿里巴巴 100% 的业务都将跑在公有云上。
CloudNative 在?CNCF 的定义的核心是:在公有云、私有云、混合云等环境中,通过 Containers、Service Meshes、 MicroServices、Immutable Infrastructure、Declarative APIs 构建和运行可弹性扩展的且具有高容错性、易于管理、可观察、松耦合的应用系统。可观察性是应用系统必不可少的一个部分,云原生的设计理念中就有一条:面向诊断性设计(Diagnosability),包括集群级别的日志、Metric 和 Trace。
通常一个线上问题的定位流程是:通过 Metric 发现问题,根据 Trace 定位到问题模块,根据模块具体的日志定位问题原因。在日志中包括了错误、关键变量、代码运行路径等信息,这些是问题排查的核心,因此日志永远是线上问题排查的必经路径。 在阿里的十多年中,日志系统伴随着计算形态的发展在不断演进,大致分为 3 个主要阶段:
在阿里的十多年中,日志系统伴随着计算形态的发展在不断演进,大致分为 3 个主要阶段:
在 CNCF 中,可观察性的主要作用是问题的诊断,上升到公司整体层面,可观察性(Observability)不仅仅包括 DevOps 领域,还包括业务、运营、BI、审计、安全等领域,可观察性的最终的目标是实现公司各个方面的数字化、智能化。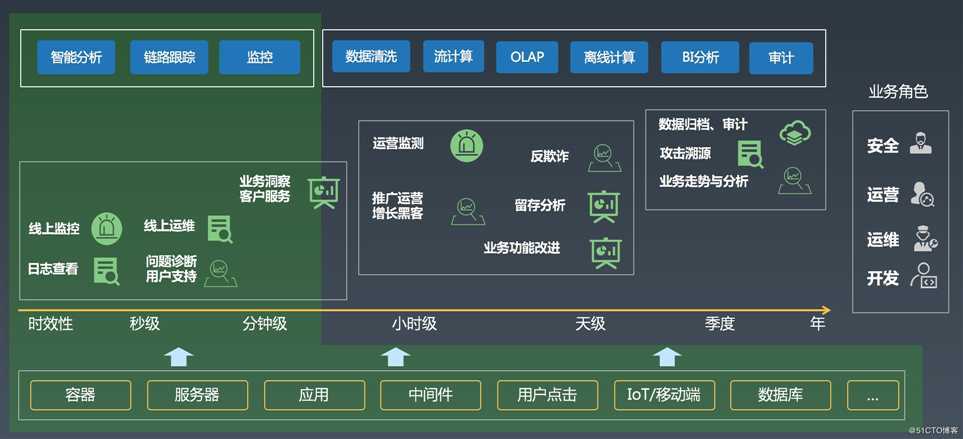
在阿里,几乎所有的业务角色都会涉及到各式各样的日志数据,为了支撑各类应用场景,我们开发了非常多的工具和功能:日志实时分析、链路追踪、监控、数据加工、流计算、离线计算、BI 系统、审计系统等等。日志系统主要专注于数据的实时采集、清洗、智能分析与监控以及对接各类各样的流计算、离线系统。
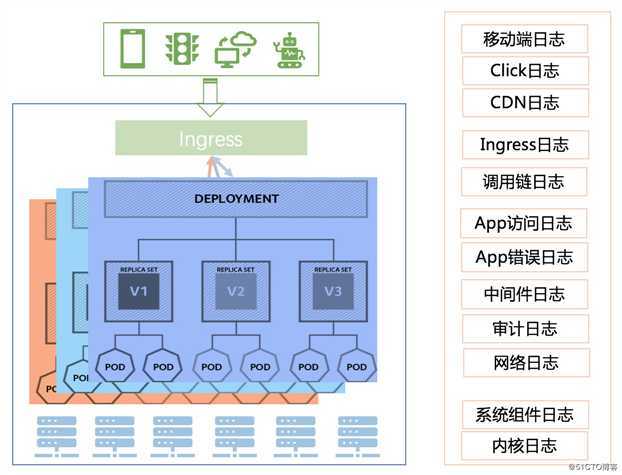 单纯日志系统的解决方案非常多,相对也比较成熟,这里就不再去赘述,我们此次只针对 Kubernetes 上的日志系统建设而论。Kubernetes 上的日志方案相比我们之前基于物理机、虚拟机场景的日志方案有很大不同,例如:
单纯日志系统的解决方案非常多,相对也比较成熟,这里就不再去赘述,我们此次只针对 Kubernetes 上的日志系统建设而论。Kubernetes 上的日志方案相比我们之前基于物理机、虚拟机场景的日志方案有很大不同,例如:
相信在搞 K8s 日志系统建设的同学看到上面的难点分析都会深有感触,后面我们会从落地角度出发,详细介绍在阿里我们如何去搭建 K8s 的日志系统,敬请关注。
“ 阿里巴巴云原生微信公众号(ID:Alicloudnative)关注微服务、Serverless、容器、Service Mesh等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术公众号。”
标签:contain 声明式 swarm 标准 rac 设计 公众 可靠 标准输出
原文地址:https://blog.51cto.com/13778063/2439063