标签:ict 功能 其他 cto 定义 primary 无法 染色体 mep
生物信息学
染色体可以据染色图谱判断染色体号码,1-22号染色体依次变短,它们影响机体发育,23号染色体决定性别。肿瘤是由于遗传密码变异造成的。因此,遗传密码的解读非常重要,但是因为遗传密码长度非常长,所以虽然已经全部测出来,但是破译它们依然存在很多难题。
生物信息学是一个学科领域,它的研究对象基因组,所以最初下定义是基因组信息学,主要内容是获取处理、存储、分配、分析和解释生物数据,即对生物信息的获取管理和信息挖掘。
破译具体而言是序列分析,对于编码序列看编码何种蛋白质,而对于非编码序列看起到何种作用。当今自然科学领域和技术科学领域中,生物信息学是结合三类问题的复合学科,包括基因组,信息结构和复杂性。
生物信息学:
1.Genome informatics is a scientific discipline that encompasses all aspects of genome information acquisition, processing, storage, distribution, analysis, and interpretation. 它是一个学科领域,包含着基因组信息的获取、处理、存储、分配 、分析和解释的所有方面。
2.生物信息学是把基因组DNA序列信息分析作为源头,破译隐藏在DNA序列中的遗传语言,特别是非编码区的实质;同时在发现了新基因信息之后进行蛋白质空间结构模拟和预测。
3.生物信息学的研究目标是揭示“基因组信息结构的复杂性及遗传语言的根本规律”。它是当今乃至下一世纪自然科学和技术科学领域中“基因组”、“信息结构”和“复杂性”这三个重大科学问题的有机结合。
随着human genomeproject完成,生物信息数据随之飞快增长,数据库种类逐渐变多,数据增长速度也逐渐变大。所以有以下四类数据库,DNA碱基数据库&expression sequence tag表达序列标签数据库,其中注释活细胞中正在实现功能的gene,这些gene覆盖人类基因组的90%。SNPs单核苷酸多态性数据库(single nucleotide polymorphisms),单独物种genome dataset。慢慢的,诞生了其他综合性数据库,就是二次数据库,包括Genbank;EMBL;DDBJ;这些数据库之间每天都在交互数据。
普遍研究流程是由Gene到primary sequence of protein,再到3D structure of protein,然后注释biological function,以前认为的junk gene现在部分转化为noncoding gene,并对其展开研究。
大基因组中的序列的拼接和注释主要依靠生物信息学方法。
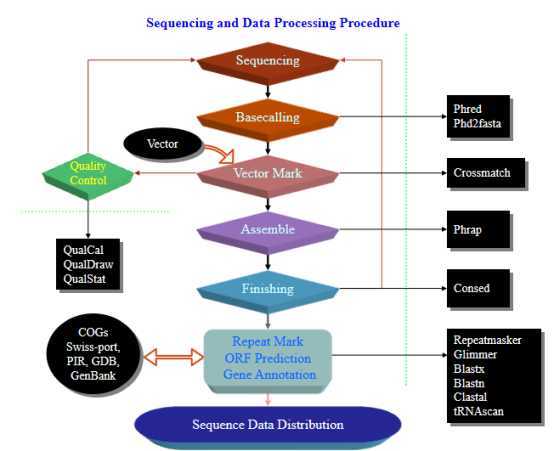
在经过Sequencing,basecalling测碱基荧光,vector mark(通过碱基比对去除引物)这些物理方法之后,生物信息学应用于assembly,Assembly的难题在于片段多无法正确拼接,所以assembly主要思路是对相同数据的采用不同切割方法,这些方法产生的不同断面,可以帮助我们找到拼接gene组的线索,如今supercompute帮助更快凭借,覆盖率可以99%。即使这样,也存在未能finishing(补洞)上的部分,这是很大的难题。但是至此,大部分序碱基信息可以读取出来,然后再repeat mark +ORF prediction+Gene annotation破译更多信息,解决生物学问题。
basecalling|vector mark|Assembly的难题|
标签:ict 功能 其他 cto 定义 primary 无法 染色体 mep
原文地址:https://www.cnblogs.com/yuanjingnan/p/11546253.html