标签:不难 领域 环境 工程 分布式 数据类型 数据结构 模式 变化
最近忙于对微商城用户的数据进行冗余分离,数据处理过程枯燥乏味,于是乎心里便想着能不能适当偷偷懒呢?答案当然是不切实际的,因为分离处理必须要有人员进行跟踪监视,也正是因为数据容易存在析出不彻底的现象,而对于这种现象所导致的结果,却恰恰需要进行人工的二次处理。简直可以称得上是令人焦头烂额、一筹莫展的了。
不过今天去北食堂吃饭的时候,刚好路过棚桥,也刚好看到了这一幕:棚桥东池塘的水十分浑浊,而西池塘的水却格外清澈,即使东池塘要比西池塘更大一些。对呀,浑浊的水容易在相对静止的环境下进行自我沉淀,这是自然现象,这也难道不正是我一直心心念念苦心追求的“适当偷偷懒”吗!
现在,我们大可以设想一下,将这东池塘中相对静止的浑浊的水,比作我们将要进行数据分离或提取的源数据,而西池塘清澈的水便是我们处理而得到的结果,处理过程就是利用了这种自然沉淀的方法。可以把这种现象、处理方法或处理过程称之为数据沉淀法则,简称沉淀法则或者析出法则。
下面将从前景概要、优点和局限性、实现原理、以及体系模式等方面进行介绍,关于沉淀法则是否适用于计算机科学领域,也是否真的能帮到我们在处理过程中得到适当的闲暇时光呢?其实,如果要完完全全地给一个很好的定义条件,我想这个所谓的“自然环境”也必定不会少到那里去,但我们姑且一试!
这里我为什么要先说前景概要、优点和局限性呢?目的是为了更好地论证我们的法则,也更好地区分法则的自身的应用局限性
从许多许多的现实应用中,我们其实不难发现,沉淀法则几乎无处不在,只是都以不大相同的面目示人,举些简单地例子:利用excel软件对数据进行排序、数据库的自增码变化、资源管理器的文件显示方式等等。那么,这些与我们所叙述的前景概要有什么关系呢?当然是有关系的,因为前者先一步存在,而我们现在所做的无非是对其进行定义、整理和设想。
在各位前辈的辛苦征承下,我们现在使用的工具和所承受的技术,早就已经形成相对稳定的发展态势,而且只能朝更加稳定和适用的方向发展。而技术发展的前提之一也就是数据必须得到处理,这对于数据处理就免不了要进行提取和排序等操作,而提取和排序等操作正是沉淀法则最典型的自然形态。
在4个主要的领域中:计算理论,算法与数据结构,编程方法与编程语言。
计算理论虽然表面上更具有原则性,但是我们大可以胆大地将沉淀法则与之一论:新的计算机理论必将在旧的理论的基础上,进行发展,那么就会产生类似沉淀的一般,将新生的态势不断发展。算法与数据结构就更加不用说了,简单地冒泡算法就是一个典型的例子,将权重的数往后排序的过程就是数据大颗粒沉淀的过程。编程方法与编程语言,和我们的沉淀法则貌似神离,但其间的关系却不免一说。
对于那些软件工程,人工智能,计算机网络与通信,数据库系统,并行计算,分布式计算,人机交互,机器翻译,计算机图形学,操作系统,以及数值和符号计算等等的领域,即使其本身不是法则的产物,也多多少少都具有法则的发展态势和过程利用。
这里对法则的优点和局限性作以简单地概括,或许独道的见解并非是最典型的,但它也必将是正面或者反面言论不可或缺的一部分。下面我们先来说说优点:
有利当然也有弊,对于法则的局限性,可简单概括如下:
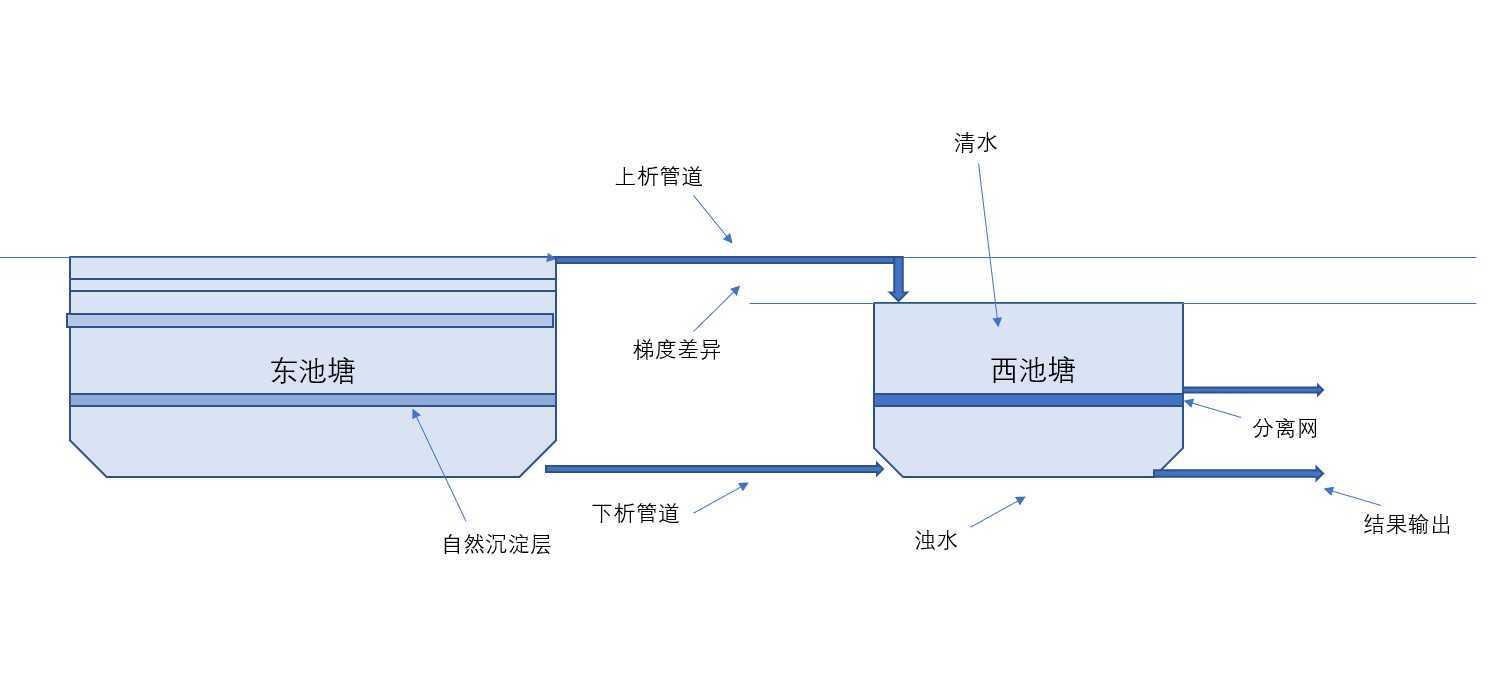
这里我们姑且还是以东池塘和西池塘为例,如下图,东池塘中存在自然的沉淀分离层,西池塘虽然存在一道分离网,但是可以将西池塘看作两个容器,展示缓存过滤的处理结果。梯度差异更加有利于高纯度的数据流出,下管道用于搬迁沉泥、杂石等杂质。东池塘还存在隐藏的部分,就是入水口,这里姑且省略。
但是很明显,如果只是让容器本身对需要处理的数据进行自我析出的话,那么将极大地耗损计算资源和时间。那样的话,空间和时间的效率将极大地被人们难以接受,而处理的办法就是第三方“催化剂”,也正是引入了“催化剂”的缘故,导致东池塘的水的稳定性稍微降低,但是稳定性的高低大小还是取决于“催化剂”本身,如果我们选对了就能事半功倍,如果选不好结果也是十分严重的。
当然上述,所谓的加第三方“催化剂”是其中的一种实现方式,也可以选择其它的。我们可以对上图的东池塘部分,进行相对的细化描述。下图模型有些简陋,但是原理是不变的。
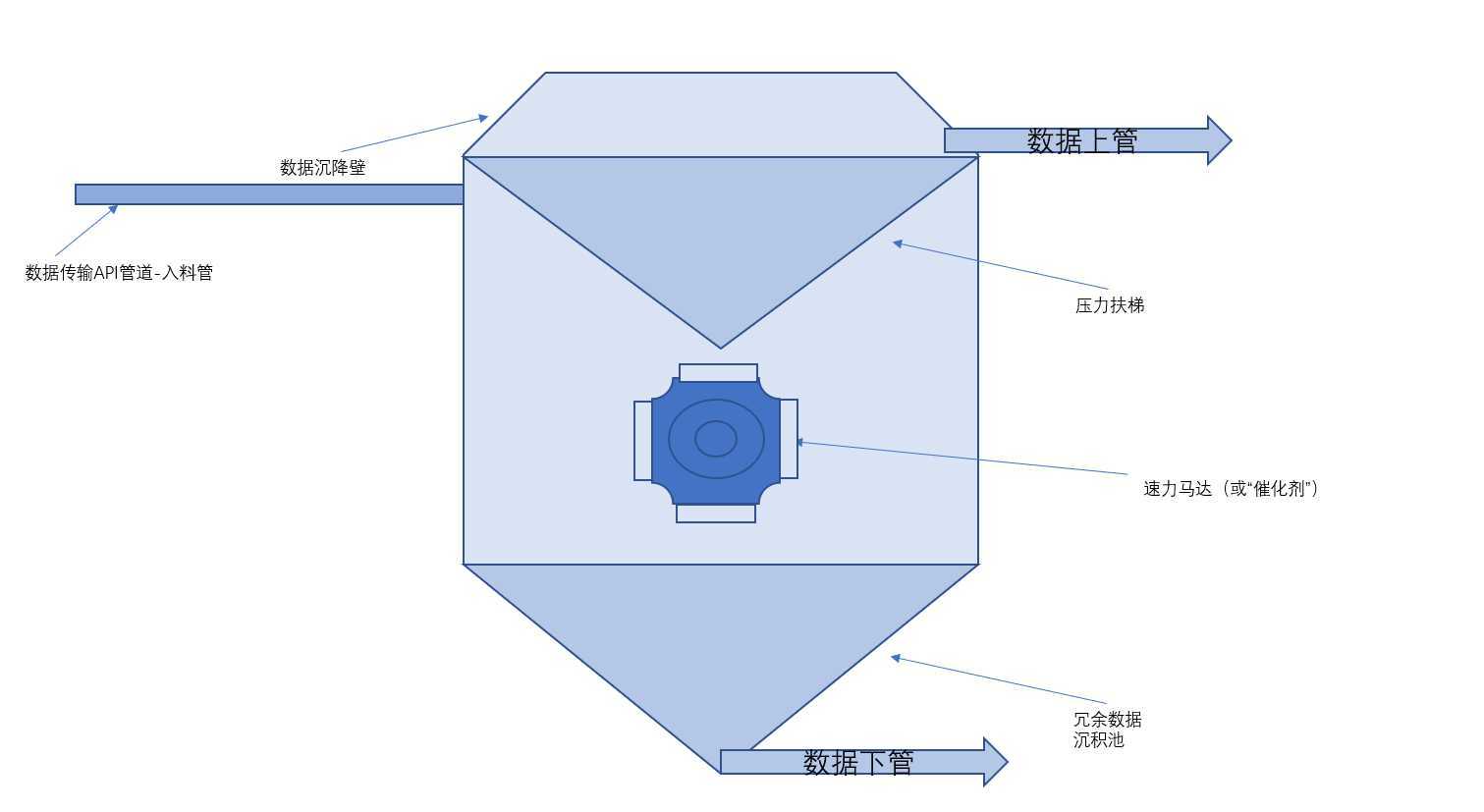
当数据从源容器或者第三方数据库,通过API被点入东池塘中时,水还是浑浊的。但是经过速力扇叶时,被高速打击在上层的压力扶梯面和下层的冗余数据沉积池的压力扶梯面上,便被高速筛选。以上仅仅是对于以东池塘和西池塘为例的模型而论,因为实际计算机内部的计算实现方式与池塘过滤有所不同,所以引入了下方沉积法则的体系模式。
沉积法则的体系模式分为权重分配沉积法、分层积降法和动态沉淀法。这两种分离析出模式的不同点在于:前者主要按元素的形式沉积,而分层积降法是整体对数据集进行沉降。理论上而言,分层积降法的计算能力时间较长,权重分配沉积法的计算压力更大。而动态沉淀法综合了两者的优点,采取的是了动态分批模式。
而对于权重分配沉积法、分层积降法和动态沉淀法的底层实现方法,又可以分为集合形式、链式、以及图式。这里所涉及的集合、链、以及图等的概念,并非是我们烂熟于心单纯的JAVA或者C数据结构,而是这些结构的有机体。
权重分配沉积法内部分为头权重、身重和尾权重。不管是哪一种的权重分配,都不免涉及权重如何分配以及权重如何回收等的问题。
首先,是头权重。简单地来说,就是对单个数据元素建立类似于键值对的形式,建立多列级别的晒选标签。权重级别根据数据处理人员或客户要求,建立级别库,当数据进入池子后,程序根据轮转的性质对元素进行体检,并将级别属性作为前置权重标签值分配。源数据可以不间断地进入容器,但是在筛选程序已经执行时,数据元仍然可以具备沉降特性。各司其职互不干涉,耗费的计算时间是连续的,但是权重分配和元素自我沉积互不影响。至于权重怎么回收?以权重的方式将数据元的数据属性分配到相应的容器中,经过了压力扶梯表面,另一个容器就进行数据元的结构拆除,还原数据的结构体,并建立新的结构集包装。
相应的身重和尾权重,与头权重相比区别不大,但可进行相应的优化。
与权重分配沉积法的头权重一样,将数据元加载到沉降容器中,但是不同在于:在数据集合完全进入处理池中前,数据处理池更改自身的标签类型,将自己化作缓存池。等到完全加载完毕将再次修改池的标签类型,真正地进入数据沉降过程。由于在数据处理前花费的等待时间过长,所以分层积降法也称为静态法。由于一次处理未见得得到高分离度数据集,所以首次底层沉降的部分会通过容器壁面深埋的多路管道,回到顶部,进行二次沉降。整体看似分层,由此得名。
在容器池中启用二级或多级缓存池,存储新来的数据元,并且在筛选程序未执行完前,前一批操作时不得从缓存池中释放。当筛选程序执行完后,调度一级缓存池的数据集。二级缓存池将数据分配给一级缓存池。当设置的N级缓存池缓存满了之后,将阻塞进料口,导致进料缓慢但不会造成数据集内容丢失。也可以采用多路复用的形式,在一层分离提取的基础上设置二层或多层分离池,提高提取的成分精度。
标签:不难 领域 环境 工程 分布式 数据类型 数据结构 模式 变化
原文地址:https://www.cnblogs.com/Raodi/p/11551304.html