标签:思考 分布式 network 回滚机制 很多 作者 帮助 问题: 乐观锁
作者|张磊 阿里云容器平台高级技术专家,CNCF 官方大使我们知道 Pod 是 Kubernetes 项目里面一个非常重要的概念,也是非常重要的一个原子调度单位,但是为什么我们会需要这样一个概念呢?在使用容器 Docker 的时候,也没有这个说法。其实,如果想要理解 Pod,首先要理解容器,所以来回顾一下容器的概念:
容器的本质实际上是一个进程,是一个视图被隔离,资源受限的进程。
容器里面 PID=1 的进程就是应用本身,这意味着管理虚拟机等于管理基础设施,因为我们是在管理机器,但管理容器却等于直接管理应用本身。这也是之前说过的不可变基础设施的一个最佳体现,这个时候,你的应用就等于你的基础设施,它一定是不可变的。
在以上面的例子为前提的情况下,Kubernetes 又是什么呢?很多人都说 Kubernetes 是云时代的操作系统,这个非常有意思,因为如果以此类推,容器镜像就是这个操作系统的软件安装包,它们之间是这样的一个类比关系。
如果说 Kubernetes 就是操作系统的话,那么不妨看一下真实的操作系统的例子。
例子里面有一个程序叫做 Helloworld,这个 Helloworld 程序实际上是由一组进程组成的,需要注意一下,这里说的进程实际上等同于 Linux 中的线程。
因为 Linux 中的线程是轻量级进程,所以如果从 Linux 系统中去查看 Helloworld 中的 pstree,将会看到这个 Helloworld 实际上是由四个线程组成的,分别是?{api、main、log、compute}。也就是说,四个这样的线程共同协作,共享 Helloworld 程序的资源,组成了 Helloworld 程序的真实工作情况。
这是操作系统里面进程组或者线程组中一个非常真实的例子,以上就是进程组的一个概念。

那么大家不妨思考一下,在真实的操作系统里面,一个程序往往是根据进程组来进行管理的。Kubernetes 把它类比为一个操作系统,比如说 Linux。针对于容器我们前面提到可以类比为进程,就是前面的 Linux 线程。那么 Pod 又是什么呢?实际上 Pod 就是我们刚刚提到的进程组,也就是 Linux 里的线程组。
说到进程组,首先建议大家至少有个概念上的理解,然后我们再详细的解释一下。
还是前面那个例子:Helloworld 程序由四个进程组成,这些进程之间会共享一些资源和文件。那么现在有一个问题:假如说现在把 Helloworld 程序用容器跑起来,你会怎么去做?
当然,最自然的一个解法就是,我现在就启动一个 Docker 容器,里面运行四个进程。可是这样会有一个问题,这种情况下容器里面 PID=1 的进程该是谁? 比如说,它应该是我的 main 进程,那么问题来了,“谁”又负责去管理剩余的 3 个进程呢?
这个核心问题在于,容器的设计本身是一种“单进程”模型,不是说容器里只能起一个进程,由于容器的应用等于进程,所以只能去管理 PID=1 的这个进程,其他再起来的进程其实是一个托管状态。 所以说服务应用进程本身就具有“进程管理”的能力。
比如说 Helloworld 的程序有 system 的能力,或者直接把容器里 PID=1 的进程直接改成 systemd,否则这个应用,或者是容器是没有办法去管理很多个进程的。因为 PID=1 进程是应用本身,如果现在把这个 PID=1 的进程给 kill 了,或者它自己运行过程中死掉了,那么剩下三个进程的资源就没有人回收了,这个是非常严重的一个问题。
反过来,如果真的把这个应用本身改成了 systemd,或者在容器里面运行了一个 systemd,将会导致另外一个问题:使得管理容器不再是管理应用本身了,而等于是管理 systemd,这里的问题就非常明显了。比如说我这个容器里面 run 的程序或者进程是 systemd,那么接下来,这个应用是不是退出了?是不是 fail 了?是不是出现异常失败了?实际上是没办法直接知道的,因为容器管理的是 systemd。这就是为什么在容器里面运行一个复杂程序往往比较困难的一个原因。
这里再帮大家梳理一下:由于容器实际上是一个“单进程”模型,所以如果你在容器里启动多个进程,只有一个可以作为 PID=1 的进程,而这时候,如果这个 PID=1 的进程挂了,或者说失败退出了,那么其他三个进程就会自然而然的成为孤儿,没有人能够管理它们,没有人能够回收它们的资源,这是一个非常不好的情况。
注意:Linux 容器的“单进程”模型,指的是容器的生命周期等同于 PID=1 的进程(容器应用进程)的生命周期,而不是说容器里不能创建多进程。当然,一般情况下,容器应用进程并不具备进程管理能力,所以你通过 exec 或者 ssh 在容器里创建的其他进程,一旦异常退出(比如 ssh 终止)是很容易变成孤儿进程的。
反过来,其实可以在容器里面 run 一个 systemd,用它来管理其他所有的进程。这样会产生第二个问题:实际上没办法直接管理我的应用了,因为我的应用被 systemd 给接管了,那么这个时候应用状态的生命周期就不等于容器生命周期。这个管理模型实际上是非常非常复杂的。
在 Kubernetes 里面,Pod 实际上正是 Kubernetes 项目为你抽象出来的一个可以类比为进程组的概念。
前面提到的,由四个进程共同组成的一个应用 Helloworld,在 Kubernetes 里面,实际上会被定义为一个拥有四个容器的 Pod,这个概念大家一定要非常仔细的理解。
就是说现在有四个职责不同、相互协作的进程,需要放在容器里去运行,在 Kubernetes 里面并不会把它们放到一个容器里,因为这里会遇到两个问题。那么在 Kubernetes 里会怎么去做呢?它会把四个独立的进程分别用四个独立的容器启动起来,然后把它们定义在一个 Pod 里面。
所以当 Kubernetes 把 Helloworld 给拉起来的时候,你实际上会看到四个容器,它们共享了某些资源,这些资源都属于 Pod,所以我们说 Pod 在 Kubernetes 里面只有一个逻辑单位,没有一个真实的东西对应说这个就是 Pod,不会有的。真正起来在物理上存在的东西,就是四个容器,这四个容器,或者说是多个容器的组合就叫做 Pod。并且还有一个概念一定要非常明确,Pod 是 Kubernetes 分配资源的一个单位,因为里面的容器要共享某些资源,所以 Pod 也是 Kubernetes 的原子调度单位。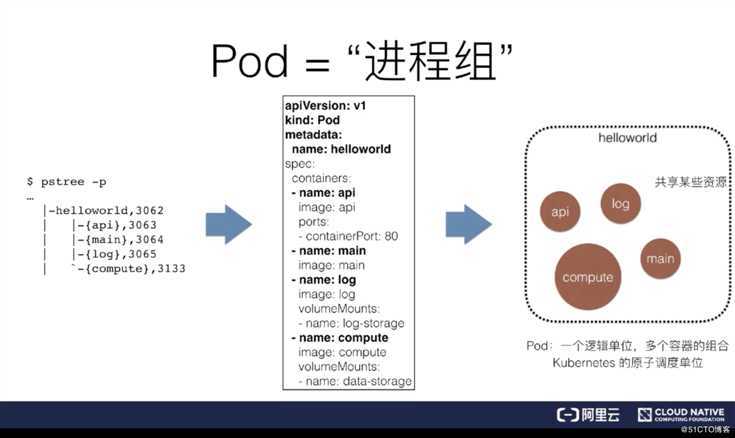
上面提到的 Pod 设计,也不是 Kubernetes 项目自己想出来的, 而是早在 Google 研发 Borg 的时候,就已经发现了这样一个问题。这个在 Borg paper 里面有非常非常明确的描述。简单来说 Google 工程师发现在 Borg 下面部署应用时,很多场景下都存在着类似于“进程与进程组”的关系。更具体的是,这些应用之前往往有着密切的协作关系,使得它们必须部署在同一台机器上并且共享某些信息。
以上就是进程组的概念,也是 Pod 的用法。
可能到这里大家会有一些问题:虽然了解这个东西是一个进程组,但是为什么要把 Pod 本身作为一个概念抽象出来呢?或者说能不能通过调度把 Pod 这个事情给解决掉呢?为什么 Pod 必须是 Kubernetes 里面的原子调度单位?
下面我们通过一个例子来解释。
假如现在有两个容器,它们是紧密协作的,所以它们应该被部署在一个 Pod 里面。具体来说,第一个容器叫做 App,就是业务容器,它会写日志文件;第二个容器叫做 LogCollector,它会把刚刚 App 容器写的日志文件转发到后端的 ElasticSearch 中。
两个容器的资源需求是这样的:App 容器需要 1G 内存,LogCollector 需要 0.5G 内存,而当前集群环境的可用内存是这样一个情况:Node_A:1.25G 内存,Node_B:2G 内存。
假如说现在没有 Pod 概念,就只有两个容器,这两个容器要紧密协作、运行在一台机器上。可是,如果调度器先把 App 调度到了 Node_A 上面,接下来会怎么样呢?这时你会发现:LogCollector 实际上是没办法调度到 Node_A 上的,因为资源不够。其实此时整个应用本身就已经出问题了,调度已经失败了,必须去重新调度。

以上就是一个非常典型的成组调度失败的例子。英文叫做:Task co-scheduling 问题,这个问题不是说不能解,在很多项目里面,这样的问题都有解法。
比如说在 Mesos 里面,它会做一个事情,叫做资源囤积(resource hoarding):即当所有设置了 Affinity 约束的任务都达到时,才开始统一调度,这是一个非常典型的成组调度的解法。
所以上面提到的“App”和“LogCollector”这两个容器,在 Mesos 里面,他们不会说立刻调度,而是等两个容器都提交完成,才开始统一调度。这样也会带来新的问题,首先调度效率会损失,因为需要等待。由于需要等,还会有外一个情况会出现,就是产生死锁,即互相等待的一个情况。这些机制在 Mesos 里都是需要解决的,也带来了额外的复杂度。
另一种解法是 Google 的解法。它在 Omega 系统(就是 Borg 下一代)里面,做了一个非常复杂且非常厉害的解法,叫做乐观调度。比如说:不管这些冲突的异常情况,先调度,同时设置一个非常精妙的回滚机制,这样经过冲突后,通过回滚来解决问题。这个方式相对来说要更加优雅,也更加高效,但是它的实现机制是非常复杂的。这个有很多人也能理解,就是悲观锁的设置一定比乐观锁要简单。
而像这样的一个 Task co-scheduling 问题,在 Kubernetes 里,就直接通过 Pod 这样一个概念去解决了。因为在 Kubernetes 里,这样的一个 App 容器和 LogCollector 容器一定是属于一个 Pod 的,它们在调度时必然是以一个 Pod 为单位进行调度,所以这个问题是根本不存在的。
在讲了前面这些知识点之后,我们来再次理解一下 Pod,首先 Pod 里面的容器是“超亲密关系”。
这里有个“超”字需要大家理解,正常来说,有一种关系叫做亲密关系,这个亲密关系是一定可以通过调度来解决的。
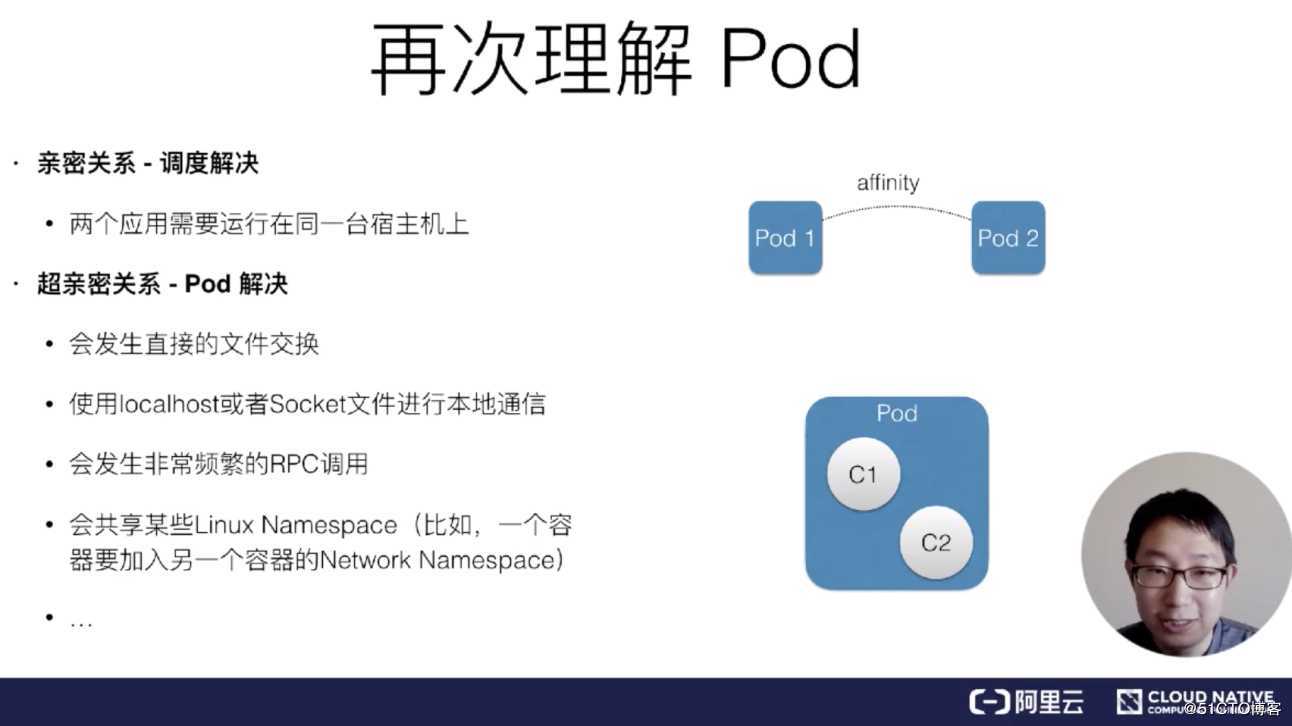
比如说现在有两个 Pod,它们需要运行在同一台宿主机上,那这样就属于亲密关系,调度器一定是可以帮助去做的。但是对于超亲密关系来说,有一个问题,即它必须通过 Pod 来解决。因为如果超亲密关系赋予不了,那么整个 Pod 或者说是整个应用都无法启动。
什么叫做超亲密关系呢?大概分为以下几类:
像以上几种关系都属于超亲密关系,它们都是在 Kubernetes 中会通过 Pod 的概念去解决的。
现在我们理解了 Pod 这样的概念设计,理解了为什么需要 Pod。它解决了两个问题:
像 Pod 这样一个东西,本身是一个逻辑概念。那在机器上,它究竟是怎么实现的呢?这就是我们要解释的第二个问题。既然说 Pod 要解决这个问题,核心就在于如何让一个 Pod 里的多个容器之间最高效的共享某些资源和数据。
因为容器之间原本是被 Linux Namespace 和 cgroups 隔开的,所以现在实际要解决的是怎么去打破这个隔离,然后共享某些事情和某些信息。这就是 Pod 的设计要解决的核心问题所在。
所以说具体的解法分为两个部分:网络和存储。
第一个问题是 Pod 里的多个容器怎么去共享网络?下面是个例子:
比如说现在有一个 Pod,其中包含了一个容器 A 和一个容器 B,它们两个就要共享 Network Namespace。在 Kubernetes 里的解法是这样的:它会在每个 Pod 里,额外起一个 Infra container 小容器来共享整个 Pod 的? Network Namespace。
Infra container 是一个非常小的镜像,大概 100~200KB 左右,是一个汇编语言写的、永远处于“暂停”状态的容器。由于有了这样一个 Infra container 之后,其他所有容器都会通过 Join Namespace 的方式加入到 Infra container 的 Network Namespace 中。
所以说一个 Pod 里面的所有容器,它们看到的网络视图是完全一样的。即:它们看到的网络设备、IP地址、Mac地址等等,跟网络相关的信息,其实全是一份,这一份都来自于 Pod 第一次创建的这个 Infra container。这就是 Pod 解决网络共享的一个解法。
在 Pod 里面,一定有一个 IP 地址,是这个 Pod 的 Network Namespace 对应的地址,也是这个 Infra container 的 IP 地址。所以大家看到的都是一份,而其他所有网络资源,都是一个 Pod 一份,并且被 Pod 中的所有容器共享。这就是 Pod 的网络实现方式。
由于需要有一个相当于说中间的容器存在,所以整个 Pod 里面,必然是 Infra container 第一个启动。并且整个 Pod 的生命周期是等同于 Infra container 的生命周期的,与容器 A 和 B 是无关的。这也是为什么在 Kubernetes 里面,它是允许去单独更新 Pod 里的某一个镜像的,即:做这个操作,整个 Pod 不会重建,也不会重启,这是非常重要的一个设计。
第二问题:Pod 怎么去共享存储?Pod 共享存储就相对比较简单。
比如说现在有两个容器,一个是 Nginx,另外一个是非常普通的容器,在 Nginx 里放一些文件,让我能通过 Nginx 访问到。所以它需要去 share 这个目录。我 share 文件或者是 share 目录在 Pod 里面是非常简单的,实际上就是把 volume 变成了 Pod level。然后所有容器,就是所有同属于一个 Pod 的容器,他们共享所有的 volume。

比如说上图的例子,这个 volume 叫做 shared-data,它是属于 Pod level 的,所以在每一个容器里可以直接声明:要挂载 shared-data 这个 volume,只要你声明了你挂载这个 volume,你在容器里去看这个目录,实际上大家看到的就是同一份。这个就是 Kubernetes 通过 Pod 来给容器共享存储的一个做法。
所以在之前的例子中,应用容器 App 写了日志,只要这个日志是写在一个 volume 中,只要声明挂载了同样的 volume,这个 volume 就可以立刻被另外一个 LogCollector 容器给看到。以上就是 Pod 实现存储的方式。
现在我们知道了为什么需要 Pod,也了解了 Pod 这个东西到底是怎么实现的。最后,以此为基础,详细介绍一下 Kubernetes 非常提倡的一个概念,叫做容器设计模式。
接下来将会用一个例子来给大家进行讲解。
比如我现在有一个非常常见的一个诉求:我现在要发布一个应用,这个应用是 JAVA 写的,有一个 WAR 包需要把它放到 Tomcat 的 web APP 目录下面,这样就可以把它启动起来了。可是像这样一个 WAR 包或 Tomcat 这样一个容器的话,怎么去做,怎么去发布?这里面有几种做法。

第一种方式:可以把 WAR 包和 Tomcat 打包放进一个镜像里面。但是这样带来一个问题,就是现在这个镜像实际上揉进了两个东西。那么接下来,无论是我要更新 WAR 包还是说我要更新 Tomcat,都要重新做一个新的镜像,这是比较麻烦的;
但是这时会发现一个问题:这种做法一定需要维护一套分布式存储系统。因为这个容器可能第一次启动是在宿主机 A 上面,第二次重新启动就可能跑到 B 上去了,容器它是一个可迁移的东西,它的状态是不保持的。所以必须维护一套分布式存储系统,使容器不管是在 A 还是在 B 上,都可以找到这个 WAR 包,找到这个数据。
注意,即使有了分布式存储系统做 Volume,你还需要负责维护 Volume 里的 WAR 包。比如:你需要单独写一套 Kubernetes Volume 插件,用来在每次 Pod 启动之前,把应用启动所需的 WAR 包下载到这个 Volume 里,然后才能被应用挂载使用到。
这样操作带来的复杂程度还是比较高的,且这个容器本身必须依赖于一套持久化的存储插件(用来管理 Volume 里的 WAR 包内容)。
所以大家有没有考虑过,像这样的组合方式,有没有更加通用的方法?哪怕在本地 Kubernetes 上,没有分布式存储的情况下也能用、能玩、能发布。
实际上方法是有的,在 Kubernetes 里面,像这样的组合方式,叫做 Init Container。

还是同样一个例子:在上图的 yaml 里,首先定义一个 Init Container,它只做一件事情,就是把 WAR 包从镜像里拷贝到一个 Volume 里面,它做完这个操作就退出了,所以 Init Container 会比用户容器先启动,并且严格按照定义顺序来依次执行。
然后,这个关键在于刚刚拷贝到的这样一个目的目录:APP 目录,实际上是一个 Volume。而我们前面提到,一个 Pod 里面的多个容器,它们是可以共享 Volume 的,所以现在这个 Tomcat 容器,只是打包了一个 Tomcat 镜像。但在启动的时候,要声明使用 APP 目录作为我的 Volume,并且要把它们挂载在 Web APP 目录下面。
而这个时候,由于前面运行过了一个 Init Container,已经执行完拷贝操作了,所以这个 Volume 里面已经存在了应用的 WAR 包:就是 sample.war,绝对已经存在这个 Volume 里面了。等到第二步执行启动这个 Tomcat 容器的时候,去挂这个 Volume,一定能在里面找到前面拷贝来的 sample.war。
所以可以这样去描述:这个 Pod 就是一个自包含的,可以把这一个 Pod 在全世界任何一个 Kubernetes 上面都顺利启用起来。不用担心没有分布式存储、Volume 不是持久化的,它一定是可以公布的。
所以这是一个通过组合两个不同角色的容器,并且按照一些像 Init Container 的编排方式,统一去打包这样一个应用,把它用 Pod 来去做的非常典型的一个例子。像这样的一个概念,在 Kubernetes 里面就是一个非常经典的容器设计模式,叫做:“Sidecar”。
什么是 Sidecar?就是说其实在 Pod 里面,可以定义一些专门的容器,来执行主业务容器所需要的一些辅助工作,比如我们前面举的例子,其实就干了一个事儿,这个 Init Container,它就是一个 Sidecar,它只负责把镜像里的 WAR 包拷贝到共享目录里面,以便被 Tomcat 能够用起来。
其它有哪些操作呢?比如说:
原本需要在容器里面执行 SSH 需要干的一些事情,可以写脚本、一些前置的条件,其实都可以通过像 Init Container 或者另外像 Sidecar 的方式去解决;
当然还有一个典型例子就是我的日志收集,日志收集本身是一个进程,是一个小容器,那么就可以把它打包进 Pod 里面去做这个收集工作;
还有一个非常重要的东西就是 Debug 应用,实际上现在 Debug 整个应用都可以在应用 Pod 里面再次定义一个额外的小的 Container,它可以去 exec 应用 pod 的 namespace;
这种做法一个非常明显的优势就是在于其实将辅助功能从我的业务容器解耦了,所以我就能够独立发布 Sidecar 容器,并且更重要的是这个能力是可以重用的,即同样的一个监控 Sidecar 或者日志 Sidecar,可以被全公司的人共用的。这就是设计模式的一个威力。

接下来,我们再详细细化一下 Sidecar 这样一个模式,它还有一些其他的场景。
比如说前面提到的应用日志收集,业务容器将日志写在一个 Volume 里面,而由于 Volume 在 Pod 里面是被共享的,所以日志容器 —— 即 Sidecar 容器一定可以通过共享该 Volume,直接把日志文件读出来,然后存到远程存储里面,或者转发到另外一个例子。现在业界常用的 Fluentd 日志进程或日志组件,基本上都是这样的工作方式。

Sidecar 的第二个用法,可以称作为代理容器 Proxy。什么叫做代理容器呢?
假如现在有个 Pod 需要访问一个外部系统,或者一些外部服务,但是这些外部系统是一个集群,那么这个时候如何通过一个统一的、简单的方式,用一个 IP 地址,就把这些集群都访问到?有一种方法就是:修改代码。因为代码里记录了这些集群的地址;另外还有一种解耦的方法,即通过 Sidecar 代理容器。
简单说,单独写一个这么小的 Proxy,用来处理对接外部的服务集群,它对外暴露出来只有一个 IP 地址就可以了。所以接下来,业务容器主要访问 Proxy,然后由 Proxy 去连接这些服务集群,这里的关键在于 Pod 里面多个容器是通过 localhost 直接通信的,因为它们同属于一个 network Namespace,网络视图都一样,所以它们俩通信 localhost,并没有性能损耗。
所以说代理容器除了做了解耦之外,并不会降低性能,更重要的是,像这样一个代理容器的代码就又可以被全公司重用了。

Sidecar 的第三个设计模式 —— 适配器容器 Adapter,什么叫 Adapter 呢?
现在业务暴露出来的 API,比如说有个 API 的一个格式是 A,但是现在有一个外部系统要去访问我的业务容器,它只知道的一种格式是 API B ,所以要做一个工作,就是把业务容器怎么想办法改掉,要去改业务代码。但实际上,你可以通过一个 Adapter 帮你来做这层转换。
有个例子:现在业务容器暴露出来的监控接口是 /metrics,访问这个容器的 metrics 的 URL 就可以拿到了。可是现在,这个监控系统升级了,它访问的 URL 是 /health,我只认得暴露出 health 健康检查的 URL,才能去做监控,metrics 不认识。那这个怎么办?那就需要改代码了,但可以不去改代码,额外写一个 Adapter,用来把所有对 health 的这个请求转发给 metrics 就可以了,所以这个 Adapter 对外暴露的是 health 这样一个监控的 URL,这就可以了,你的业务就又可以工作了。
这样的关键,还在于 Pod 之中的容器是通过 localhost 直接通信的,所以没有性能损耗,并且这样一个 Adapter 容器可以被全公司重用起来,这些都是设计模式给我们带来的好处。
Pod 与容器设计模式是 Kubernetes 体系里面最重要的一个基础知识点,希望读者能够仔细揣摩和掌握。在这里,我建议你去重新审视一下之前自己公司或者团队里使用 Pod 方式,是不是或多或少采用了所谓“富容器”这种设计呢?这种设计,只是一种过渡形态,会培养出很多非常不好的运维习惯。我强烈建议你逐渐采用容器设计模式的思想,对富容器进行解耦,将它们拆分成多个容器组成一个 Pod。这也正是当前阿里巴巴“全面上云”战役中正在全力推进的一项重要的工作内容。
“ 阿里巴巴云原生微信公众号(ID:Alicloudnative)关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术公众号。”
标签:思考 分布式 network 回滚机制 很多 作者 帮助 问题: 乐观锁
原文地址:https://blog.51cto.com/13778063/2439417