标签:int image host hadoop namenode orm rmi color tor
1.root账号先在namenode节点上配置一个定时任务,将fsimage定时传到其他客户机上进行操作
whereis hadoop命令确定安装目录,然后去配置文件找到namenode节点(data-93 emr-header-1)
0 1 * * * sh /root/fsimage.sh 每晚一点将fsimage文件发送到集群其他机器上,fsimage.sh如下
#!/bin/bash TARGET_HOST=192.168.11.130 SCP_PORT=58422 IMAGE_DIR=/mnt/disk1/hdfs/name/current TARGET_DIR=/data/hdfs DAY=`date +%Y%m%d` echo "day=$DAY" cd $IMAGE_DIR fsname=`ls fsimage* | head -1` echo $fsname scp -P $SCP_PORT $fsname ${TARGET_HOST}:${TARGET_DIR}/fsimage.${DAY} echo "done"
脚本在/mnt/disk1/hdfs/name/current下执行【scp -P 58422 fsimage_0000000007741688997 192.168.11.130:/data/hdfs/fsimage.20190920】,将namenode上的fsimage镜像文件传递到data130(192.168.11.130)上的文件夹里
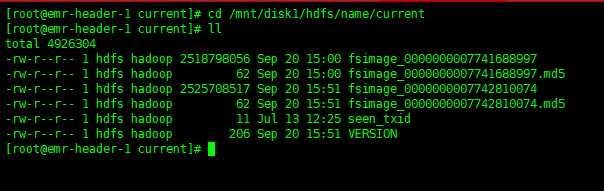
2.切换账号gobblin,在data-130的机子上配置crontab 任务,每天2点执行分析脚本
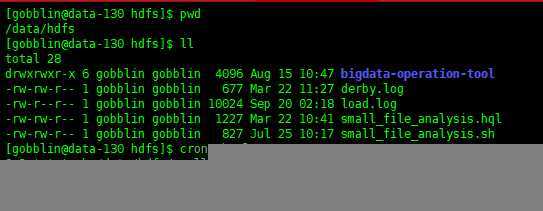
small_file_analysis.sh如下
#!/bin/bash source /etc/profile basepath=$(cd `dirname $0`; pwd) cd $basepath IMAGE_DIR="/data/hdfs" IMAGE_PREFIX="fsimage" # 0. 解析日期 cur_date="`date +%Y%m%d`" cur_month="`date +%Y%m`" cur_day="`date +%d`" echo "cur month = $cur_month" echo "cur day = $cur_day" echo "cur date = $cur_date" IMAGE_NAME=$IMAGE_PREFIX.$cur_date echo "fsimage name is $IMAGE_NAME" # 1. 解析 fsimage 镜像文件,生成txt 文件 export HADOOP_HEAPSIZE=10240 hdfs oiv -i $IMAGE_NAME -o $IMAGE_NAME.txt -p Delimited # 2. 将 txt 文件load进 hive 表中 hive -e "load data local inpath ‘$IMAGE_DIR/$IMAGE_NAME.txt‘ overwrite into table dataplatform.fsimage partition (month=‘$cur_month‘,day=‘$cur_day‘);" # 3. sql hive -hivevar CUR_MONTH=$cur_month -hivevar CUR_DAY=$cur_day -f small_file_analysis.hql rm -f fsimage* echo "done"
脚本逻辑很简单:使用image分析工具iov将image转为txt格式的文件,然后将文件导入hive 表(dataplatform.fsimage),再通过hive命令执行sql,将sql查询结果插入分析结果表(dataplatform.small_file_report_day),最后删除fsimage开头的2个文件即可
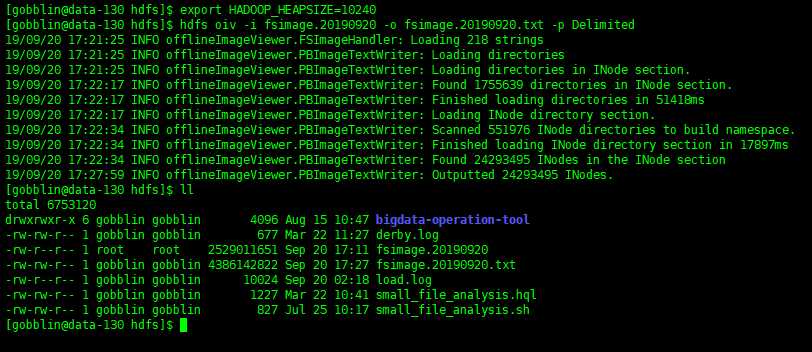
注意:export HADOOP_HEAPSIZE=10240 要加上,不然会报堆内存溢出
设置堆内存大小之后执行:
small_file_analysis.hql 如下:
set mapreduce.job.queuename=root.production.gobblin; set mapreduce.job.name=small_file_analysis; set hive.exec.parallel=true; set hive.exec.parallel.thread.number=4; set mapreduce.map.memory.mb=1024; set mapreduce.reduce.memory.mb=1024; INSERT OVERWRITE TABLE dataplatform.small_file_report_day PARTITION (month=‘${CUR_MONTH}‘, day=‘${CUR_DAY}‘) SELECT b.path as path, b.total_num as total_num FROM ( SELECT path, total_num, root_path FROM ( SELECT SUBSTRING_INDEX(path, ‘/‘, 4) AS path, COUNT(1) AS total_num, SUBSTRING_INDEX(path, ‘/‘, 2) AS root_path FROM dataplatform.fsimage WHERE file_size < 1048576 AND month=‘${CUR_MONTH}‘ AND day=‘${CUR_DAY}‘ AND SUBSTRING_INDEX(path, ‘/‘, 2) in (‘/warehouse‘, ‘/tmp‘) GROUP BY SUBSTRING_INDEX(path, ‘/‘, 4),SUBSTRING_INDEX(path, ‘/‘, 2) UNION SELECT SUBSTRING_INDEX(path, ‘/‘, 5) AS path, COUNT(1) as total_num, SUBSTRING_INDEX(path, ‘/‘, 3) AS root_path FROM dataplatform.fsimage WHERE file_size < 1048576 AND month=‘${CUR_MONTH}‘ AND day=‘${CUR_DAY}‘ AND SUBSTRING_INDEX(path, ‘/‘, 3) = ‘/gobblin/source‘ GROUP BY SUBSTRING_INDEX(path, ‘/‘, 5),SUBSTRING_INDEX(path, ‘/‘, 3) ) a
dataplatform.fsimage建表语句
CREATE TABLE `fsimage`( `path` string, `block_num` int, `create_time` string, `update_time` string, `block_size` bigint, `unknown1` int, `file_size` bigint, `unknown2` int, `unknown3` int, `permission` string, `user` string, `group` string) PARTITIONED BY ( `month` string, `day` string) ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe‘ WITH SERDEPROPERTIES ( ‘field.delim‘=‘\t‘, ‘serialization.format‘=‘\t‘) STORED AS INPUTFORMAT ‘org.apache.hadoop.mapred.TextInputFormat‘ OUTPUTFORMAT ‘org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat‘ LOCATION ‘hdfs://emr-cluster/warehouse/dataplatform.db/fsimage‘
dataplatform.small_file_report_day建表语句:
CREATE TABLE `dataplatform.small_file_report_day`( `path` string, `total_num` bigint) PARTITIONED BY ( `month` string, `day` string) ROW FORMAT SERDE ‘org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe‘ STORED AS INPUTFORMAT ‘org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat‘ OUTPUTFORMAT ‘org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat‘ LOCATION ‘hdfs://emr-cluster/warehouse/dataplatform.db/small_file_report_day‘ TBLPROPERTIES ‘parquet.compression‘=‘SNAPPY‘
【大数据】SmallFile-Analysis-Script
标签:int image host hadoop namenode orm rmi color tor
原文地址:https://www.cnblogs.com/dflmg/p/11558726.html