标签:服务 bsp led client vat 存储 案例 top 定义
最近使用Kafka做消息队列时,完成了基本的消息发送与接收,已上线运行。一方面防止出现Bug时自己不能及时定位问题,一方面网上的配置可能还可以更加优化,决定去了解下Kafka。
kafka基本配合zookeeper使用,网上有很多关于liunx上搭建zookeeper+kafka集群的实例,此处不再阐述。贴一个我以前搭建过的实例。https://blog.csdn.net/hudyang/article/details/80419214
个人理解:kafka是一个消息中间件,用于各个系统中消息的传递。例如:A系统是平台主入口,每天产生大量日志,A系统不可能自己去处理这些冗杂的事务,于是发送给Kafka。B系统很空闲,让他来接收Kafka数据,于是从kafka取数据,然后记录日志;在举个例子,在微服务中,A系统是用户模块,B系统是权限模块。创建用户时也要创建用户权限。于是在A系统在创建用户时,向kafka中发送一条指定消息,B系统收到这条消息后,于是开始创建用户权限。是不是很好理解-----
总结一句话:kafka是一个分布流媒体平台
流媒体平台有以下三个关键功能:
主题是Kafka最核心的抽象模块,用于连接生产者和消费者。生产者发送消息到指定的主题,消费者订阅该主题的消息,于是完成基本的消息传递流程。下面为kafka建立主题的code:
./kafka-topics.sh --create --zookeeper 10.113.56.68:2181 --replication-factor 1 --partitions 3 --topic testKafkas
// --zookeeper zookeeper集群地址
// --replication-factor 副本
// --parttitions 分区
// --topic 主题名称
分区的概念:分区是主题的横向拓展的实现。传统的消息队列相当于一个列表,生产者将消息放入列表中,然后消费者从列表中取出消息。吞吐量受到限制。如果使用多线程去取消息,就会造成异步操作,有可能出现数据消费混乱。Kafka中使用分区概念(相当于将一个大的队列分为成多个队列)每个分区由指定的消费者去消费,这样能极大的提高kafka的吞吐量,并且效率提高。
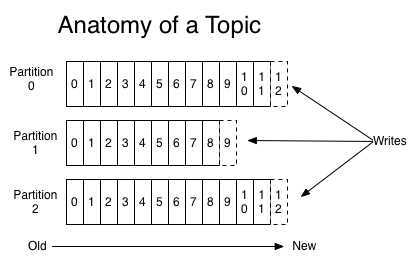
每个分区都是一个有序的,不可变的记录序列,不断附加到结构化的提交日志中。分区中的记录每个都被分配一个称为偏移的顺序ID号(offSet),它唯一地标识分区中的每个记录。如上图,一个topic的消息均匀分布在partition0,partition1,partition2中。消费者写3条消息到topic上,分别记录在partition0的offset12节点,partition1的offset9节点,partition2的offset12节点。消费者消费时,会从partition的offset0节点开始,消费完成后,offset+1,下次消费时,从上次的offset开始进行消费。
副本的概念:每个分区拥有多个副本,其中一个副本将被指定为主副本(leader replicas),其余的为跟随副本。所有的消息都会写入到主副本,所有的消息都从主要副本读取,其他的副本只需要保持于主副本同步即可。
消费组概念:消费组比较难理解。消费组相当于一个指定消费者的聚合。
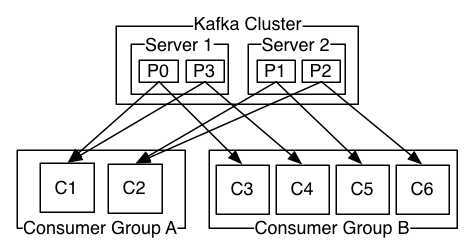
如图,KafkaCluster相当于一个topic,topic有4个分区 P0,P1,P2,P3;P0,P3在服务器1上,P1,P2在服务器2上(此处可以忽略他们在哪个服务器);有2个消费组ConsumerGroupA,ConsumerGroupB,里面有C1-C6消费者,每个消费者都订阅了topic的消息。上文提过,一个分区的消息只能被同一消费组下面的一个消费者消费。于是,对于ConsumerGroupA来说,C1接收P0,P3的消息,C2接收P1,P2的消息(为什么这么分配,下文会进行)。对于ConsumerGroupB来说,C3-C6分别接收P0-P3的消息。此处还有个小点,即消费组中的消费者数量不要大于分区数量。以ConsumerGroupB为例,消费者和分区刚好一一对应,如果此时增加了一个消费者C7,那么C7接受不到任何分区的消息,因为一个分区只能对应同个消费组下的一个消费者。
描述了Kafka基本概念后,此处介绍另一个概念Rebalance(即分区分配给消费组中指定消费者的过程)
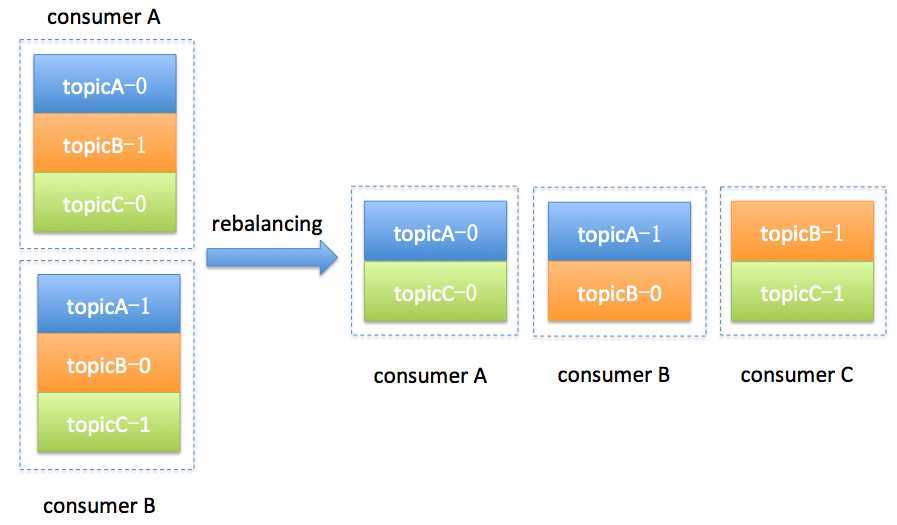
如上,消费组中原来有2个consumer,consumerA对应主题A的0分区,主题B的1分区,主题C的0分区;consumerB对应主题A的1分区,主题B的0分区,主题C的1分区。此时,消费组新增一个consumerC,那么对应的分区就要相应的重新分配,这个过程就叫Rebalance。
什么时候发生Rebalance?
Rebalance引发的问题
Rebalance流程(简介)
自己理解:consumer申请加入组,向Coordinator发送JoinGroup请求,Coordinator从重多consumer选择一个Group Leader(领导)。领导用于指定分区方案,即那个分区非配给哪个消费者。制定完成后,把分区方案给Coordinator,Coordinator然后告诉所有消费者:你负责的分区是哪个。
自己用Kafka做了一个简易消息系统,完成基本的消息发送。
// 引入kafka相关jar包 <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>2.1.7.RELEASE</version> </dependency>
import org.apache.kafka.clients.consumer.CommitFailedException; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Arrays; import java.util.Properties; import java.util.concurrent.ExecutionException; import java.util.function.Consumer; /** * @Author xiabing5 * @Create 2019/8/1 19:34 * @Desc kafka工具类 **/ public class KafkaUtil { private static Producer<String, String> producer; private static KafkaConsumer<String, String> consumer; private static KafkaConsumer<String, String> consumer1; static { Properties producerProps = new Properties(); //必需的3个参数 producerProps.put("bootstrap.servers", "10.113.56.68:9093,10.113.56.68:9094,10.113.56.68:9092"); producerProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); producerProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); producer = new KafkaProducer<String, String>(producerProps); Properties consumerProps = new Properties(); consumerProps.put("bootstrap.servers", "10.113.56.68:9093,10.113.56.68:9094,10.113.56.68:9092"); consumerProps.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); consumerProps.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); consumerProps.put("group.id", "VoucherGroup"); //关闭自动提交offset consumerProps.put("enable.auto.commit", "false"); //此处开启2个消费者进行消费 consumer = new KafkaConsumer<String, String>(consumerProps); consumer1 = new KafkaConsumer<String, String>(consumerProps); } /** * @Author xiabing5 * @Create 2019/8/1 19:40 * @Desc 同步发送消息 topic 主题 value 消息内容 **/ public static void sendSync(String topic, String value) throws ExecutionException, InterruptedException { producer.send(new ProducerRecord<String, String>(topic, value)).get(); } public static void consume(Consumer<String> c) { // 订阅主题,可订阅多个主题 consumer.subscribe(Arrays.asList("testKafkas")); while (true) { ConsumerRecords<String, String> records = consumer.poll(10); for (ConsumerRecord<String, String> record : records) { System.out.println("A"+record); c.accept(record.value()); } try { //同步手动提交offset consumer.commitSync(); } catch (CommitFailedException e) { System.out.println("Kafka消费者提交offset失败"); } } } public static void consume1(Consumer<String> c) { // 订阅主题,可订阅多个主题 consumer1.subscribe(Arrays.asList("testKafkas")); while (true) { ConsumerRecords<String, String> records = consumer1.poll(10); for (ConsumerRecord<String, String> record : records) { System.out.println("A"+record); c.accept(record.value()); } try { //同步手动提交offset consumer1.commitSync(); } catch (CommitFailedException e) { System.out.println("Kafka消费者提交offset失败"); } } } }
// 发送消息接口 public interface MessageService { // 发送消息 boolean sendMessage(String topic,String content); }
@Service public class MessageServiceImpl implements MessageService { // 创建线程池 @PostConstruct public void init() { ThreadFactory threadFactory = new ThreadFactoryBuilder() .setNameFormat("MessageConsumerThread-%d") .setDaemon(true) .build(); //ExecutorService executorService = Executors.newSingleThreadExecutor(threadFactory); ExecutorService executorService = Executors.newFixedThreadPool(2,threadFactory); MqMessageConsumerThread mqMessageConsumerThread= new MqMessageConsumerThread(); MqMessageConsumerThread1 mqMessageConsumerThread1= new MqMessageConsumerThread1(); executorService.execute(mqMessageConsumerThread); executorService.execute(mqMessageConsumerThread1); } // 自定义接收线程 private class MqMessageConsumerThread implements Runnable { @Override public void run() { KafkaUtil.consume(consumerRecord -> { System.out.println("A"+consumerRecord); }); } } private class MqMessageConsumerThread1 implements Runnable { @Override public void run() { KafkaUtil.consume1(consumerRecord -> { System.out.println("B"+consumerRecord); }); } } @Override public boolean sendMessage(String topic, String content) { try { KafkaUtil.sendSync(topic,content); // 执行业务逻辑 System.out.println("发送kafka消息成功"); } catch (Exception e) { // 发送失败 System.out.println("发送kafka消息失败"); // 失败重发 try { KafkaUtil.sendSync(topic,content); }catch (Exception e1) { System.out.println("失败"); } } return true; } }
/** * @Author xiabing5 * @Create 2019/9/19 20:17 * @Desc 容器初始化(模拟消息发送) **/ @Component public class InitApplication implements CommandLineRunner{ @Autowired MessageService messageService; @Override public void run(String... strings) throws Exception { for (int i = 0; i < 10; i++) { messageService.sendMessage("testKafkas",i+""); } } }
启动容器,会出现如下界面

学习一项新技术,最好知道它实现的基本内涵,希望自己这个小白在每一次记录中成长;
本文纯原创,写的不好或理解不到位的地方请多多指教;
标签:服务 bsp led client vat 存储 案例 top 定义
原文地址:https://www.cnblogs.com/xiaobingblog/p/11562204.html