标签:ptime nbsp alc 平台 nas testing sssss wifi 网卡
具体硬件平台就不详细说了,浪费时间码字,贴一个淘宝上的配置:

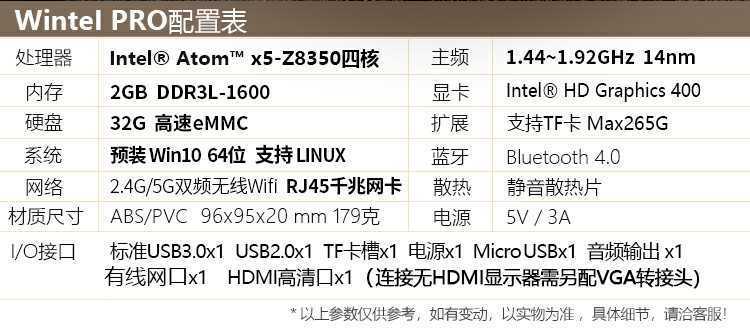
有点广告的既视感,哈哈,不过我200块咸鱼收的2手,配置比这个稍低,比如CPU是Z8300,网卡是百兆的,WIFI可能也不是双频的(这个不确定。
因为linux下这玩意没驱动起来)不过我买回来不是做NAS,只是想搞个7*24在线的小服务器,映射到外网做一点小服务。所以配置差点也无所谓的样子
先来个待机功耗图:

待机2.0瓦。不过这个是算上这个220V/5V 3A的效率的,因为电源的总功率是15W(5V/3A)而目标功率小于3W,所以也算是低负载运行,所以实际功耗
应该是小于2瓦的,不像直测USB电流,测出来就是实际功耗,所以在接下来的对比中,我树莓派也用一个5V 3A的充电头来带,尽量做到情景一致
(不过考虑到不同的充电头,效率也不一样,所以还是不算严谨对比)先来个screenfetch。
-` .o+` yafeng@archlinux `ooo/ OS: Arch Linux `+oooo: Kernel: x86_64 Linux 5.3.0-arch1-1-ARCH `+oooooo: Uptime: 1h 5m -+oooooo+: Packages: 188 `/:-:++oooo+: Shell: bash 5.0.9 `/++++/+++++++: CPU: Intel Atom x5-Z8300 @ 4x 1.84GHz [40.2°C] `/++++++++++++++: GPU: `/+++ooooooooooooo/` RAM: 88MiB / 1862MiB ./ooosssso++osssssso+` .oossssso-````/ossssss+` -osssssso. :ssssssso. :osssssss/ osssso+++. /ossssssss/ +ssssooo/- `/ossssso+/:- -:/+osssso+- `+sso+:-` `.-/+oso: `++:. `-/+/ .` `/
算了,不说废话了,先记下现在测试过的结果:
空载 2.0W-2.1W,还算稳定
跑满单核(我自己写的单核计算圆周率的benchmark) 3.2W
跑满四核(同上),4.9W
Python递归算法计算斐波那契数列的40位:3.9W
测试成绩如下:
::Testing gcc installed ::>GCC installed ::===Benchmarking C=== ::Compling pi.c.. ::>Complie time:0.3423449993133545 ::>Calc time:111.01979780197144 ::Wait 10 seconds ::===Benchmarking GMP=== ::Compling gmpi.cpp.. ::>Complie time:2.5547237396240234 ::>Calc time:22.081634759902954 ::Wait 10 seconds ::===Benchmarking mtGMPi Mutithread=== ::Compling mtgmpi.c.. ::>Complie time:0.3653872013092041 ::Number of Thread: 4 ::>Calc time:65.04465556144714
嗯,记住时间就行,三个测试分别是111秒,22秒,65秒
最为比较,i7-4790K这三个成绩分别是:36.751,4.675,6.534
计算40位斐波那契数时间为:
[yafeng@archlinux fibn]$ python fib.py 102334155 151.38735151290894
比起台式机简直弱爆了哈哈。
树莓派3B,用的另外一个5V 3AUSB供电,测得空载功耗2.2W
python递归计算斐波那契数列,功耗3.4W
单线程计算圆周率: 3.4W
多线程计算圆周率:4.5-4.7W,不稳定,也有时候会蹦到4.0
[alarm@alarmpi pimark]$ python test.py ::Testing gcc installed ::>GCC installed ::===Benchmarking C=== ::Compling pi.c.. ::>Complie time:0.5492968559265137 ::>Calc time:106.87575554847717 ::Wait 10 seconds ::===Benchmarking GMP=== ::Compling gmpi.cpp.. ::>Complie time:3.184544086456299 ::>Calc time:26.894031286239624 ::Wait 10 seconds ::===Benchmarking mtGMPi Mutithread=== ::Compling mtgmpi.c.. ::>Complie time:0.5404598712921143 ::Number of Thread: 4 ::>Calc time:96.08412599563599
python递归速度有点让我不相信自己的眼睛了:
[alarm@alarmpi fibn]$ python fib.py 102334155 554.3715827465057
最终对比如下:
单线程满载,111秒 vs 106秒 3.2瓦 vs 3.4瓦 性能差距5% 树莓派小胜
多线程满载,65秒 VS 96秒 4.9瓦 vs 4.6瓦 性能差距47%,Z8300胜
python递归计算斐波那契数列: 151秒 vs 554秒 3.9瓦 vs 3.4瓦 性能差距367%,Z8300大胜
另外那个GMP单线程计算圆周率的结果是22秒 vs 26秒,Z8300 胜20%,
这里说明一下:第一个计算pi的程序,是用数组来做大数计算的,纯C语言编写。而后边俩都是用GMP大数库来做运算的,可以看作是GMP针对平台各自做一定的优化。
另外,树莓派的系统是32位系统,而Z8300系统为64位,也可能是有些项目差距过大的原因,后续我会再在树莓派64位系统做测试,看看是不是这个原因。
intel Z8300 2G 32G小主机跟树莓派3B的功耗/性能对比
标签:ptime nbsp alc 平台 nas testing sssss wifi 网卡
原文地址:https://www.cnblogs.com/yafengabc/p/11562232.html