标签:ofo load 怎么 模式 分而治之 not 自己 sar 概述
大数据是新处理模式才能具备更多的决策力,洞察力,流程优化能力,来适应海量高增长率,多样化的数据资产。
由来?
根据google发布的3篇文章
google File System
Google MapReduce 获得启发 hadoop之父 Doug Cutting 用java语言解决大数据所面临的问题
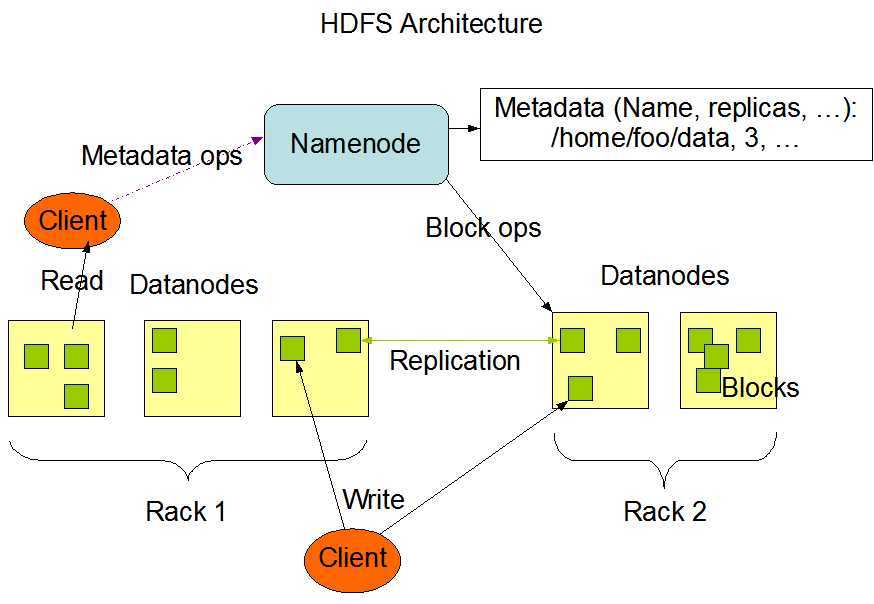

fsimage 元数据的备份 会被加载到内存当中去
edits 读写请求的日志文件
nameNode 会在启动的时候加载 fsimage 和 edits ,这2个文件不会凭空出现,所以要格式化nameNode
当用户在操作文件时,由于edits的增加,导致了nameNode启动会越来越慢,所以就出现了SecondaryNameNode 可以简单来说,他是nameNode的一个副本,当到达检查点的时候,也就是hdfs 默认 1个小时 或者 日志操作量级达到100w条的时候,此时SecondaryNameNode会将fsimage和edits加载过来进行合并,此时,若是有读写请求过来的时候会被加载到一个叫edits-inprogess的文件进行记录读写请求,fsimage和edits合并之后会成为一个新的fsimage,而此时edits-inprogess会改名为edits
标签:ofo load 怎么 模式 分而治之 not 自己 sar 概述
原文地址:https://www.cnblogs.com/blogs-gxData/p/11562807.html