标签:系统 ted 相关 业务开发 inf 特性 发展 HERE 架构
一.大数据的特点
大数据是什么?其实很简单,大数据其实就是海量资料巨量资料,这些巨量资料来源于世界各地随时产生的数据,在大数据时代,任何微小的数据都可能产生不可思议的价值。大数据有4个特点,为别为:Volume(大量)、Variety(多样)、Velocity(高速)、Value(价值),一般我们称之为4V。
所谓4V,具体指如下4点:
1.大量。大数据的特征首先就体现为“大”,从先Map3时代,一个小小的MB级别的Map3就可以满足很多人的需求,然而随着时间的推移,存储单位从过去的GB到TB,乃至现在的PB、EB级别。随着信息技术的高速发展,数据开始爆发性增长。社交网络(微博、推特、脸书)、移动网络、各种智能工具,服务工具等,都成为数据的来源。淘宝网近4亿的会员每天产生的商品交易数据约20TB;脸书约10亿的用户每天产生的日志数据超过300TB。迫切需要智能的算法、强大的数据处理平台和新的数据处理技术,来统计、分析、预测和实时处理如此大规模的数据。
2.多样。广泛的数据来源,决定了大数据形式的多样性。任何形式的数据都可以产生作用,目前应用最广泛的就是推荐系统,如淘宝,网易云音乐、今日头条等,这些平台都会通过对用户的日志数据进行分析,从而进一步推荐用户喜欢的东西。日志数据是结构化明显的数据,还有一些数据结构化不明显,例如图片、音频、视频等,这些数据因果关系弱,就需要人工对其进行标注。
3.高速。大数据的产生非常迅速,主要通过互联网传输。生活中每个人都离不开互联网,也就是说每天个人每天都在向大数据提供大量的资料。并且这些数据是需要及时处理的,因为花费大量资本去存储作用较小的历史数据是非常不划算的,对于一个平台而言,也许保存的数据只有过去几天或者一个月之内,再远的数据就要及时清理,不然代价太大。基于这种情况,大数据对处理速度有非常严格的要求,服务器中大量的资源都用于处理和计算数据,很多平台都需要做到实时分析。数据无时无刻不在产生,谁的速度更快,谁就有优势。
4.价值。这也是大数据的核心特征。现实世界所产生的数据中,有价值的数据所占比例很小。相比于传统的小数据,大数据最大的价值在于通过从大量不相关的各种类型的数据中,挖掘出对未来趋势与模式预测分析有价值的数据,并通过机器学习方法、人工智能方法或数据挖掘方法深度分析,发现新规律和新知识,并运用于农业、金融、医疗等各个领域,从而最终达到改善社会治理、提高生产效率、推进科学研究的效果
二. 大数据关键技术的不同层面及其功能
数据采集
利用ETL工具将分布的、异构数据源中的数据抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础;也可以把实时采集的数据作为流计算系统的输入,进行实时处理分析。
数据存储和管理
利用分布式文件系统、数据仓库、关系数据库、NoSQL数据库、云数据库等实现对结构化、半结构化和非结构化海量数据的存储和管理。
数据处理与分析
利用分布式并行编程模型和计算框架,结合机器学习和数据挖掘算法,实现对海量数据的处理和分析;对分析结果进行可视化呈现,帮助人们更好地理解、分析数据。
数据安全和隐私保护
构建隐私保护体系和数据安全体系,保护个人隐私和数据安全。
三。大数据计算模式
批处理计算
针对大规模数据的批量处理。
MapReduce可以并行执行大规模数据处理任务,用于大规模数据集的并行运算(单输入、两阶段、粗粒度数据并行的分布式框架)。它将复杂的、运行于大规模集群上的并行计算过程高度抽象到了两个函数——Map和Reduce,并把一个大数据集切分成多个小数据集,分布到不同的机器上进行并行处理,极大地方便了分布式编程工作。在MapReduce中,数据流从一个稳定的来源,进行一系列加工处理后,流出到一个稳定的文件系统(如HDFS)。
Spark是一个针对超大数据集合的低延迟的集群分布式计算系统。它启用了内存分布数据集,可以提供交互式查询、优化迭代工作负载。在MapReduce中,数据流从一个稳定的来源,进行一系列加工处理后,流出到一个稳定的文件系统(如HDFS)。而Spark则用内存替代HDFS或本地磁盘来存储中间结果,因此要快很多。
流计算
流数据(或数据流)是指在时间分布和数量上无限的一系列动态数据集合体,数据的价值随着时间的流逝而降低,因此必须实时计算给出秒级响应。业内有许多流计算框架与平台:第一类,商业级流计算平台(IBM InfoSphere Streams、IBM StreamBase等);第二类,开源流计算框架(Twitter Storm、S4等);第三类,公司为支持自身业务开发的流计算框架。
图计算
适合用于大型图的计算。Pregel等
查询分析计算
针对超大规模数据的存储管理和查询分析,需要提供实时或准实时响应。如Dremel、Impala等
四。Hadoop简介
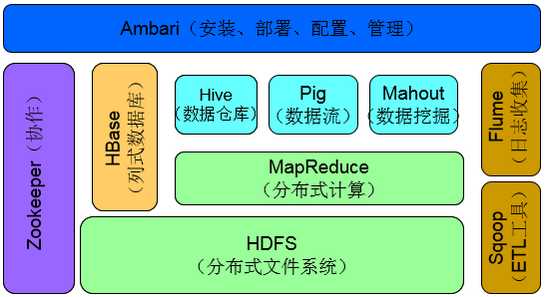
六。hadoop生态系统
标签:系统 ted 相关 业务开发 inf 特性 发展 HERE 架构
原文地址:https://www.cnblogs.com/tangqing/p/11564905.html