标签:约束 mes 最大 style 初始 变量 分类 span 距离
卡方检验主要用于分类变量之间的独立性检验
基本思想:卡方表示观察值与理论值之间的偏离程度。
设A代表某个类别的观察频数,E代表基于H0计算出的期望频数,A与E之差称为残差,卡方值计算公式:
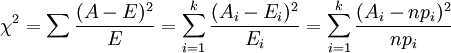
Ai为i水平的观察频数,Ei为i水平的期望频数,n为总频数,pi为i水平的期望频率。i水平的期望频数Ei等于总频数n×i水平的期望概率pi,k为单元格数。当n比较大时,χ2统计量近似服从k-1(计算Ei时用到的参数个数)个自由度的卡方分布。
由卡方的计算公式可知,当观察频数与期望频数完全一致时,χ2值为0;观察频数与期望频数越接近,两者之间的差异越小,χ2值越小;反之,观察频数与期望频数差别越大,两者之间的差异越大,χ2值越大。换言之,大的χ2值表明观察频数远离期望频数,即表明远离假设。小的χ2值表明观察频数接近期望频数,接近假设。因此,χ2是观察频数与期望频数之间距离的一种度量指标,也是假设成立与否的度量指标。如果χ2值“小”,研究者就倾向于不拒绝H0;如果χ2值大,就倾向于拒绝H0。至于χ2在每个具体研究中究竟要大到什么程度才能拒绝H0,则要借助于卡方分布求出所对应的P值来确定。
卡方检验实例:
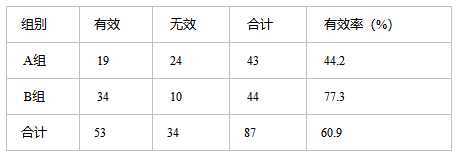
某医院对某种病症的患者使用了A,B两种不同的疗法,结果如表1,问两种疗法有无差别?
可以计算出各格内的期望频数:
第1行1列: 43×53/87=26.2
第1行2列: 43×34/87=16.8
第2行1列: 44×53/87=26.8
第2行2列: 44×34/87=17.2
先建立原假设:A、B两种疗法没有区别。根据卡方值的计算公式,计算:卡方值=10.01。得到卡方值以后,接下来需要查询卡方分布表来判断p值,从而做出接受或拒绝原假设的决定。自由度k=(行数-1)*(列数-1)。 这里k=1.然后看卡方分布的临界概率表,我们可以用如下代码生成:
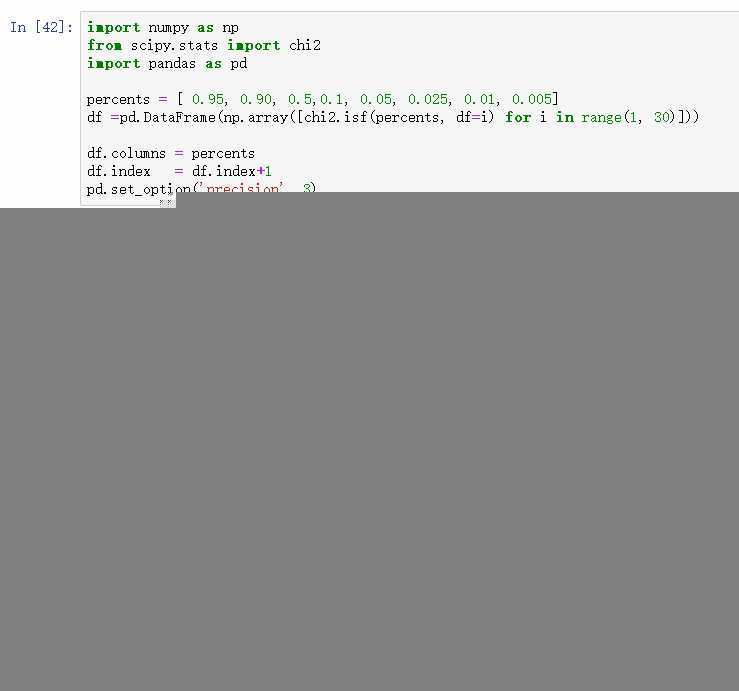
查表自由度为1,p=0.05的卡方值为3.841,而此例卡方值10.01>3.841,因此 p < 0.05,说明原假设在0.05的显著性水平下是可以拒绝的。也就是说,原假设不成立。
ChiMerge分箱算法:
它主要包括两个阶段:初始化阶段和自底向上的合并阶段。
初始化阶段:
首先按照属性值的大小进行排序(对于非连续特征,需要先做数值转换,比如转为坏人率,然后排序),然后每个属性值单独作为一组。
合并的阶段:
(1)对每一对相邻的组,计算卡方值;
(2)根据计算的卡方值,对其中最小的一对邻组合并为一组;
(3)不断重复(1),(2)直到计算出的卡方值都不低于事先设定的阈值,或者分组数达到一定的条件(如最小分组数5,最大分组数8)。
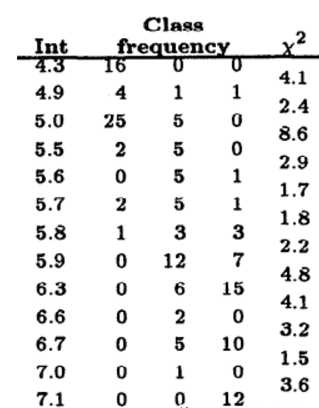
下图是著名的鸢尾花数据集sepal-length属性值的分组及相邻组的卡方值。最左侧是属性值,中间3列是class的频数,最右是卡方值。这个分箱是以卡方阈值1.4的结果。可以看出,最小的组为[6.7,7.0),它的卡方值是1.5。
如果进一步提高阈值,如设置为4.6,那么以上分箱还将继续合并,最终的分箱如下图:

卡方分箱除了用阈值来做约束条件,还可以进一步的加入分箱数约束,以及最小箱占比,坏人率约束等。
标签:约束 mes 最大 style 初始 变量 分类 span 距离
原文地址:https://www.cnblogs.com/linkmust/p/11565862.html