标签:分布 次数 输入 img 技术 输出 多层 权重 缩放
深度神经网络难训练一个重要的原因就是深度神经网络涉及很多层的叠加,每一层的参数变化都会导致下一层输入数据分布的变化,随着层数的增加,高层输入数据分布变化会非常剧烈,这就使得高层需要不断适应低层的参数更新。为了训练好模型,我们需要谨慎初始化网络权重,调整学习率等。
为了解决这个问题,一个比较直接的想法就是对每层输入数据都进行标准化。Batch Normalization确实就是这样做的。Batch Normalization的基本思想就是:将每一批次数据输入下一层神经元之前,先对其做平移和伸缩变换,将输入数据的分布规范为固定区间范围内的标准分布。Batch Normalization的公式表示如下:
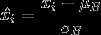
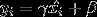
这时我们可能会有些疑问,第一步不是已经得到标准化分布了吗,为什么还要再使用第二步变回去呢?
答案是:为了保证模型的表达能力,第二步是必不可少的。
我们发现,第一步将每一层的输入数据都规范化为均值为0,标准差为1的分布。那么我们仔细想一下,这样做会带来什么问题?
每一层神经元都在不断的学习,但是无论其如何努力(参数如何变化),其输出的结果在交给下一层神经元之前都会被强制规范化到均值为0,标准差为1的分布。那我们还学个鬼啊!这样训练出来的神经网络模型表达能力自然很差。
所以,我们需要使用第二步将规范化后的数据再平移缩放到均值为$\beta $,标准差为$\gamma $的分布,充分考虑每一层神经元的学习结果。当然,这两个参数是可学习的,每一层的和会有所不同。
训练快,还能提升性能,为啥不用。TensorFlow、Keras和Pytorch都集成了Batch Normalization的函数,可直接调用。
标签:分布 次数 输入 img 技术 输出 多层 权重 缩放
原文地址:https://www.cnblogs.com/LXP-Never/p/11566064.html