感觉分数除以人数非常不合理,怎么可能多一个人就能线性地提高产出的成果呢,其实一个做出来的效果也不会比三个人做的差多少,希望能换成log或者同样的项目,别人拿10分,我们8,9分这样。
标签:组织 tab 数据 反馈 log inf demo src 方法
黄金点游戏源于经济学家Richar Thaler构思的在1997年伦敦金融时报进行了一次公开竞猜活动,该游戏有着一些很有意思的性质,因此老师将其作为第一次结对编程的题目。
在黄金点游戏中,假设有N个玩家,游戏规则为,每人写一个或两个0~100之间的有理数 (不包括0或100),提交给服务器,服务器在当前回合结束时算出所有数字的平均值,然后乘以0.618(所谓黄金分割常数),得到G值。提交的数字最靠近G(取绝对值)的玩家得到N分,离G最远的玩家得到-2分,其他玩家得0分。只有一个玩家参与时不得分。
核心算法我们采用了q learning,一是因为时间紧张,而且都身在国外,二是该任务的数据较少而在线反馈又有限且缓慢,如果想通过复杂的模型训出效果较好的模型需要花费大量的时间来进行比赛收集数据,因为还未入职,也就没有和其他同学相约比赛,于是我们就采用了未采用neural network的q learning方法,既简洁又防止因为数据稀疏而欠拟合。
q learning简而言之就是用一张q table来记录不同state下的不同action的价值,然后通过从环境中收集得到的相应动作的reward来更新q表。
具体算法如下:

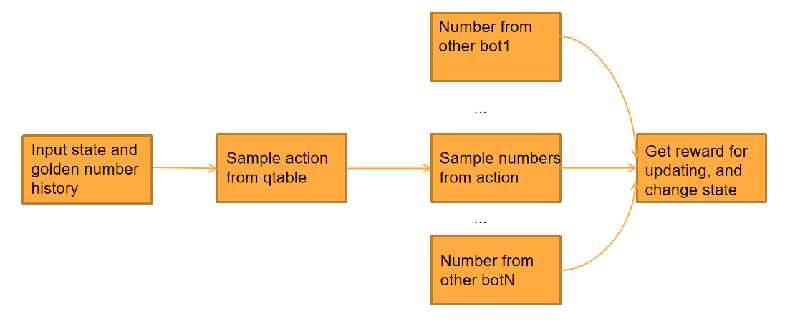
因为该任务没有label,所以我们很自然地采取了强化学习,因为我们的模型没有什么参数,所以最重要的就是如何设计action以及如何学到一个比较好的action distribution。
前者本次我们主要基于demo中给的8个action进行改进,首先我们更改了数值的大小和范围,因为原始action中的设计很不合理,之后我们发现最后黄金点会收敛到比较小的一个范围,因此我们设计了在各种不同的范围进行随机采样的方法,可以防止action产生的数值有较大的偏差。
后者因为只有半天时间,没时间训练,因此我们尝试拿到其他bot的预测数值,可以通过一次比赛,生成多组数据,来弥补时间和数据不足的问题。
第一次比赛结果是第6名,我们主要根据黄金点变化图,改了各个action的数值采样范围和大小,并且新加了几个混合几个action的新的动作,在第二次比赛中取得了第4名,相对于投入的时间来说已经可以接受了,成绩的上升一是来自于我们的改进,二可能是其他同学在匆忙改进,对结果起到了反效果。
1. 黄金点比赛的结果符合你们的预期吗?
第一轮游戏的结果不是很符合预期,后来我们改进了一下action,有了一定的提升,不过成绩不是很理想,有三方面原因:1. 训练迭代次数不足。2.模型表示能力不足。3.action的设计仍有待提高。
2. 在正式的比赛前,你们采取了怎样的策略来评价模型的好坏?
在room1和room0选一定时间查看获得的分数,因为没有入职的原因,没有找同学进行比赛。
3. 如果将每轮可提交的数字变成 3个,或者找更多的参赛者来参加比赛,你们的方法还适用吗?
设计思路是适用的,但是具体的方法也就是action的选取需要一些改变,可以进行扰动的思路和方法会变得更多。
4. 请评价合作伙伴的工作,评价方式请参考书中关于三明治方法的论述。并提出结对伙伴可以改进的地方。
我的合作伙伴是吴紫薇和吴雪晴,队友都太强了。
吴雪晴的代码能力和组织能力都很强,大家都很忙,但她还是很快地做出了demo,并写了很多改进。
吴紫薇能很好地根据已有地结果提出高效的改进,并指出比较有希望的方向,当然代码能力也非常强。
我觉得我们的结果一般问题主要还是时间上的紧张,而且都在不同的地方,有的人刚回国在倒时差,有的人在飞机上,有的人还在美国,并且我们都没有入职,对一些要求不是很明了,也没有很多和其他同学老师讨论的机会。
5. 一些想法。
感觉分数除以人数非常不合理,怎么可能多一个人就能线性地提高产出的成果呢,其实一个做出来的效果也不会比三个人做的差多少,希望能换成log或者同样的项目,别人拿10分,我们8,9分这样。
标签:组织 tab 数据 反馈 log inf demo src 方法
原文地址:https://www.cnblogs.com/wtxwtx/p/11565891.html