标签:情况 官方 ogr 大小 width 包含 程序 char diff
工具类 就是封装平常用的方法,不需要你重复造轮子,节省开发人员时间,提高工作效率。谷歌作为大公司,当然会从日常的工作中提取中很多高效率的方法出来。所以就诞生了guava。
guava的优点:
Guava工程包含了若干被Google的 Java项目广泛依赖 的核心库,例如:
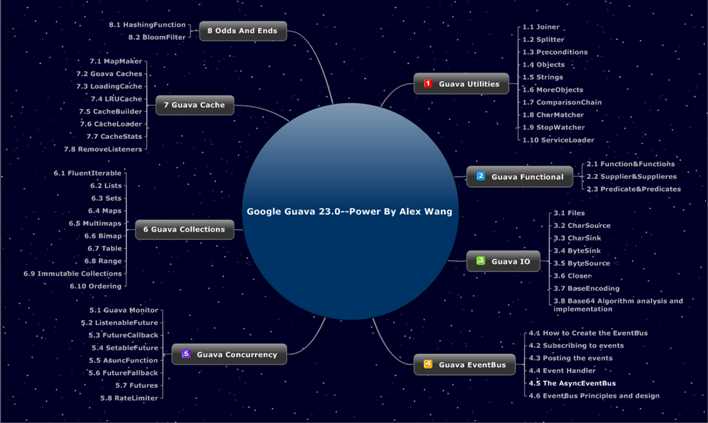
这里借用龙果学院深入浅出Guava课程的一张图
引入gradle依赖(引入Jar包)
compile ‘com.google.guava:guava:26.0-jre‘
复制代码// 普通Collection的创建
List<String> list = Lists.newArrayList();
Set<String> set = Sets.newHashSet();
Map<String, String> map = Maps.newHashMap();
// 不变Collection的创建
ImmutableList<String> iList = ImmutableList.of("a", "b", "c");
ImmutableSet<String> iSet = ImmutableSet.of("e1", "e2");
ImmutableMap<String, String> iMap = ImmutableMap.of("k1", "v1", "k2", "v2");
复制代码创建不可变集合 先理解什么是immutable(不可变)对象
ImmutableList<String> immutableList = ImmutableList.of("1","2","3","4");
复制代码这声明了一个不可变的List集合,List中有数据1,2,3,4。类中的 操作集合的方法(譬如add, set, sort, replace等)都被声明过期,并且抛出异常。 而没用guava之前是需要声明并且加各种包裹集合才能实现这个功能
// add 方法
@Deprecated @Override
public final void add(int index, E element) {
throw new UnsupportedOperationException();
}
复制代码当我们需要一个map中包含key为String类型,value为List类型的时候,以前我们是这样写的
Map<String,List<Integer>> map = new HashMap<String,List<Integer>>();
List<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
map.put("aa", list);
System.out.println(map.get("aa"));//[1, 2]
复制代码而现在
Multimap<String,Integer> map = ArrayListMultimap.create();
map.put("aa", 1);
map.put("aa", 2);
System.out.println(map.get("aa")); //[1, 2]
复制代码其他的黑科技集合
MultiSet: 无序+可重复 count()方法获取单词的次数 增强了可读性+操作简单
创建方式: Multiset<String> set = HashMultiset.create();
Multimap: key-value key可以重复
创建方式: Multimap<String, String> teachers = ArrayListMultimap.create();
BiMap: 双向Map(Bidirectional Map) 键与值都不能重复
创建方式: BiMap<String, String> biMap = HashBiMap.create();
Table: 双键的Map Map--> Table-->rowKey+columnKey+value //和sql中的联合主键有点像
创建方式: Table<String, String, Integer> tables = HashBasedTable.create();
...等等(guava中还有很多java里面没有给出的集合类型)
复制代码以前我们将list转换为特定规则的字符串是这样写的:
//use java
List<String> list = new ArrayList<String>();
list.add("aa");
list.add("bb");
list.add("cc");
String str = "";
for(int i=0; i<list.size(); i++){
str = str + "-" +list.get(i);
}
//str 为-aa-bb-cc
//use guava
List<String> list = new ArrayList<String>();
list.add("aa");
list.add("bb");
list.add("cc");
String result = Joiner.on("-").join(list);
//result为 aa-bb-cc
复制代码把map集合转换为特定规则的字符串
Map<String, Integer> map = Maps.newHashMap();
map.put("xiaoming", 12);
map.put("xiaohong",13);
String result = Joiner.on(",").withKeyValueSeparator("=").join(map);
// result为 xiaoming=12,xiaohong=13
复制代码//use java
List<String> list = new ArrayList<String>();
String a = "1-2-3-4-5-6";
String[] strs = a.split("-");
for(int i=0; i<strs.length; i++){
list.add(strs[i]);
}
//use guava
String str = "1-2-3-4-5-6";
List<String> list = Splitter.on("-").splitToList(str);
//list为 [1, 2, 3, 4, 5, 6]
复制代码如果
str="1-2-3-4- 5- 6 ";
复制代码guava还可以使用 omitEmptyStrings().trimResults() 去除空串与空格
String str = "1-2-3-4- 5- 6 ";
List<String> list = Splitter.on("-").omitEmptyStrings().trimResults().splitToList(str);
System.out.println(list);
复制代码将String转换为map
String str = "xiaoming=11,xiaohong=23";
Map<String,String> map = Splitter.on(",").withKeyValueSeparator("=").split(str);
复制代码String input = "aa.dd,,ff,,.";
List<String> result = Splitter.onPattern("[.|,]").omitEmptyStrings().splitToList(input);
复制代码关于字符串的操作 都是在Splitter这个类上进行的
// 判断匹配结果
boolean result = CharMatcher.inRange(‘a‘, ‘z‘).or(CharMatcher.inRange(‘A‘, ‘Z‘)).matches(‘K‘); //true
// 保留数字文本 CharMatcher.digit() 已过时 retain 保留
//String s1 = CharMatcher.digit().retainFrom("abc 123 efg"); //123
String s1 = CharMatcher.inRange(‘0‘, ‘9‘).retainFrom("abc 123 efg"); // 123
// 删除数字文本 remove 删除
// String s2 = CharMatcher.digit().removeFrom("abc 123 efg"); //abc efg
String s2 = CharMatcher.inRange(‘0‘, ‘9‘).removeFrom("abc 123 efg"); // abc efg
复制代码我们对于集合的过滤,思路就是迭代,然后再具体对每一个数判断,这样的代码放在程序中,难免会显得很臃肿,虽然功能都有,但是很不好看。
guava写法
//按照条件过滤
ImmutableList<String> names = ImmutableList.of("begin", "code", "Guava", "Java");
Iterable<String> fitered = Iterables.filter(names, Predicates.or(Predicates.equalTo("Guava"), Predicates.equalTo("Java")));
System.out.println(fitered); // [Guava, Java]
//自定义过滤条件 使用自定义回调方法对Map的每个Value进行操作
ImmutableMap<String, Integer> m = ImmutableMap.of("begin", 12, "code", 15);
// Function<F, T> F表示apply()方法input的类型,T表示apply()方法返回类型
Map<String, Integer> m2 = Maps.transformValues(m, new Function<Integer, Integer>() {
public Integer apply(Integer input) {
if(input>12){
return input;
}else{
return input+1;
}
}
});
System.out.println(m2); //{begin=13, code=15}
复制代码set的交集, 并集, 差集
HashSet setA = newHashSet(1, 2, 3, 4, 5);
HashSet setB = newHashSet(4, 5, 6, 7, 8);
SetView union = Sets.union(setA, setB);
System.out.println("union:");
for (Integer integer : union)
System.out.println(integer); //union 并集:12345867
SetView difference = Sets.difference(setA, setB);
System.out.println("difference:");
for (Integer integer : difference)
System.out.println(integer); //difference 差集:123
SetView intersection = Sets.intersection(setA, setB);
System.out.println("intersection:");
for (Integer integer : intersection)
System.out.println(integer); //intersection 交集:45
复制代码map的交集,并集,差集
HashMap<String, Integer> mapA = Maps.newHashMap();
mapA.put("a", 1);mapA.put("b", 2);mapA.put("c", 3);
HashMap<String, Integer> mapB = Maps.newHashMap();
mapB.put("b", 20);mapB.put("c", 3);mapB.put("d", 4);
MapDifference differenceMap = Maps.difference(mapA, mapB);
differenceMap.areEqual();
Map entriesDiffering = differenceMap.entriesDiffering();
Map entriesOnlyLeft = differenceMap.entriesOnlyOnLeft();
Map entriesOnlyRight = differenceMap.entriesOnlyOnRight();
Map entriesInCommon = differenceMap.entriesInCommon();
System.out.println(entriesDiffering); // {b=(2, 20)}
System.out.println(entriesOnlyLeft); // {a=1}
System.out.println(entriesOnlyRight); // {d=4}
System.out.println(entriesInCommon); // {c=3}
复制代码//use java
if(list!=null && list.size()>0)
‘‘‘
if(str!=null && str.length()>0)
‘‘‘
if(str !=null && !str.isEmpty())
//use guava
if(!Strings.isNullOrEmpty(str))
//use java
if (count <= 0) {
throw new IllegalArgumentException("must be positive: " + count);
}
//use guava
Preconditions.checkArgument(count > 0, "must be positive: %s", count);
复制代码免去了很多麻烦!并且会使你的代码看上去更好看。而不是代码里面充斥着 !=null, !=""
检查是否为空,不仅仅是字符串类型,其他类型的判断,全部都封装在 Preconditions类里,里面的方法全为静态
其中的一个方法的源码
@CanIgnoreReturnValue
public static <T> T checkNotNull(T reference) {
if (reference == null) {
throw new NullPointerException();
}
return reference;
}
复制代码| 方法声明(不包括额外参数) | 描述 | 检查失败时抛出的异常 |
|---|---|---|
| checkArgument(boolean) | 检查boolean是否为true,用来检查传递给方法的参数。 | IllegalArgumentException |
| checkNotNull(T) | 检查value是否为null,该方法直接返回value,因此可以内嵌使用checkNotNull。 | NullPointerException |
| checkState(boolean) | 用来检查对象的某些状态。 | IllegalStateException |
| checkElementIndex(int index, int size) | 检查index作为索引值对某个列表、字符串或数组是否有效。 index > 0 && index < size | IndexOutOfBoundsException |
| checkPositionIndexes(int start, int end, int size) | 检查[start,end]表示的位置范围对某个列表、字符串或数组是否有效 | IndexOutOfBoundsException |
这个方法是在Objects过期后官方推荐使用的替代品,该类最大的好处就是不用大量的重写 toString,用一种很优雅的方式实现重写,或者在某个场景定制使用。
Person person = new Person("aa",11);
String str = MoreObjects.toStringHelper("Person").add("age", person.getAge()).toString();
System.out.println(str);
//输出Person{age=11}
复制代码排序器[Ordering]是Guava流畅风格比较器[Comparator]的实现,它可以用来为构建复杂的比较器,以完成集合排序的功能。
natural() 对可排序类型做自然排序,如数字按大小,日期按先后排序
usingToString() 按对象的字符串形式做字典排序[lexicographical ordering]
from(Comparator) 把给定的Comparator转化为排序器
reverse() 获取语义相反的排序器
nullsFirst() 使用当前排序器,但额外把null值排到最前面。
nullsLast() 使用当前排序器,但额外把null值排到最后面。
compound(Comparator) 合成另一个比较器,以处理当前排序器中的相等情况。
lexicographical() 基于处理类型T的排序器,返回该类型的可迭代对象Iterable<T>的排序器。
onResultOf(Function) 对集合中元素调用Function,再按返回值用当前排序器排序。
复制代码示例
Person person = new Person("aa",14); //String name ,Integer age
Person ps = new Person("bb",13);
Ordering<Person> byOrdering = Ordering.natural().nullsFirst().onResultOf(new Function<Person,String>(){
public String apply(Person person){
return person.age.toString();
}
});
byOrdering.compare(person, ps);
System.out.println(byOrdering.compare(person, ps)); //1 person的年龄比ps大 所以输出1
复制代码Stopwatch stopwatch = Stopwatch.createStarted();
for(int i=0; i<100000; i++){
// do some thing
}
long nanos = stopwatch.elapsed(TimeUnit.MILLISECONDS);
System.out.println(nanos);
复制代码TimeUnit 可以指定时间输出精确到多少时间
以前我们写文件读取的时候要定义缓冲区,各种条件判断,各种 $%#$@#
而现在我们只需要使用好guava的api 就能使代码变得简洁,并且不用担心因为写错逻辑而背锅了
File file = new File("test.txt");
List<String> list = null;
try {
list = Files.readLines(file, Charsets.UTF_8);
} catch (Exception e) {
}
Files.copy(from,to); //复制文件
Files.deleteDirectoryContents(File directory); //删除文件夹下的内容(包括文件与子文件夹)
Files.deleteRecursively(File file); //删除文件或者文件夹
Files.move(File from, File to); //移动文件
URL url = Resources.getResource("abc.xml"); //获取classpath根下的abc.xml文件url
复制代码Files类中还有许多方法可以用,可以多多翻阅
guava的缓存设计的比较巧妙,可以很精巧的使用。guava缓存创建分为两种,一种是CacheLoader,另一种则是callback方式
CacheLoader:
LoadingCache<String,String> cahceBuilder=CacheBuilder
.newBuilder()
.build(new CacheLoader<String, String>(){
@Override
public String load(String key) throws Exception {
String strProValue="hello "+key+"!";
return strProValue;
}
});
System.out.println(cahceBuilder.apply("begincode")); //hello begincode!
System.out.println(cahceBuilder.get("begincode")); //hello begincode!
System.out.println(cahceBuilder.get("wen")); //hello wen!
System.out.println(cahceBuilder.apply("wen")); //hello wen!
System.out.println(cahceBuilder.apply("da"));//hello da!
cahceBuilder.put("begin", "code");
System.out.println(cahceBuilder.get("begin")); //code
复制代码api中已经把apply声明为过期,声明中推荐使用get方法获取值
callback方式:
Cache<String, String> cache = CacheBuilder.newBuilder().maximumSize(1000).build();
String resultVal = cache.get("code", new Callable<String>() {
public String call() {
String strProValue="begin "+"code"+"!";
return strProValue;
}
});
System.out.println("value : " + resultVal); //value : begin code!
复制代码以上只是guava使用的一小部分,guava是个大的工具类,第一版guava是2010年发布的,每一版的更新和迭代都是一种创新。
jdk的升级很多都是借鉴guava里面的思想来进行的。
代码可以在 github.com/whirlys/ela… 下载
细节请翻看 guava 文档 github.com/google/guav…
标签:情况 官方 ogr 大小 width 包含 程序 char diff
原文地址:https://www.cnblogs.com/fleekfan/p/11572232.html