标签:管理 sim png 在线文档 通信 维护 def recv replace
web应用与web框架本质
什么是web应用程序呢? Web应用程序就一种可以通过互联网来访问资源的应用程序, 用户可以只需要用一个浏览器而不需要安装其他程序就可以访问自己需要的资源.
应用软件通常有两种架构: B/S架构和传统的C/S架构. C/S架构是客户端/服务端程序, 用户需要访问服务器需要下载单独的客户端, 而B/S则是浏览器/服务端应用程序, 用户只需要选择兼容的合适的浏览器, 如IE, Chrome, Firefox等等来运行即可. Web应用程序通常就是属于B/S架构 ,这也是现在的主流软件架构.
Web应用程序是基于网络进行传输的, 而在网络上传输就需要通过socket, 一般都是通过TCP/IP协议来进行通信的, 因此我们可以这样理解Web应用, 浏览器就是Socket客户端程序, 而Web应用程序就是Socket服务端程序.
有了这个认识, 客户端程序不需要我们负责, 我们就可以基于socket专心搭建一个服务端就可以完成简易版的Web应用了.
import socket
server = socket.socket()
server.bind(('localhost', 8080))
server.listen(5)
while True:
# 开启接收客户端的程序
conn, addr = server.accept()
data = conn.recv(1024)
# 这里打印看来自服务端
print(data)
# 返回响应信息
response = 'Hello World!!!'
conn.send(response.encode('utf-8'))
conn.close() # 关闭连接基于简单的socket, 我们接受了来自服务端的请求, 获得了如下的请求信息
b'GET / HTTP/1.1\r\nHost: 127.0.0.1:8080\r\nConnection: keep-alive\r\nCache-Control: max-age=0\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36\r\nSec-Fetch-Mode: navigate\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\r\nSec-Fetch-Site: cross-site\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: zh-CN,zh;q=0.9\r\nCookie: csrftoken=mUcuvpw1xeYvCqI0VUWuxOEDORAMVOZ1JHAkJXXEiajSi8KisZx6sTRke9H3AEyf\r\n\r\n'我们返回了信息给浏览器, 浏览器的显示是

这说明我们发送给浏览器的响应式无效的, Web应用程序想要在网络中完整的传输, 就一定需要遵从一定的通信协议,而在Web端这个应用层协议就是HTTP协议.
HTTP协议是有属于它自己的传输数据的格式的, HTTP的数据格式包含以下部分:
服务端的响应格式也与之相对应:
了解了HTTP的基本数据格式之后, 只要我们发送合法的响应信息, 就能和浏览器做一个基本的通信了, 然后继续修改上述的代码.
...
# 返回响应头
response = 'HTTP/1.1 200 OK\r\n\r\n'
# 返回响应体
response += '<h1>Hello World!!!</h1>'
...只需要在响应加上响应首行和响应头信息, 并且我们可以在响应体中添加HTML标签, 这就可以让浏览器接收信息并正常解析出我们的响应信息了.
有了以上基础, 我们可以再修改代码, 让服务端返回一个html文件, 并在浏览器端正确渲染出来
...
# 返回响应头
response = 'HTTP/1.1 200 OK\r\n\r\n'
# 返回响应体
# response += '<h1>Hello World!!!</h1>'
with open('index.html', 'r', encoding='utf-8') as f:
response += f.read()
...
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>index</title>
</head>
<body>
<h1 style="color: red">This is page index!</h1>
</body>
</html>

最后浏览器返回了上面的结果. 但是现在又有了新的需求, 这样每次都是返回固定的静态页面, 我们需要返回一个动态的页面. 这就希望页面不要被写死, 而需要动态的获取参数来渲染出响应的页面.就以下面这个动态获取当前的时间页面为例.
...
with open('time.html', 'r', encoding='utf-8') as f:
response += f.read()
response = response.replace('{{ now }}', time.strftime('%Y-%m-%d %X'))
conn.send(response.encode('utf-8'))
...
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>time</title>
</head>
<body>
<h1 style="color: red">This is time page!</h1>
<p>Now time is {{ now }} !</p>
</body>
</html>
最后的效果如下所示, 每次请求都显示不同的时间. 这里的思想也很容易, 就是用字符串的替换, 把特殊的字符换成我们最后需要

现在达成了动态网页的需求, 我们的新需求又来了, 需要能根据用户敲入的不同网址返回不同的信息, 而这就需要我们对来自浏览器的请求进行分析, 请求首行包含了我们需要的请求地址的信息. 这就需要我们对来自浏览器的请求体进行字符串的切割处理了, 来获取我们需要的数据.
import socket
import time
server = socket.socket()
server.bind(('localhost', 8080))
server.listen(5)
def index():
with open('index.html', 'r', encoding='utf-8') as f:
return f.read()
def get_time():
with open('time.html', 'r', encoding='utf-8') as f:
html = f.read()
return html.replace('{{ now }}', time.strftime('%Y-%m-%d %X'))
while True:
# 开启接收客户端的程序
conn, addr = server.accept()
data = conn.recv(1024)
# 这里打印看来自服务端
print(data)
# 这里进行字符串的切割, 先以换行符来切割, 在以空格切割
path = data.decode('utf-8').split('\n')[0].split(' ')[1]
# print(path)
# 获取了路径之后, 我们就能够根据不同的请求路径返回不同的信息了.
response = 'HTTP/1.1 200 OK\r\n\r\n'
if path == '/index':
response += index()
elif path == '/time':
response += get_time()
else:
response += '404 error'
conn.send(response.encode('utf-8'))
conn.close() # 关闭连接我们的简易web服务端到了这已经有了点雏形了, 但是还不能支持并发, 并且我们还发现了前面的socket程序代码也是固定不变的, 处理浏览器请求头的过程是固定的, 返回的形式也是固定的, 而我们也只是简单的处理了请求路径的信息, 如果还需要其他信息, 就又要进行字符串的切割处理, 因此这样的处理工作是重复的, Python的原则是不要重复造轮子, 接下来就可以利用Python内置的wsgiref模块来完成前面这些固定的处理流程.
wsgiref模块是一个遵从WSGI(web server gateway interface, web服务网关接口)协议, 那么什么是WSGI协议呢?在我们真实的生产环境中, 一般分为服务器程序和web应用程序.
在没有 WSGI 规范之前,一个服务器调度 Python 应用是用这种方式,另一款服务器使用的是那种方式,这样的话,编写出来的应用部署时只能选择局限的某个或某些服务器,达不到通用的效果。
所以,WSGI 的出现就是为了解决上面的问题,它规定了服务器怎么把请求信息告诉给应用,应用怎么把执行情况回传给服务器,这样的话,服务器与应用都按一个标准办事,只要实现了这个标准,服务器与应用随意搭配就可以,灵活度大大提高。
下面的图片说明了wsgi的工作流程.
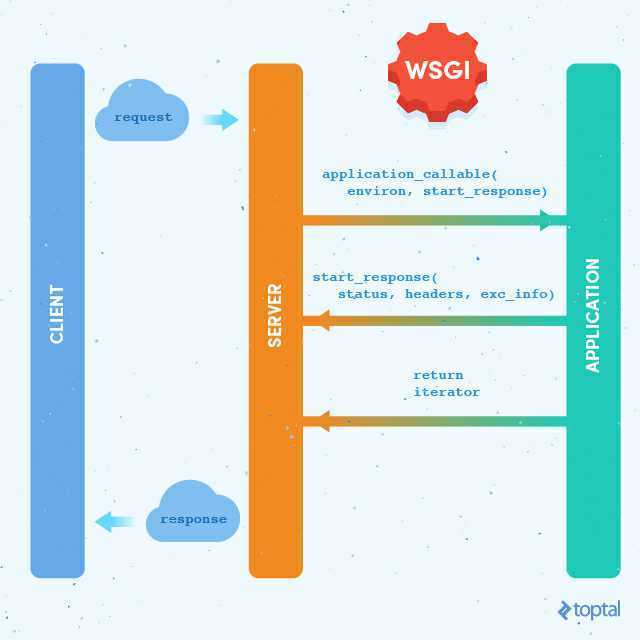
首先浏览器发送请求到服务端, 服务端对数据进行处理, 并把请求信息封装到environ字典中, 并调用一个应用程序(这通常是一个可调用对象)来处理业务逻辑请求, 当应用程序处理完业务逻辑之后, 会调用start_response这个回调函数来发送状态信息, 响应头部的信息和可能出现的异常错误信息. 发送完这个数据响应信息之后, 最后再返回一个可迭代对象(可以是字符串, 字典, 列表...)的数据信息给服务器程序. 最后再返回给客户端.
了解了什么是wsgi协议之后, 我们接下来就可以利用wsgiref模块来修改上面的应用程序了.
import time
from wsgiref import simple_server
# 视图部分, 具体的处理逻辑
def index():
with open('index.html', 'r', encoding='utf-8') as f:
return f.read()
def get_time():
with open('time.html', 'r', encoding='utf-8') as f:
html = f.read()
return html.replace('{{ now }}', time.strftime('%Y-%m-%d %X'))
def error():
"""请求路径不能匹配返回的信息"""
return '404 error'
urls = [
('/index', index),
('/time', get_time)
]
def run(environ, start_response):
"""
我们的app应用的入口函数
:param environ: 服务器处理过后的请求参数都包含在里面了, 包含请求路径信息等
:param start_response: 处理完数据后调用的响应回调函数
"""
# 根据请求信息的不同, 来到不同的视图函数进行业务逻辑的处理
path = environ.get('PATH_INFO') # 包含了请求的路径信息
func = None
for url, f in urls:
if url == path:
func = f
break
# 如果url全部不匹配返回错误页面的信息
res = func() if func else error()
# 数据处理完毕, 这里要调用响应的回调函数, 进行处理, 响应头信息
start_response('200 OK', [('Content-Type', 'text/html;charset=utf8'), ])
# 最后返回可迭代数据信息
return [res.encode('utf-8'), ]
if __name__ == '__main__':
# 创建一个服务器应用程序, 绑定ip端口和要调用的app入口函数
server = simple_server.make_server('localhost', 8080, run)
server.serve_forever() # 服务器永远启动着
上面的wsgiref模块实现的服务器严格的按照了wsgi协议, 我们自己实现的应用程序也遵守了wsgi接口规范, 这就让双方可以完美对接, 服务器程序和应用程序亦可以很大程度的实现解耦.
Django 简介
Django是一个由Python编写的具有完整架站能力的开源Web框架。使用Django,只要很少的代码,Python的程序开发人员就可以轻松地完成一个正式网站所需要的大部分内容,并进一步开发出全功能的Web服务。
Django本身基于MVC模型,即Model(模型)+View(视图)+ Controller(控制器)设计模式,因此天然具有MVC的出色基因:开发快捷、部署方便、可重用性高、维护成本低等。Python加Django是快速开发、设计、部署网站的最佳组合。
Django具有以下特点:
标签:管理 sim png 在线文档 通信 维护 def recv replace
原文地址:https://www.cnblogs.com/yscl/p/11569491.html