标签:ref 处理器 nal 碎片 要求 count 检查 用户体验 nbsp
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。
虽然我们对各个收集器进行比较,但并非要挑选出一个最好的收集器。因为直到现在为止还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,我们能做的就是根据具体应用场景选择适合自己的垃圾收集器。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的 HotSpot 虚拟机就不会实现那么多不同的垃圾收集器了。
主要的垃圾收集器有以下几种:
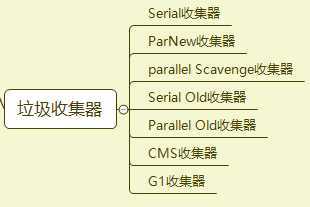
Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收集器了。
大家看名字就知道这个收集器是一个单线程收集器了。它的 “单线程” 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( "Stop The World" ),直到它收集结束。
虚拟机的设计者们当然知道 Stop The World 带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短(仍然还有停顿,寻找最优秀的垃圾收集器的过程仍然在继续)。
但是 Serial 收集器有没有优于其他垃圾收集器的地方呢?
当然有,它简单而高效(与其他收集器的单线程相比)。Serial 收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial 收集器多用于桌面应用,Client端的垃圾回收器。桌面应用内存小,进行垃圾回收的时间比较短,只要不频繁发生停顿就可以接受。
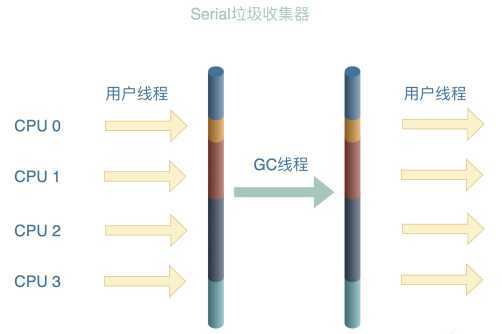
ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。
特点:
并行和并发概念补充:
并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),用户程序在继续运行,而垃圾收集程序运行于另一个 CPU 上
Parallel Scavenge 收集器是一个新生代收集器,它也是使用复制算法的收集器,又是并行的多线程收集器。
Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。 Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在困难的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
吞吐量是什么?
CPU用于运行用户代码的时间与CPU总时间的比值,99%时间执行用户线程,1%时间回收垃圾 ,这时候吞吐量就是99%。
Serial 收集器的老年代版本,它同样是一个单线程收集器。它主要有两大用途:一种用途是在 JDK1.5 以及以前的版本中与 Parallel Scavenge 收集器搭配使用,另一种用途是作为 CMS 收集器的后备方案。
Parallel Scavenge 收集器的老年代版本。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它非常符合在注重用户体验的应用上使用。
CMS(Concurrent Mark Sweep)收集器是 HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。
目前很大一部分的Java应用集中在互联网站或者B/S系统的服务端上,这类应用尤其重 视服务的响应速度,希望系统停顿时间最短,以给用户带来较好的体验。
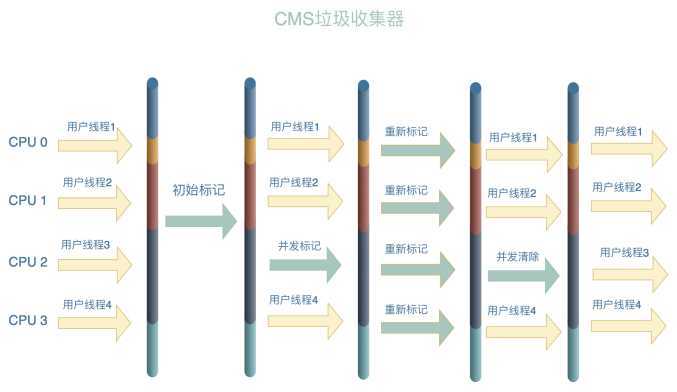
从名字中的Mark Sweep这两个词可以看出,CMS 收集器是一种 “标记-清除”算法实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
从它的名字就可以看出它是一款优秀的垃圾收集器,主要优点:并发收集、低停顿。但是它有下面三个明显的缺点
G1 (Garbage-First) 是一款面向服务器的垃圾收集器,主要针对配备多核处理器及大容量内存的机器. 以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征.
G1 中每个 Region 都有一个与之对应的 Remembered Set,当进行内存回收时,在 GC 根节点的枚举范围中加入 Remembered Set 即可保证不对全堆扫描也不会有遗漏 (检查Reference引用的对象是否处于不同的Region)。
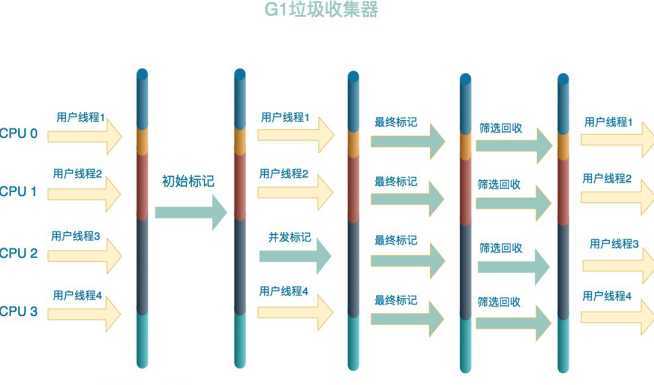
G1 收集器的运作大致分为以下几个步骤:
被视为 JDK1.7 中 HotSpot 虚拟机的一个重要进化特征。它具备一下特点:
标签:ref 处理器 nal 碎片 要求 count 检查 用户体验 nbsp
原文地址:https://www.cnblogs.com/woxbwo/p/11576049.html