标签:完成 扩容 ati 作者 频繁 思路 数据分片 化运维 相对
内容来源:2017 年 8 月 12 日,饿了么高级Python工程师黄光星在“CRUG 2017北京活动”进行《Redis Cluster运维方案》演讲分享。IT 大咖说(微信id:itdakashuo)作为独家视频合作方,经主办方和讲者审阅授权发布。
摘要
本次演讲将介绍饿了么在运维Redis Cluster中遇到的一些坑和原理。还会讨论运维Redis Cluster的具体方案,包括标准化集群、快速应对机器故障、加速slot迁移等。其中将着重分析标准化集群如何治理Redis集群并帮助我们简化运维操作和降低风险。
嘉宾演讲视频回放及PPT,请复制链接:http://t.cn/Rgp5Dq7,粘贴至浏览器地址栏即可。
Redis Cluster简介
官方的集群方案

Redis Cluster的官方集群方案提供了主从和分片。一份数据在一个分片上可以存多份,即一个master可以挂多个Slave。上图的集群中存在三个分片,每个分片有一个master和多个Slave。每个redis节点和集群中的任何一个节点都会有一条数据通路来互相传递关于集群状态的信息。主要包括两个信息,一个是谁是主节点,另一个是主节点管理着哪些些数据分片。
这样的集群方案存在一个问题。以往我们使用千兆网卡的时候,如果集群存在超过三四百个节点的时候,这些节点两两互联的数据通路中的数据会非常大,可能会达到每秒100多兆, 占去千兆网卡不少流量。所以运维下来之后我们最后是倾向于使用比较小的集群,因为大的集群不光风险高,网络开销也很大。
请求流程
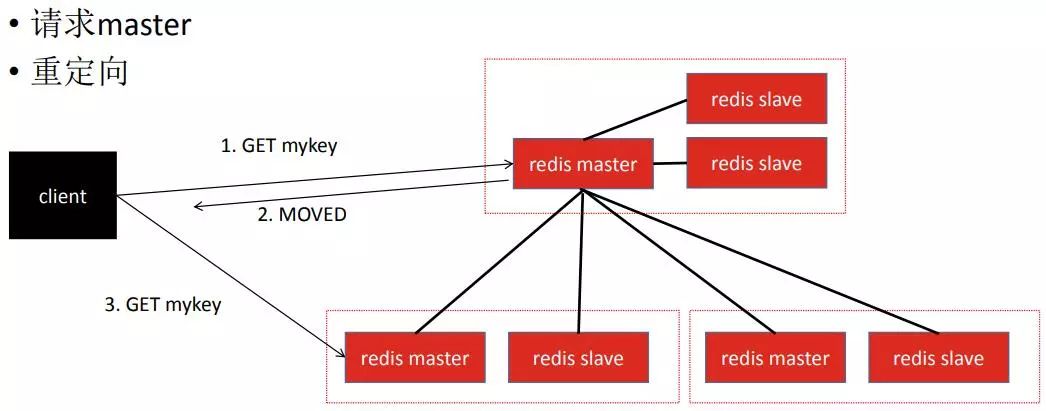
整个请求流程中,客户端最初会保存整个集群的一份节点列表,请求的时候会随机在节点列表中选择一个节点尝试请求,如果被请求的节点确实是负责处理该请求的话就会正常处理请求然后返回数据。否者被请求节点会返回一个重定向,告知客户端它认为能够处理该请求的其它节点在哪,然后客户端重定向到目标节点上。这个过程会一直重复下去,直到客户端找到了能够处理请求的节点。
需要注意的是如果用到了集群,客户端就必须实现该集群协议。第一要能够做重定向,单机redis 客户端是无法完成重定向的。第二要能够缓存整个集群的信息,这样就可以第一时间找到正确的请求节点,避免多次重定向。
Redis Cluster Proxy - corvus
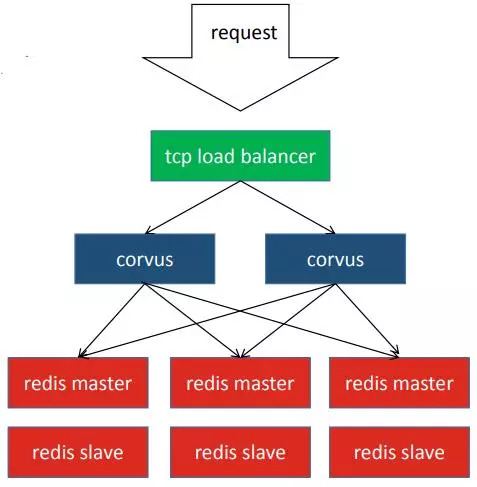
我们公司一开始在用这套方案的时候,因为客户端大部分用的是单机协议,切换到集群的话升级客户端会比较困难,当时Python也没有比较好的支持集群协议的客户端库。因此我们在原生的redis cluster基础上做了一层redis cluster proxy,用来对外暴露单机redis协议,对内屏蔽redis cluster协议。又由于redis cluster proxy不能是单点,因此会有多个corvus在此之上服务集群,corvus前面还有TCP load balancer,用来做HA和分摊流量到多个corvus。
这里额外提一点,我们的服务化其实是在最上方的TCP load balancer中,当集群出现问题需要立刻迁移到另一个集群的时候会通过TCP load balancer来做。
运维问题
运维方法——第一阶段

Redis cluster会提供很多命令来操作节点,上图就是扩容会用到的一些命令。在实际使用的过程中,可能需要多次频繁地输入这些命令,且输入的过程中还要监视它的状态,所以基本上是不可能人工跑这些命令的。官方为此提供了一个脚本封装了这些命令,对外暴露出比较简单的命令行接口来帮助运维集群。
依靠这个官方脚本基本能应对运维少量的小集群。
运维方法——第二阶段
在集群数量不多的情况下,使用官方的脚本来运维不会出现太多问题。一旦集群过多,光是脚本就不够了,因为部署集群的时候,首先要拉起进程,而这个过程脚本无能无力。
因此很多公司都会采用更一体化的方案来管理redis cluster。一般会先使用熟悉的语言重写运维工具,我们用了Python重构运维脚本。然后将重造的运维脚本封装成面板,后续操作直接在面板上进行。
这个方案已经足以应对上百个集群的运维了。但随着集群数量持续增多,集群服役时间逐渐变长,又出现了一些新问题。
压力不平均
正常情况下集群部署好以后,一般不会出现太大的问题。但是可能在线上运行一段时间后,每台机器上的主从节点数量会从原先的平均分布转换成了单台机器全部都是slave或master。造成该问题的原因可能是网络因素,也可能是节点压力过大导致主从切换。
每台机器上的主节点不平均会导致压力不平均。以前我们在用千兆网卡的时候,每台机器会部署20多个节点,如果出现了某台机器上分布大量主节点,会导致这台机器的网卡被打爆。面对这种情况大多数人的第一反应可能是重新调整主从分布,比如将机器上某个Slave重新切回到master。但是仔细想想就会发现其实很难光靠算法来找到应该切换哪个Slave,因此我们一般都是通过在最初部署或变更集群的时候,保存整个集群的主从分布来快速知道需要切换哪个slave。
宕机后压力不均衡
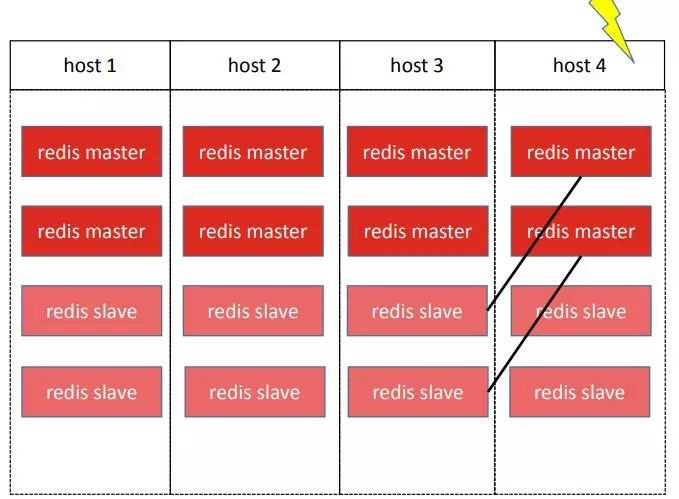
第二个问题也是压力不平均,不过是宕机后出现的。上图中第三台机器的两个slave和第四台机器上的两个master分别在同一个分片中,这种结构下第四台机器挂了以后,它的master就会全部切换到第三台机器上,这也会导致压力不平均。所有在创建集群和做变更操作时,需要考虑到某台机器挂掉之后,它的压力是否能够尽可能的平均分摊到多台机器上。
而宕机后给集群补充机器时也可以用上述保存初始主从分布的办法来恢复集群原有的主从分布。
扩缩容时分配节点
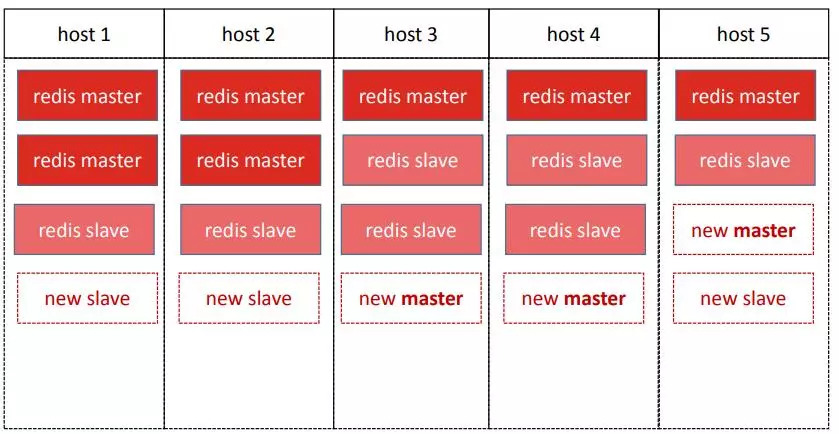
扩容时的节点分配也是比较头痛的问题,上图展示的是一个集群的结构, 白色框表示的是新增的节点。我们之前的线上结构是每台机器部署多个集群的节点,不同的机器可用资源还不同。因此在部署的时候也要考虑到部署完成后主节点分布是否平均,某台机器挂了切换后的压力是否也是平均的。
扩容相对好做,缩容就很难再去用算法计算该缩哪些节点了。
集群标准化
总结下来,redis运维存在一些难点,一是节点数量过多,二是在创建、扩缩容、宕机后补充机器的时候还要考虑好正常情况和宕机后的主从分布是否均衡,三是集群混合部署的时候要考虑到不同规格的节点对机器资源的使用应合理。
在使用redis的过程中,我们最大的感受就是不能进行松散的管理。Redis作者最初的设计初衷可能是想要可松散管理的结构。所以甚至会有这种特性,当某个分片的从节点数量过多,而另外的分片没有从节点时,节点过多的分片的从节点可以迁移到没有从节点的分片上。这个特性本身就有问题,首先无法保障迁移完之后主从节点不会在同一台机器上,其次也没有考虑上述压力均衡的问题。松散管理本身无法给集群提供合理的结构,在运维的时候需要针对不同结构的集群使用不同的算法去解决问题,例如我们曾经要用最大流算法去做从节点的补给。
为了能够更好的运维redis cluster,我们希望能够找到一套规则去约束集群的结构来简化运维复杂度。对此会有一些具体的要求,第一集群能在挂一台机器的情况下不影响服务,要满足这个要求,主从节点就不能在一台机器上,也不能有过半数(包括半数)主节点在同一台机器上。第二集群在挂一台机器的情况下,压力应尽可能平均分流到其他机器。第三主节点和从节点在各台机器上的分布应当平均。
集群约束
我们为此提出了一套对集群的约束。该方案首先有个简单粗暴的规则,即每个分片只有一个从节点,每个节点的maxmemory一样。

在此基础上我们又提出了一种分组管理的方式——chunk,如上图所示。分组由四个节点组成,平均地分配到两台机器上,组成两个完整的分片。可以看到第一台机器上是第一个分片的master和第二个分片的Slave,第二台机器情况类似。这样的结构可以保证主从不在同一台机器上,每台机器主从比例也会一样,每台机器的chunk的数量差不多的话,主节点数量就差不多,压力也差不多。同时主从角色得以固定,当发生压力不平均的情况能够很方便的做主从切换。
而集群就由一个一个chunk来组成。
之所以是分组是4个节点而不是6个节点,是因为6个节点很难找到比较好的分配算法来分配chunk,而4个节点则可以通过相对简单的算法来实现分配。

Chunk的集体分配算法这里就不在谈论了,主要来看下分配的思路。首先必须要有一张核心的二维表来记录信息,就是上图右边的部分。纵坐标和横坐标都是对应的机器,格子中的值表示的是两台机器之间公共chunk的数量。在分配的时候一方面要保证能够分配完,算法能够终止,另一方面在分配完之后表中的最大值要尽可能的小。这样就能保证一台机器挂了之后,压力不会集中到某一台机器上。
通过给集群加了结构上的约束和使用上述的分配算法,集群无论在创建或变更后都符合上述的规范,最后保证无论有没有挂机器,压力都平均,而且无论哪台机器挂了选举都能正常进行。
运维操作
有了这一套管理方案之后我们提供了一些运维操作。创建集群的时候可以利用自己生成的nodes.conf配置文件来快速完成操作,该配置文件保存了整个集群的信息,比如节点的数量、节点的属性、节点管理的数据分片等,它是根据上面提到的算法的计算结果所生成的。扩容和缩容的时候只要还是按照上面的二维表来增删chunk,那么结构就不会出问题。宕机恢复我们也是利用了nodes.conf,当集群中某台机器宕机之后,可以直接在备用机器上生成宕机机器的nodes.conf配置文件来拉起节点。由于nodes.conf会记录每个节点的ID,而ID是节点在集群中的唯一身份标记,所以备用机器中的节点和原先的节点在集群看来并无什么差别。
其他经验
并行迁移slot
由于redis cluster迁移槽位只能串行,因此使用的时候会非常缓慢。比如像我们这样的200个节点一组一从的结构,每个节点2G的情况下,如果要扩容一倍,那么做迁移槽位可能需要十几个小时。
为了能够快速迁移,我们想到了并行迁移。在查看了redis的迁移协议之后,发现它其实是可以做多个分片同时并行迁移的,只不过要自己实现迁移脚本。采用并行迁移之后从十几个小时直接缩短到一个小时以内。
为什么可以并行迁移
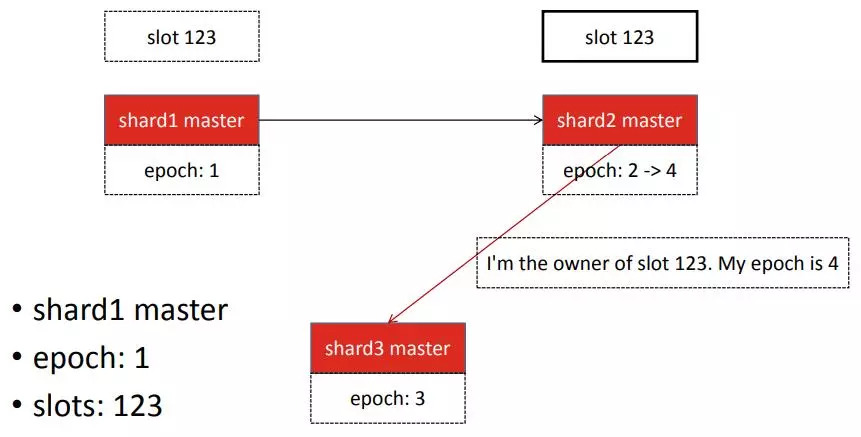
上图上redis官方迁移的流程。这里有三个shard,需要将123这个数据分片从shard1迁移到shard2。迁移的过程中,首先为这两个shard打上标记,然后会将所有的数据导入到shard2中,最后会发生逻辑时钟的改变。分片的所有权通过逻辑时钟管理。一开始shard1声称自己是slot 123的负责人,它的逻辑时钟为1。迁移完之后shard2为了表明自己才是slot 123的负责人,会增加逻辑时钟来告知其他shard自己是最新发生变动的节点,所以知道最新的信息,以保证可信性。
只要迁移的时候节点不会同时即迁出又迁入,这样整个集群就会有两部分的节点,迁入的节点逻辑时钟会变高,迁出的节点逻辑时钟不会改变。这样只要不挂节点,在并行跑的时候逻辑时钟并不会错乱,槽位归属不会出问题。
Redis cluster的坑
下面讲下redis cluster的一些坑,包括迁移slot时redirection过多,slot信息不一致,选举缓慢等问题。
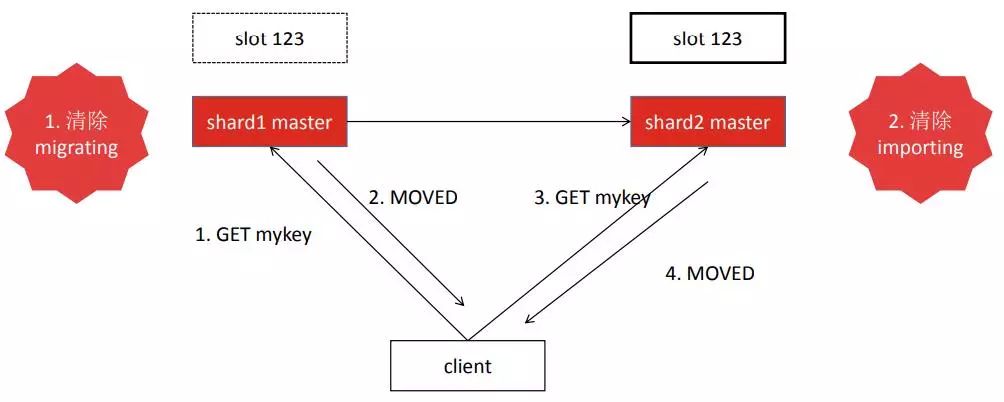
首先说下迁移slot时redirection过多的问题。一般迁移完之后会清除migrating和importing,而官方的脚本在执行的时候没有考虑到清除顺序问题。这样就会出现在很短暂的时间内,某个slot不归属任何的shard。这是由于官方脚本有时会先清migrating再清importing,导致两边节点都不认为自己是slot的管理者。
Slot信息在集群里面是有可能变得不一致的。最容易造成Slot信息不一致的情况是迁移的时候迁出节点的master挂了,导致部分迁移中的slot变成没有节点管理,Slot信息也跟着不一致。
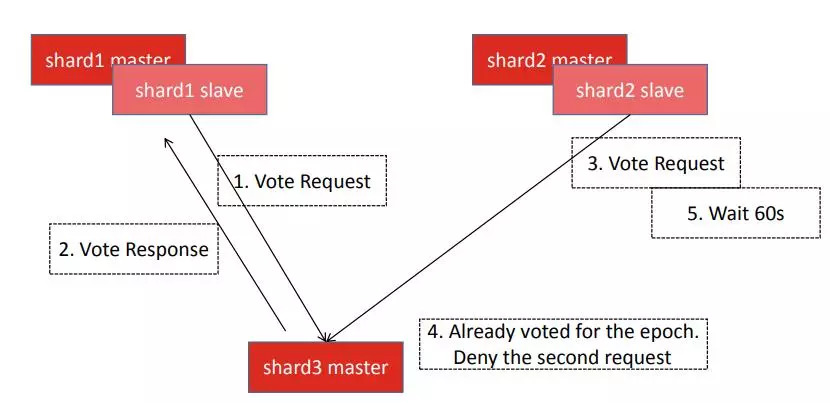
正常情况下redis cluster选举是很快的,但是我们在生产环境和测试环境中都出现过选举需要2-3分钟的情况。后面发现这也由于迁移协议的设计问题造成的。投票的时候需要所有的master一起来投票,此时如果有多个分片一起挂了,多个节点会向多个master发起请求选票,因为每个逻辑时钟只能处理一个分片的选举,所有如果同时有多个发起的话,第二个发起的请求的节点就会被推迟1分钟,运气不好的话可能会被推迟几分钟。
以上为今天的全部分享内容,谢谢大家!
标签:完成 扩容 ati 作者 频繁 思路 数据分片 化运维 相对
原文地址:https://www.cnblogs.com/ExMan/p/11594200.html