标签:来源 文件的 运行程序 源地址 写入 行修改 成功 win 长度
本文基于漏洞战争一书中对于漏洞CVE-2010-3333的分析,与漏洞战争一书不同的是,本文探讨漏洞CVE-2010-3333在Micrsoft office 2007+Win XP sp3环境下的漏洞成因与漏洞利用。CVE-2010-3333主要成因在于Word在打开rtf文件时,mso.dll模块中某条指令调用了memcpy函数,而内存复制的数据长度和源数据均来源于rtf文件中的数据,所以通过构造trf文件,可以使该文件被Word打开时,执行栈溢出攻击。
本漏洞主要特点在于出现异常的memcpy函数复制数据的目的地址并不在本函数的栈帧中,所以溢出无法覆盖memcpy本函数的返回地址,只能覆盖其他函数的返回地址,被覆盖返回地址的函数是在memecpy函数之前被调用的,所以在memcoy进行栈溢出之后,返回地址被覆盖的函数返回之前,还需要执行大量指令,如果溢出的数据影响了此类指令的执行,被覆盖返回地址的函数无法返回,就无法更改程序执行流程。
为了保证在memcoy进行栈溢出之后,返回地址被覆盖的函数返回之前,所有指令的执行能够正常执行,需要对溢出数据的结构和值进行特殊构造,并且保证此类数据不会影响shellcode的执行(数据对应的指令执行后不会对shellcode产生影响,或者在shellocde中使用短跳指令跳过此类数据)。
为了了解需要构造溢出数据中得哪些部分,需要构造为何值,就需要不断进行调试,对比程序正常返回和程序因溢出数据导致异常两种情况,对比两种情况下指令使用到的内存数据,以此为依据,构建满足要求的溢出数据的数据结构。
本文图片较多,故分为上下两篇发布,博客中部分图片显示模糊,故提供高清原文下载地址如下。
链接: https://pan.baidu.com/s/1XVUJg4kzDU-8AVDSIBfe1A 提取码: 8e3w
使用msf得到cve-2010-3333的POC文件 即msf.rtf。具体过程可以参考漏洞战争一书对应内容。
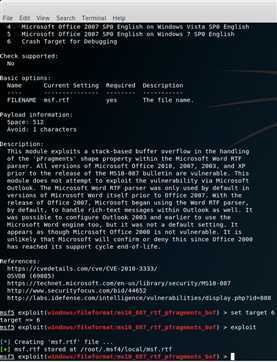
使用od加载word,之后打开poc,程序中断时edi的值为130000,指向一个不可写的内存,从而触发异常,根据栈回溯,发现异常发生在memcpy函数内部,而调用mamcpy的函数可以定位到,可以在该函数上下断点。
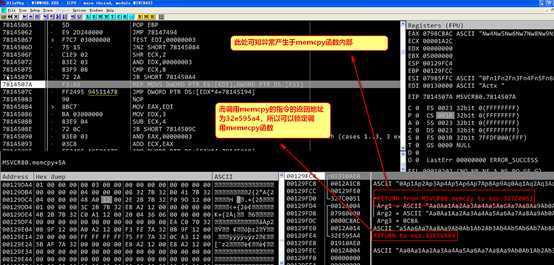
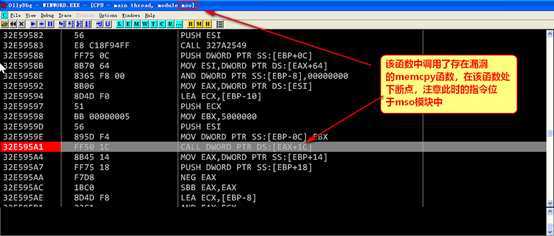
调试程序时注意,如果先打开word,之后使用od对进程进行附加,可以发现mso模块已经被加载,此时可以在该模块中下断点,而直接通过od中restart运行程序,则程序运行起来后mso模块没有被加载,则断点无法起效。

在断点处断下
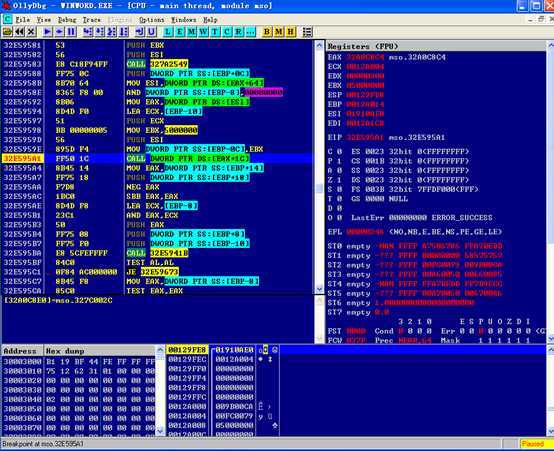
进入该函数,发现该函数中在调用memcpy函数之后返回
在调用memcoy的过程中,发现memcpy函数的参数(主要是数据源地址和数据操作字节数)来源于poc文档中的内容,则推测通过控制poc文档中的内容可以实现向指定内存中复制任意长度的数据。
在memcpy的内部通过串操作指令实现内存的拷贝,但是由于此时复制的字节数过长,所以导致在没有可写权限的内存中写入数据,导致异常。
此时通过计算可以发现只要复制的数据大于24个字节,就可以淹没栈中的返回地址,从而劫持进程。
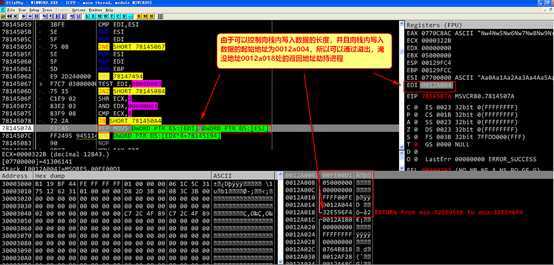
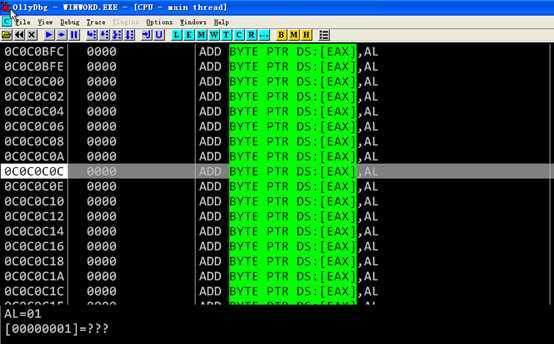
F9之后程序运行到地址0c0c0c0c停住,说明只要精心布置内存,该溢出漏洞可以被利用,
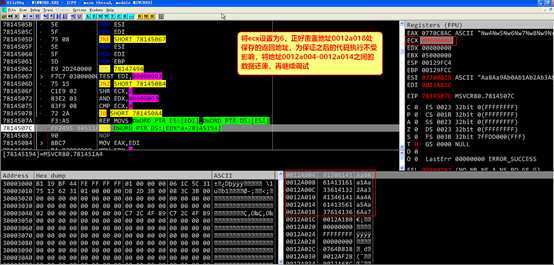
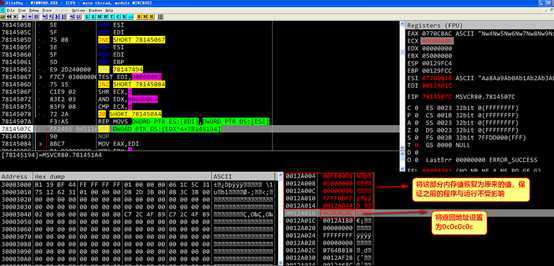
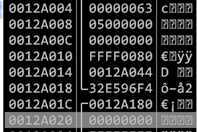
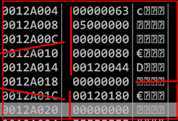
根据测试当地址0x0012a004~0x0012a014之间的内存被覆盖如下两种情况时,修改地址0x0012a018处的函数返回值可以劫持进程,本次实验采用第一种内存布局方法。
注意在地址0x78145075处的cmp ecx,8指令,此时ecx的值为要复制的数据的字节数/4,如果该值小于8,则会执行跳转指令,不进行内存的拷贝,而复制的数据的长度由文件中的特定字段指定,所以说明,文件中该字段的值不能小于0x20(十进制的32),即复制数据的长度不能小于32个字节
此时将poc文件进行修改
可以发现实际内存中用于溢出的数据与文件中设置的数据有所区别,主要是文件溢出数据中使用字母表示的内容在内存溢出数据中都变成0 例如文件中数据8000ffff在内存中变成了80000000,推测原因在于word对rtf文件的解析的规则,这里不做过多讨论,先尝试是否能成功溢出
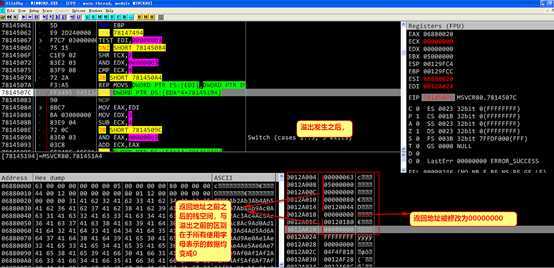
按f9直接运行
总结之前的实验,为了使栈溢出攻击成功,返回地址附近的内存布局必须为以下形式
(其中地址0012a018中保存函数返回地址,是攻击的重点)
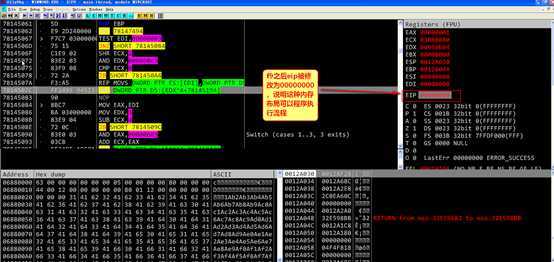
修改POC中的数据,使得溢出发生时,栈中数据布局符合上图
实际在程序运行时,发现内存中的溢出数据与文件中设置的数据存在差别,所有使用字母表示的数据均变成了0,推测与word解析rtf文件的规则相关(此种情况的解决方法之后讨论)如下图
此时原本要将返回地址覆盖为0c0c0c0c,实际上被覆盖为00000000,继续f9运行,eip被修改为0,说明栈溢出攻击成功,目前为止,本次栈溢出用于覆盖返回地址的数据不能包括字母表示的数据,否则会出现错误,此情况有方法解决,解决方法见之后的分析。
之后的问题是如果想要利用该栈溢出漏洞执行任意代码,就需要在上面实验的基础上将shellcode通过漏洞memcpy函数拷贝到栈中,这样需要拷贝的数据量肯定更大,不能仅仅拷贝32字节数据,尝试在文件中,直接将拷贝数据的长度修改为0x90,即144个字节
下图是操作数据长度为144字节时memcpy内部跳转指令的执行流程,对比操作数据长度为32字节时,memcpy执行流程相同,均是通过串操作指令进行内存的复制。
当操作数据大小为144字节时memcpy函数中复制数据的目的地址发生了变化,说明相较于之前溢出32字节的情况,需要重新考虑溢出数据的内存布局,才能正确修改函数返回地址并保证函数正确返回。
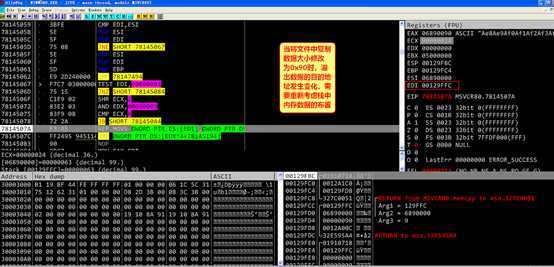
下图是复制数据长度为144字节时数据溢出前目的地址处的内存布局,与复制数据长度为32字节时明显不同,说明需要重新构造溢出数据的内存布局。
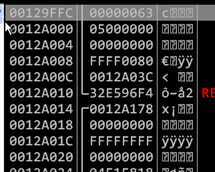
按照上面的内存布局修改溢出内容之后,发现程序直接f9仍然会执行失败,异常发生时堆栈情况如下。
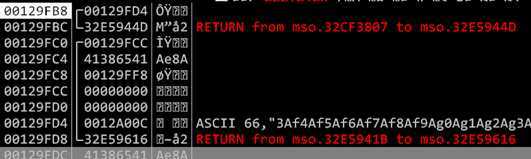
出现异常的主要原因在于溢出发生于memcpy函数 memcpy函数复制数据的目的地址并不在本函数的栈帧中,所以溢出无法覆盖memcpy本函数的返回地址,只能覆盖其他函数的返回地址,被覆盖返回地址的函数是在memecpy函数之前被调用的,所以memcpy函数执行溢出完毕返回后,还需要执行大量代码,直到被覆盖返回地址的函数返回时,才能控制程序执行流程,在被覆盖返回地址的函数返回之前,很可能因为溢出的大量数据,导致指令执行失败。
当复制字节数为144字节时,程序在memcpy执行完之后,执行32e5941b函数时会出现异常,并且可以看到之前在memcpy函数中溢出的数据的首地址00129ffc之后的内存又被文件中的数据覆盖,这种情况在复制数据长度为32字节的时候是没有的,这说明当溢出数据的长度不同时,程序的执行流程可能不同,即在复制字节数为32字节时,此时出现异常的指令可能并不会被执行。
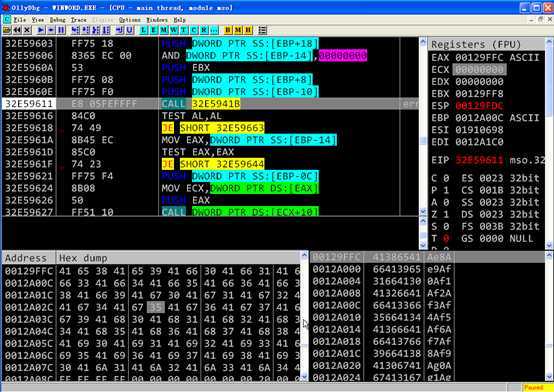
为了分析复制字节数不同而导致的指令执行流程的不同,需要分析复制144字节数据的指令执行过程和复制32字节数据的指令执行过程。
memcpy函数执行完成后,将数据复制的目的地址作为返回值返回
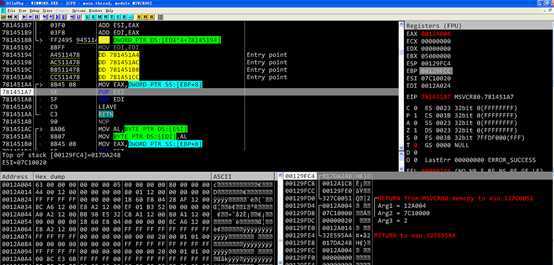
memcpy函数返回之前各个寄存器的值
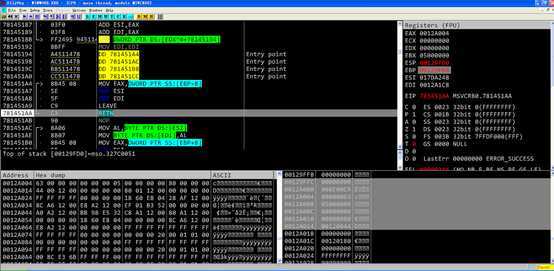
调用memcpy的函数返回之前
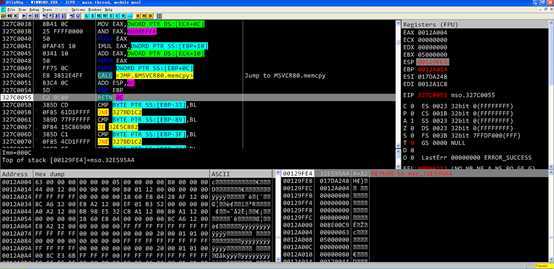
调用memcpy的函数返回之后 调用第一个函数
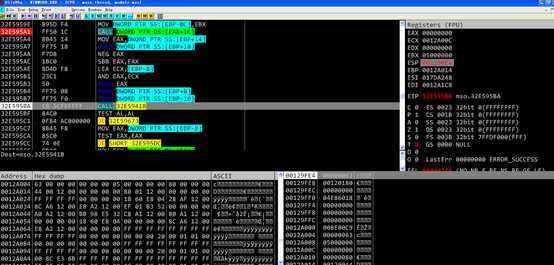
第一个函数调用之后返回值为1,不跳转
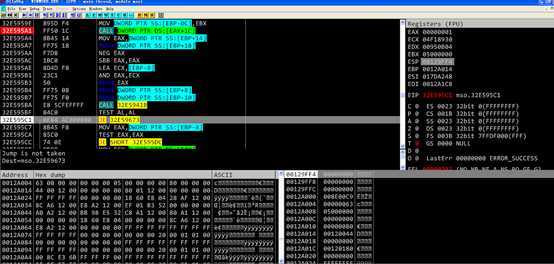
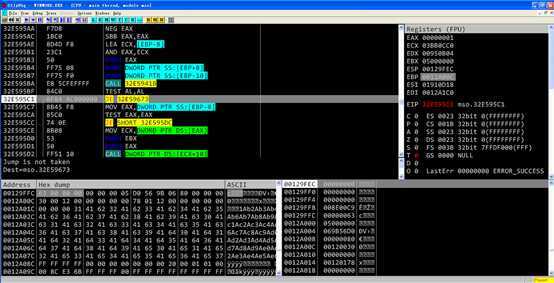
[ebp-8]为0,赋值给eax,跳转
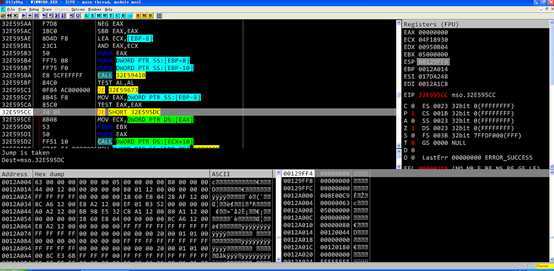
[ebp+c]等于0 [ebp+10]等于-1 1大于-1进行跳转
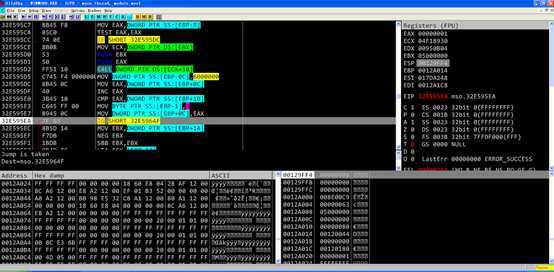
[ebp+14]等于0,并复制给eax,之后会产生跳转
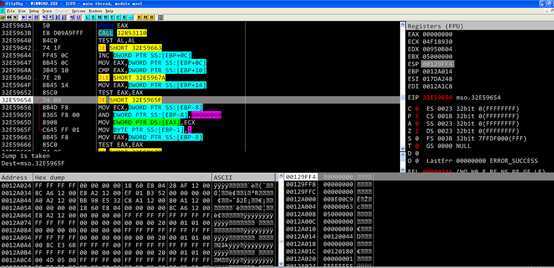
[ebp-8]为0,并复制给eax 跳转
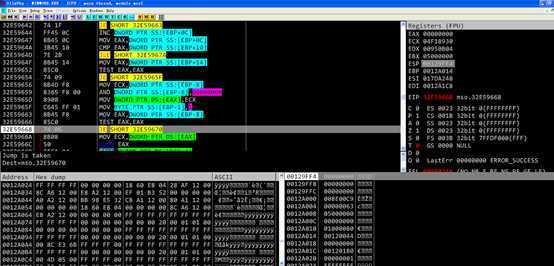
程序进入返回流程,在jmp处跳转到retn 14指令
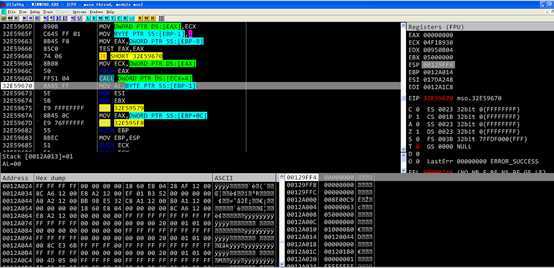
Retn 14返回,程序执行流程转移到被覆盖的返回地址中。
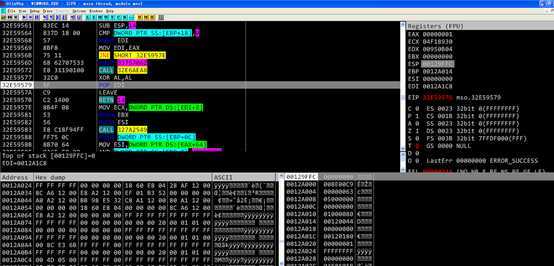
[ebp+14]此时为0x41623241,对比复制0x20个字节的情况,如果想要使指令正常执行并返回,需要使此处的[ebp+14]为0。
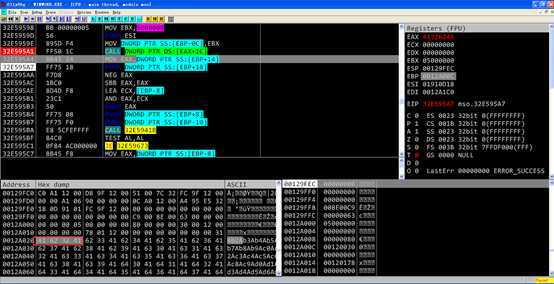
[ebp+18]此时为0x62413362,对比复制0x20个字节的情况需要[ebp+18]为 
[ebp-8]此时为0,这里这个参数是之前精心构造过的,满足正常执行要求,不需要重新构造。
[Ebp+8]此时为0x00120178,这里这个也精心构造过,对比复制0x20个字节的情况[Ebp+8]应该为0x0012a178( ),这里暂时不对[Ebp+8]的内存内容进行重新构造,具体原因在之后分析。
),这里暂时不对[Ebp+8]的内存内容进行重新构造,具体原因在之后分析。
[ebp-10]此时为0x63,该数据也被精心构造过,满足正常执行要求,不需要重新构造。
虽然在复制0x90字节数据的过程中使用了以上被溢出的数据,但是函数32e59673的返回值还是1,所以看上去以上溢出数据不影响函数执行到返回,可是真的是这样的吗?
复制0x90字节数据的指令继续执行,执行到指令mov eax,[ebp-8]时,[ebp-8]的值将会赋值给eax,此时ebp-8中不再是之前精心构造的0,而是另一个值,推测可能是之前的执行32e5941b函数时由于使用了不规范的参数,所以导致此处[ebp-8]的值发生了变化,从这里开始,复制0x20个数据和复制0x90个数据的执行流程不在相同。如果文件数据布局满足之前的要求,则此处[ebp-8]为0,此时就可以触发je。
此时修改标志寄存器的值,强行使程序在je处跳转,继续分析之后的指令是否可能因为使用了溢出的数据而导致错误。
此时[ebp+c]应该为 [ebp+10]应该为
[ebp+10]应该为 ,前者已经满足要求,后者需要专门进行构造。
,前者已经满足要求,后者需要专门进行构造。
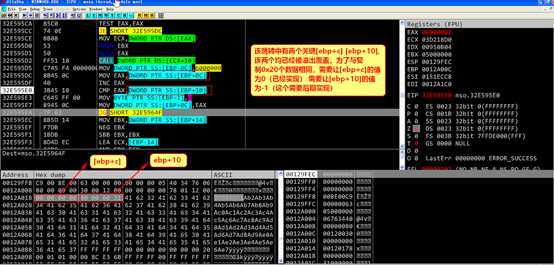
此时ebp+14应该为 ,需要专门构造。
,需要专门构造。
标签:来源 文件的 运行程序 源地址 写入 行修改 成功 win 长度
原文地址:https://www.cnblogs.com/hell--world/p/11595818.html