标签:选择 img field 文件 png values down load name
一、下载安装Apache Solr 8.2.0
下载地址:http://lucene.apache.org/solr/downloads.html
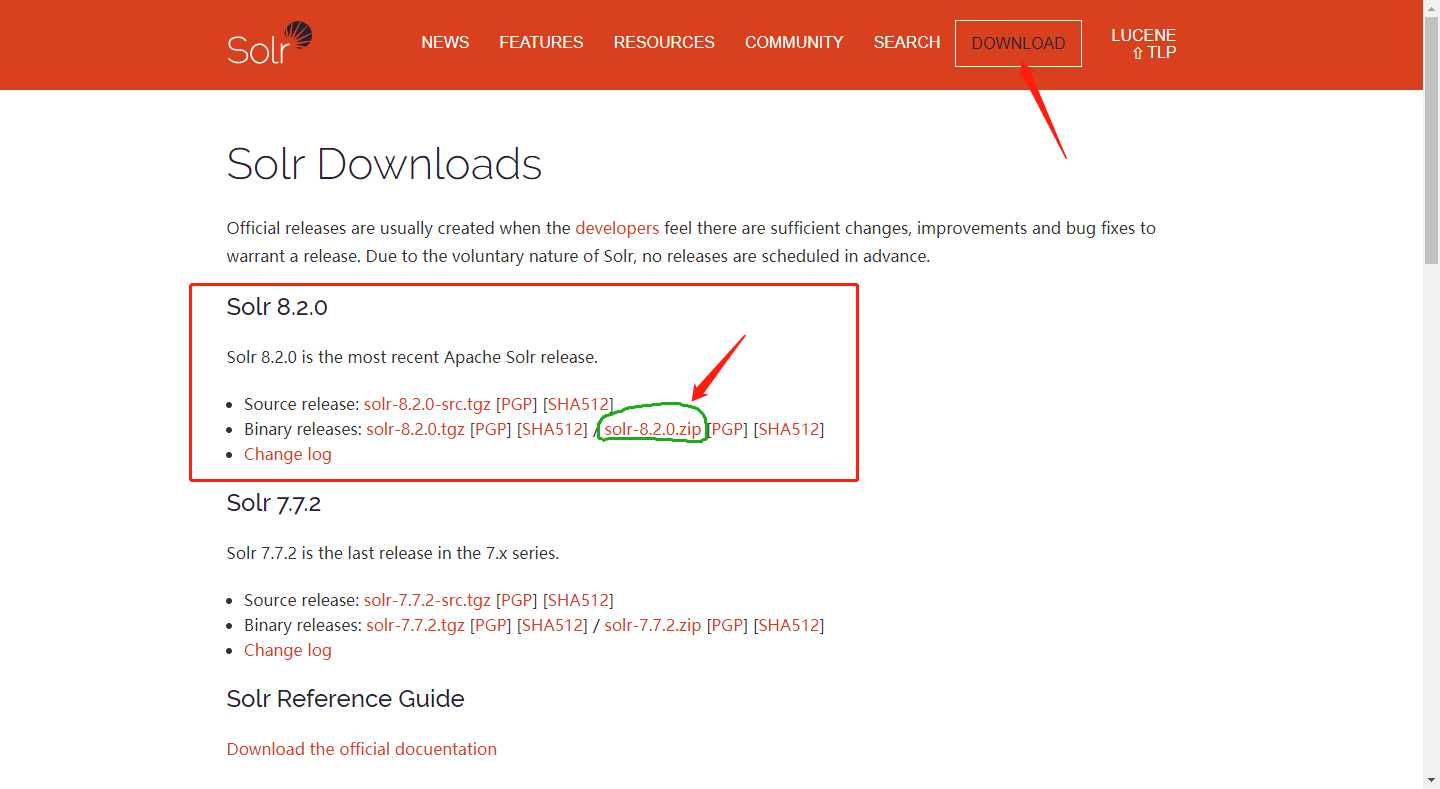
因为是部署部署在windows系统上,所以下载zip压缩包即可。
下载完成后解压出来。
二、启动solr服务
进入solr-7.3.0/bin目录:
Shift+右键 在此处打开命令窗口;

在控制台输入以下命令:
solr start -p 9090

看到Started Solr server on port 9090. Happy searching!表示solr服务已经启动成功,这里是用solr自带的jetty启动的。
接下来我们可以打开浏览器访问:http://localhost:9090/solr/index.html
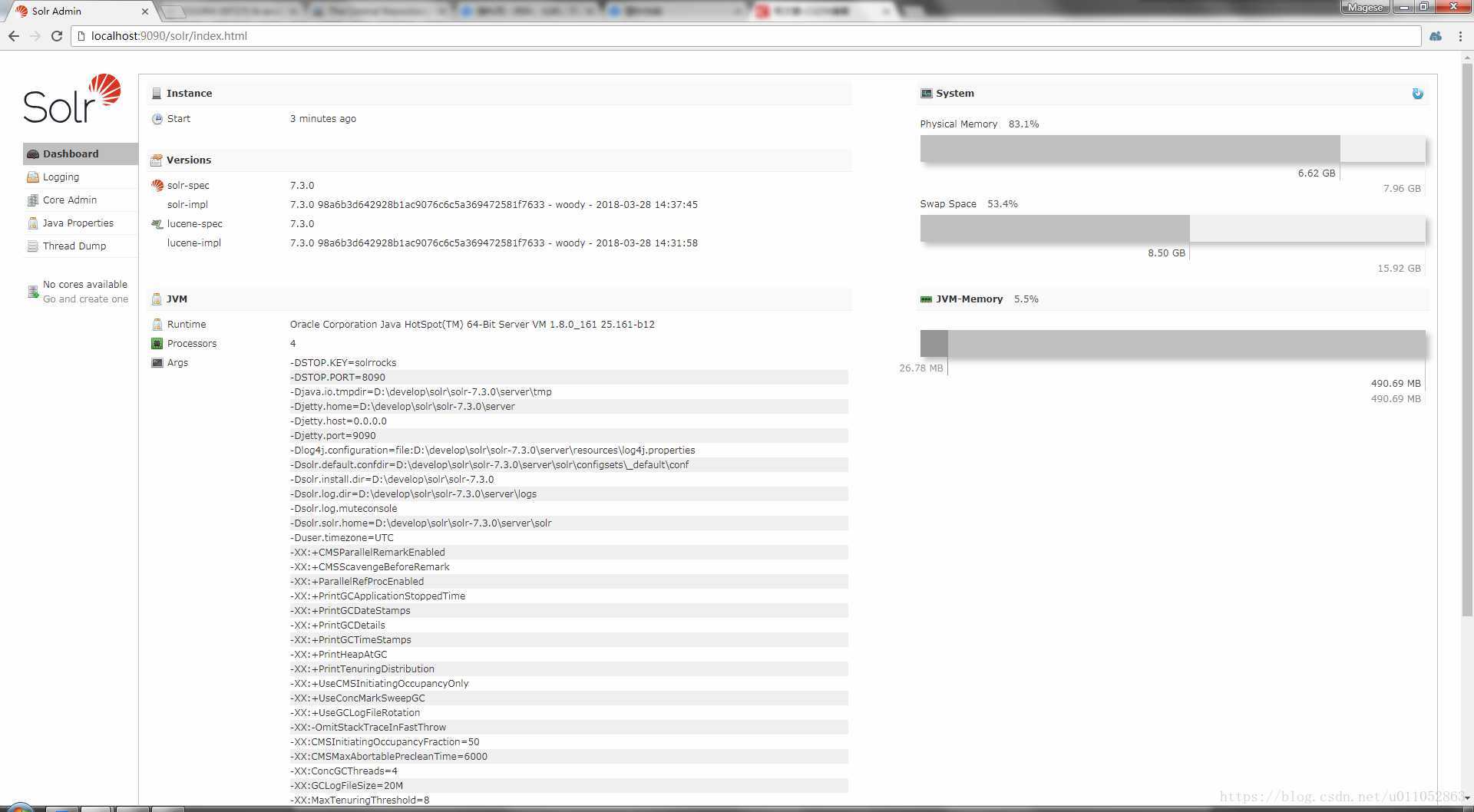
就可以看到solr已经成功启动了。
三、添加solr core
先进入solr-7.3.0/example/example-DIH/solr/solr目录中
将该目录中的conf文件夹与core.properties文件copy

接下来我们进入solr-7.3.0/server/solr目录
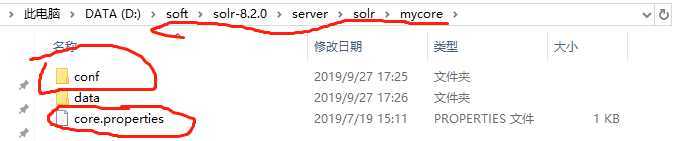
在此目录创建一个文件夹mycore
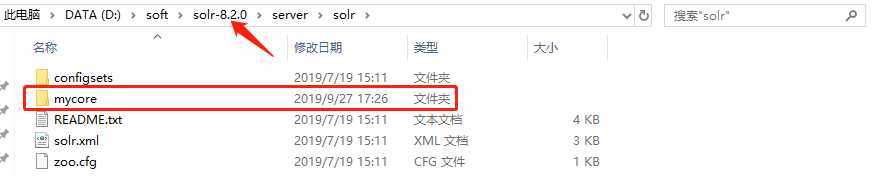
然后我们将上面的conf文件夹和core.properties文件copy到此文件夹中
接下来在之前启动的cmd窗口重启一下solr服务,在控制台输入以下命令:
solr restart -p 9090

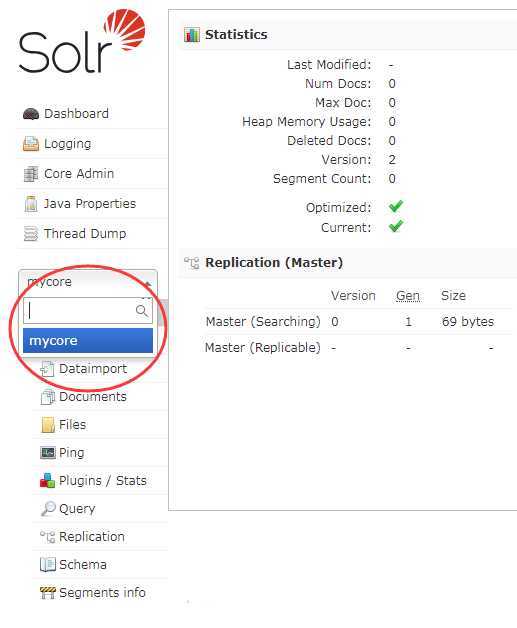
重启完成后刷新一下http://localhost:9090/solr/index.html页面,
发现solr core已经添加成功了
四、配置中文分词器 IK-Analyzer-Solr8
先下载solr8版本的ik分词器,下载地址:https://search.maven.org/search?q=com.github.magese
分词器GitHub源码地址:https://github.com/magese/ik-analyzer-solr8
GitHub上有分词器的使用方式

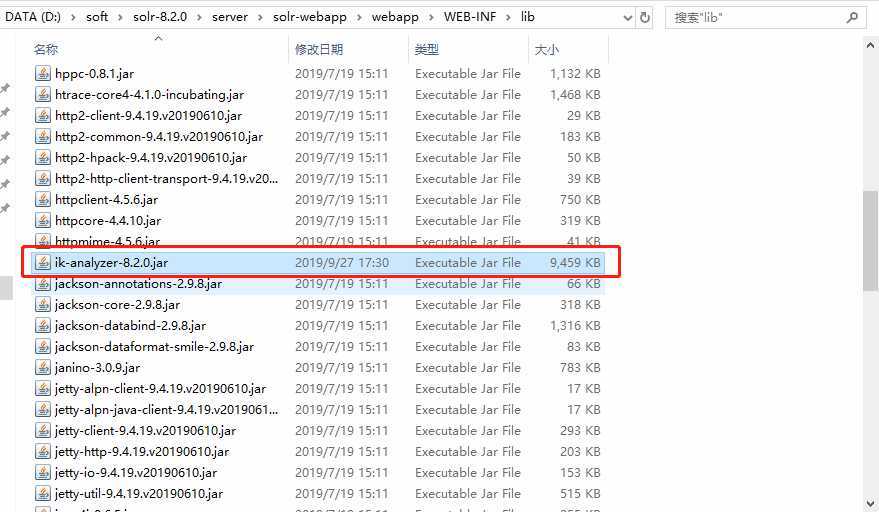
将下载好的jar包放入solr-7.3.0/server/solr-webapp/webapp/WEB-INF/lib目录中
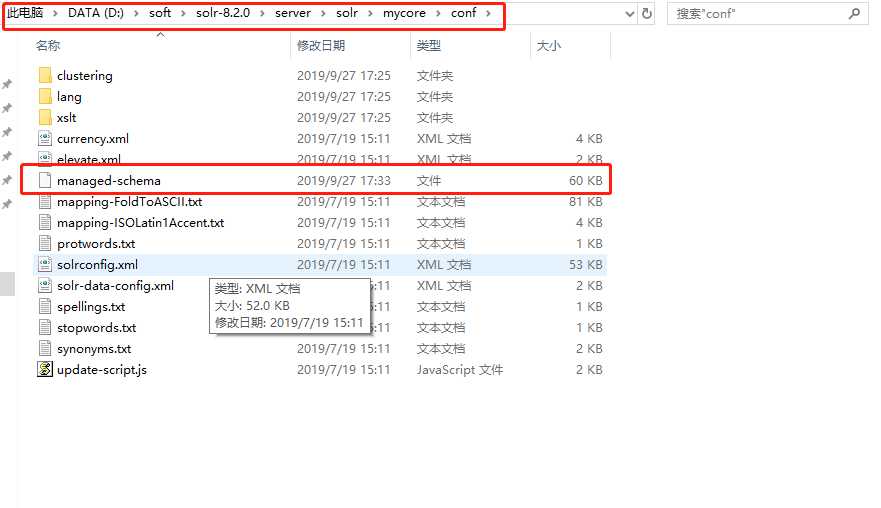
然后到solr-7.3.0/server/solr/mycore/conf目录中打开managed-schema文件
在配置文件中加入以下代码:
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>

配置完成后再次重启一次solr服务
solr restart -p 9090

再次刷新http://localhost:9090/solr/index.html页面
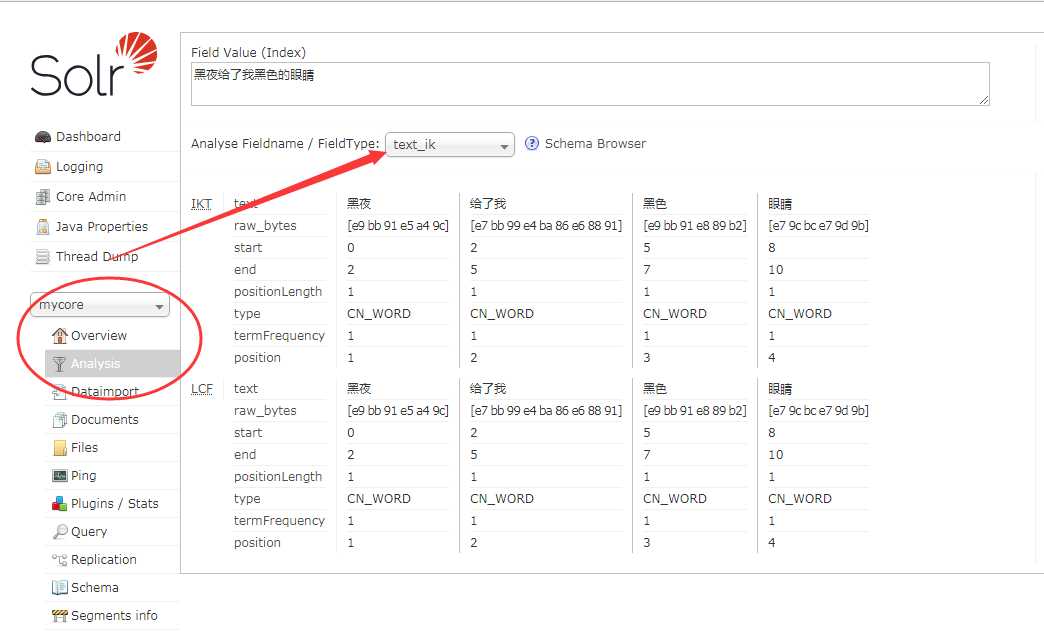
选择mycore -> Analysis -> 选择分词器 text_ik 输入 "黑夜给了我黑色的眼睛"
点击"Analyse Values"按钮可以看到结果已经分词成功了。
solr8.2 环境搭建 配置中文分词器 ik-analyzer-solr8 详细步骤
标签:选择 img field 文件 png values down load name
原文地址:https://www.cnblogs.com/bxcsx/p/11599650.html