标签:切片 建模 其他 机器学习 googl parse 公有 转换 专业
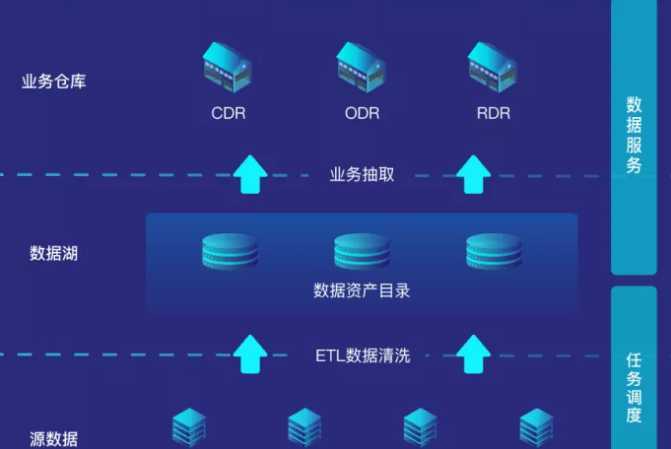
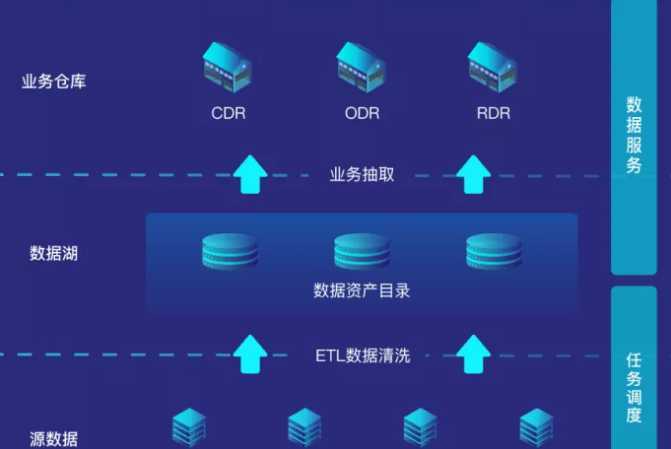
ETL概述
ETL(Extraction-Transformation-Loading)是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据, ETL是BI(商业智能)项目重要的一个环节。
数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。它通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。它的分析方法包括:分类、估计、预测、相关性分组或关联规则、聚类和复杂数据类型挖掘。
首先得有数据,数据的收集有两个方式,第一个方式是拿,专业点的说法叫抓取或者爬取,例如搜索引擎就是这么做的,它把网上的所有的信息都下载到它的数据中心,然后你一搜才能搜出来。
一般会通过队列方式进行,因为数据量实在是太大了,数据必须经过处理才会有用,可是系统处理不过来,只好排好队,慢慢的处理。
现在数据就是金钱,掌握了数据就相当于掌握了钱。要不然网站怎么知道你想买什么呢?就是因为它有你历史的交易的数据,这个信息可不能给别人,十分宝贵,所以需要存储下来。
上面存储的数据是原始数据,原始数据多是杂乱无章的,有很多垃圾数据在里面,因而需要清洗和过滤,得到一些高质量的数据。对于高质量的数据,就可以进行分析,从而对数据进行分类,或者发现数据之间的相互关系,得到知识。
注:第三与第四个步骤,现存后清洗和先清洗再存,在真是的业务场景中可以适当互换。
检索就是搜索,所谓外事问google,内事问百度。挖掘,仅仅搜索出来已经不能满足人们的要求了,还需要从信息中挖掘出相互的关系。
怎么友好的展示与传递给用户为数据挖掘工作做好闭环。
1、针对日志文件类
|
工具 |
定义 |
|
Logstash |
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到所选择的目的地。 |
|
Filebeat |
Filebeat 作为一个轻量级的日志传输工具可以将日志推送到中心 Logstash。 |
|
Fluentd |
Fluentd 创建的初衷主要是尽可能的使用 JSON 作为日志输出,所以传输工具及其下游的传输线不需要猜测子字符串里面各个字段的类型。这样,它为几乎所有的语言都提供库,即可以将它插入到自定义的程序中。 |
|
Logagent |
Logagent 是 Sematext 提供的传输工具,它用来将日志传输到 Logsene(一个基于SaaS 平台的 Elasticsearch API)。 |
|
Rsylog |
绝大多数 Linux 发布版本默认的守护进程,rsyslog 读取并写入 /var/log/messages。它可以提取文件、解析、缓冲(磁盘和内存)以及将它们传输到多个目的地,包括 Elasticsearch 。可以从此处找到如何处理 Apache 以及系统日志。 |
|
Logtail |
阿里云日志服务的生产者,目前在阿里集团内部机器上运行,经过3年多时间的考验,目前为阿里公有云用户提供日志收集服务。 |
关于详解日志采集工具Logstash、Filebeat、Fluentd、Logagent、Rsylog和Logtail在优势、劣势
2、针对爬虫类
页面下载 --> 页面解析 --> 数据存储
(1)页面下载器
对于下载器而言,python的库requests能满足大部分测试+抓取需求,进阶工程化scrapy,动态网页优先找API接口,如果有简单加密就破解,实在困难就使用splash渲染。
(2)页面解析器
①BeautifulSoup(入门级):Python爬虫入门BeautifulSoup模块
②pyquery(类似jQuery):Python爬虫:pyquery模块解析网页
③lxml:Python爬虫:使用lxml解析网页内容
④parsel:Extract text using CSS or XPath selectors
⑤scrapy的Selector (强烈推荐, 比较高级的封装,基于parsel)
⑥选择器(Selectors):python爬虫:scrapy框架xpath和css选择器语法
---------------------
总结:
解析器直接使用scrapy的Selector 就行,简单、直接、高效。
(3)数据存储
①txt文本:Python全栈之路:文件file常用操作
②csv文件:python读取写入csv文件
③sqlite3 (python自带):Python编程:使用数据库sqlite3
④MySQL:SQL:pymysql模块读写mysql数据
⑤MongoDB:Python编程:mongodb的基本增删改查操作
---------------------
总结:
数据存储没有什么可深究的,按照业务需求来就行,一般快速测试使用MongoDB,业务使用MySQL
(4)其他工具
①execjs :执行js
Python爬虫:execjs在python中运行javascript代码
②pyv8: 执行js
mac安装pyv8模块-JavaScript翻译成python
③html5lib
Python爬虫:scrapy利用html5lib解析不规范的html文本
1、DataWrangler
基于网络的服务是斯坦福大学的可视化组设计来清洗和重排数据的.文本编辑非常简单。例如,当我选择大标题为“Reported crime in Alabama”的样本数据的某行的“Alabama”,然后选择另一组数据的“Alaska”,它会建议提取每州的名字。把鼠标停留在建议上,就可以看到用红色突出显示的行。
2、Google Refine
它可以导入导出多种格式的数据,如标签或逗号分隔的文本文件、Excel、XML和JSON文件。Refine设有内置算法,可以发现一些拼写不一样但实际上应分为一组的文本。导入你的数据后,选择编辑单元格->聚类,编辑,然后选择要用的算法。数据选项,提供快速简单的数据分布概貌。这个功能可以揭示那些可能由于输入错误导致的异常——例如,工资记录不是80,000美元而竟然是800,000美元;或指出不一致的地方——例如薪酬数据记录之间的差异,有的是计时工资,有的是每周支付,有的是年薪。除了数据管家功能,Google Refine还提供了一些有用的分析工具,例如排序和筛选。
3、Logstash
Logstash 是一款强大的数据处理工具,它可以实现数据传输,格式处理,格式化输出,还有强大的插件功能,常用于日志处理。
数据存储主要分为结构化数据的存储和非结构化数据的存储。
1、结构化数据
(1)定义
一般指存储在数据库中,具有一定逻辑结构和物理结构的数据,最为常见的是存储在关系数据库中的数据;非结构化数据:一般指结构化数据以外的数据,这些数据不存储在数据库中,而是以各种类型的文本形式存放,其中Web上的一些数据(内嵌于HTML或XML标记中)又具有一定的逻辑结构和物理结构,被称为半结构数据。
(2)存储系统
目前比较成熟的结构化存储系统有Oracle、MySQL、Hadoop等。
2、非结构化数据
(1)定义
非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。包括所有格式的办公文档、文本、图片、XML, HTML、各类报表、图像和音频/视频信息等等。
(2)存储方式
1)使用文件系统存储文件,而在数据库中存储访问路径。这种方式的优点是实现简单,不需要DBMS的高级功能,但是这种方式无法实现文件的事务性访问,不便于数据备份和恢复,不便于数据迁移等;
2)使用阿里云OSS的文件存储功能。
数据计算分为实时计算、在线计算、离线计算。
1、数据实时计算
Apache Storm
2、数据在线计算
Elasticsearch
MySQL
3、数据离线计算
HaDoop Hive
1、对数据矩阵科学计算:Python的numpy库
2、对数据切片等常规处理:强大的pandas库
3、对数据建模处理:sklearn库
1、数据的可视化处理:Python中的matplotlib和seaborn库
2、常用的BI可视化工具:Tableu和帆软
3、ECharts
——————————————
阅读推荐
标签:切片 建模 其他 机器学习 googl parse 公有 转换 专业
原文地址:https://www.cnblogs.com/Javame/p/11599546.html