标签:heapsort square 组成 顺序 turn nump 排列 模块 range
numpy模块内置的函数能够对数组进行复杂而高效的操作,这些函数中都有一个参数axis(轴)。在数组中,轴表示维度,对于二维数组,axis参数的取值通常有:
sort(axis,kind)函数用于对数组进行排序,可以使用类方法numpy.sort(),返回的是数组的已排序的副本,而原始数组并没有改变;也可以使用对象方法obj.sort(),原始数组排序。
numpy.sort(a, axis=1, kind=‘quicksort‘)
参数注释:
举个例子,对数组进行排序:
import numpy as np a = np.array([[1, 2, 1] ,[1,1,0]]) r1=np.sort(a) r2=np.sort(a,axis=0) r3=np.sort(a,axis=1) print(‘a.sort() = {0}\na.sort(axis=0) = {1}\na.sort(axis=1) ={2}‘.format(r1,r2,r3))
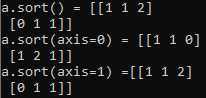
argsort()函数返回的是按照数组值从小到大的索引值,即返回的是索引值,索引值是按照元素值从小到大得到的。
x=np.array([1,4,3,-1,6,9]) y=np.argsort(x) #output array([3, 0, 2, 1, 4, 5], dtype=int64)
元素-1的值是最小的,其索引是3,因此,argsort()的返回列表中是第一个item。
argsort()函数是将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y,按照降序排序:
y=np.argsort(-x)
按照升序排序:
y=np.argsort(x)
numpy.vectorize()函数定义一个向量化函数,它以序列或numpy数组作为输入,对numpy数组做向量化操作。函数输出的数据类型是由otypes参数确定的,如果otypes=None,那么输出的数据类型是通过使用输入的第一个元素调用函数来确定的,该函数返回一个函数对象。
numpy.vectorize(pyfunc, otypes=None, doc=None, excluded=None, cache=False, signature=None)
参数注释:
使用vectorize()定义一个向量化函数,对数组做向量化操作:
def myfunc(a, b):
return a-b if a>b else a+b
vfunc = np.vectorize(myfunc)
vfunc([1, 2, 3, 4], 2)
#output array([3, 4, 1, 2])
reshap(array,newshape) :返回一个给定shape的数组的副本,例如,下面的代码把一个一维数组转换为4行2列的二位数组:
a=np.arange(8) np.reshape(a,(4,2))
返回展平数组,原数组不改变
a=np.arange(8) b=np.reshape(a,(4,2)) b.flatten()
numpy计算元素的和/积,在语法上相似。
1,求和
numpy对象的函数:sum(axis)
参数axis是轴,对于二维数组,axis的取值有None、0和1:
举个例子,创建一个二维数组,按照行和列分别求和:
import numpy as np a = np.array([[0, 2, 1] ,[0,1,0]]) r1=a.sum() r2=a.sum(axis=0) r3=a.sum(axis=1) print(‘a.sum() = {0}\na.sum(axis=0) = {1}\na.sum(axis=1) ={2}‘.format(r1,r2,r3))
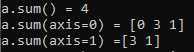
2,求积
计算元素的积:prod(axis)
参数axis是轴,对于二维数组,axis的取值有None、0和1:
举个例子,创建一个二维数组,按照行和列分别求乘积:
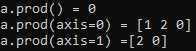
import numpy as np a = np.array([[1, 2, 1] ,[1,1,0]]) r1=a.prod() r2=a.prod(axis=0) r3=a.prod(axis=1) print(‘a.prod() = {0}\na.prod(axis=0) = {1}\na.prod(axis=1) ={2}‘.format(r1,r2,r3))
对numpy对象计算,常用的统计量是:
举个例子,计算数组的均值:
import numpy as np a = np.array([[1, 2, 1] ,[1,1,0]]) r1=a.mean() r2=a.mean(axis=0) r3=a.mean(axis=1) print(‘a.mean() = {0}\na.mean(axis=0) = {1}\na.mean(axis=1) ={2}‘.format(r1,r2,r3))

计算数组中最大值和最小值的索引:
举个例子,返回数组中最小值的索引:
import numpy as np a = np.array([[1, 2, 1] ,[1,1,0]]) r1=a.argmin() r2=a.argmin(axis=0) r3=a.argmin(axis=1) print(‘a.argmin() = {0}\na.argmin(axis=0) = {1}\na.argmin(axis=1) ={2}‘.format(r1,r2,r3))
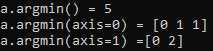
使用 numpy.linspace() 创建等差数列函数
numpy.linspace(start, stop[, num=50[, endpoint=True[, retstep=False[, dtype=None]]]]])
返回在指定范围内的均匀间隔的数字(组成的数组):
>>> import numpy as np >>> np.linspace(-3,3,11) array([-3. , -2.4, -1.8, -1.2, -0.6, 0. , 0.6, 1.2, 1.8, 2.4, 3. ])
按照bins(顺序)分箱数组,把数据点划分到不同的分箱中,并返回分箱的索引:
numpy.digitize(data,bins)
numpy.random模块是对Python内置的random的升级,增加了一些用于搞笑生成多种概率分布的样本值的函数。
常用的numpy.random模块的函数:
例如,使用normal得到一个标准正态分布的4x4样本数组:
samples=np.random.normal(size=(4,4))
参考文档:
标签:heapsort square 组成 顺序 turn nump 排列 模块 range
原文地址:https://www.cnblogs.com/ljhdo/p/10275607.html