标签:不同 阿里巴巴 网上 request 基本 表示 工具 它的 电脑
爬虫
一、认识爬虫
1、概念
口语化定义:网络爬虫,程序,自动,批量,下载网络资源。专业角度:伪装成客户端与服务端进行数据交互的程序
2.相关概念
2.1应用架构(软件的结构是什么样子的)
- c /s client server 客户端,服务端架构(比如lol,qq)
- b /s browser 浏览器服务器架构(各种网站)
- m /s mobile 移动端,服务端(手机app)
那么客户端和服务端怎么传数据呢?他们有协议
2.2 http协议
超文本传输协议(从服务器传输超文本信息到客户端,客户端是没有数据的,数据在服务端,打开一个网页,数据通过http协议从服务器下载回来,整个互联网90%的数据都是基于http协议)
一个完整的http事务包含以下几个流程
1. 输入网址,dns(域名解析成ip,ip就是我们电脑在互联网上的地址,唯一的,在dns上找到域名,解析成我们需要的ip,找到我们的服务器)
2. TCP连接,三次握手(建立好连接,建立好通道)
3. 客户端发送HTTP请求报文
4.服务端收到请求,处理请求,返回一个包含结果的响应
5.浏览器 (根据收到信息的不同)渲染和展示
特点
- http无连接 每次只处理一个请求(非常快速,每个请求都是完整的)
- http媒体独立
- http无状态(连续两次请求区分不了是两个用户还是一个用户)
2.2.1 请求(request)
一个完整的http请求报文报文包含:请求行,请求头,空行,请求数据/请求体
1.请求方法
1.0 GET(没有请求体,最多只能发送1024字节) POST HEAD
1.1 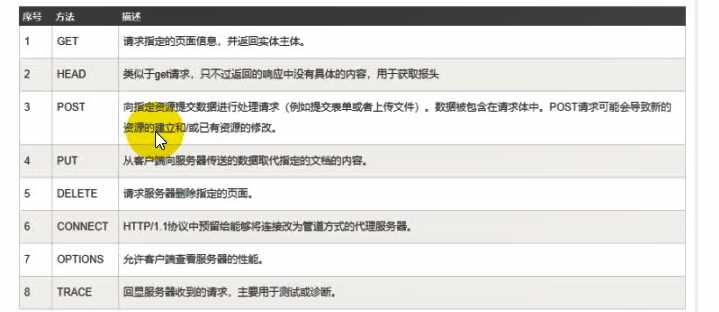
GET 获取数据(查)
POST 用户账号密码(增)
PUT(改)
DELETE(删)
2. 请求头
‘名称+:+值’
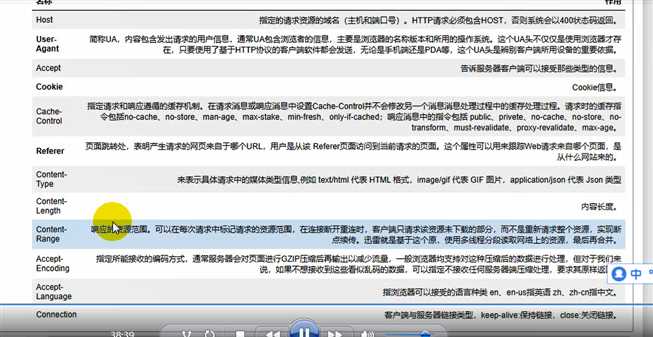
Host 指定的请求资源域名(主机和端口号)400代表连不上
UA 指定我是用什么软件给你发送的,我是什么客户端,我是用电脑还是手机,甚至我是用华为的手机还是苹果的手机,微博上面回复一条显示什么手机
Acceept
cookie http是无状态的,但是我们现在又要他能够去把不同的请求,能够把一个客户端的不同请求联系在一起用到的技术
3. 请求体/请求数据
二进制,b‘‘ 。GET没有,请求头和请求体一定要有个空行,不然解析不了
2.2.2 响应
一个完整的响应报文包含:状态行,消息报头,空行,响应正文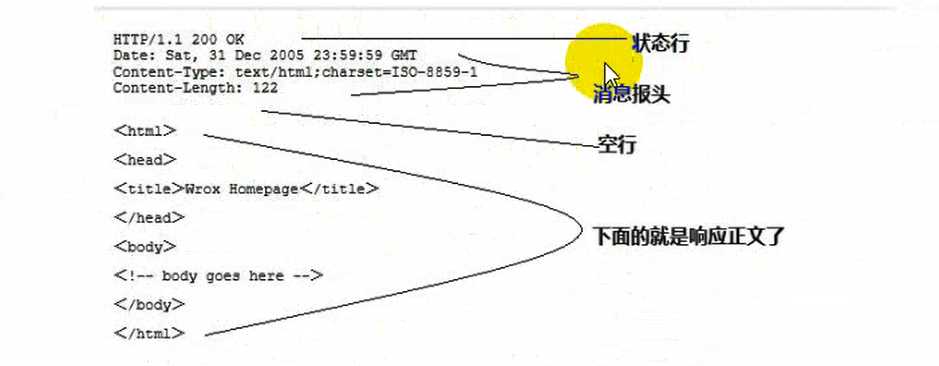
http响应状态码
让你快速知道当前响应是个什么情况,描述了响应的结果
1开头的一般看不到
3开头的重定向,打开一个网站的时候,输入用户名和密码,有些网站会跳转,服务端会告诉你一个标志,你需要跳到另外一个页面
4开头的代表我们的代码有问题,看下域名写对了没有,看下参数写对了没有,代表客户端错误
5开头代表服务器错误
一般用2、3、4、5,1一般不怎么用
响应报头(了解)
Allow
Date
Set-Cookie
Content-Type
2.2.3 会话技术(了解)
http是无状态的,服务器不知道连发两个请求不知道都是你,怎么把他联系在一起,怎么区分一个用户的连续请求
cookie,session
cookies (了解)(复数,不止一个cookie)
一个用户请求我的服务端,首先我的服务端检测你有没有,没有没关系,我在响应里面有个Set-Cookie,给你设置cookie,浏览器在接到这个响应之后,看到这个Set-Cookie之后,他会把你设置的这个cookie记录下来,浏览器会帮你保存这个信息,帮你把这个信息会保存在电脑上面,下次再请求这个网站时,浏览器就会检测看你有没有cookie,有就会把它带上,从而解决了这个问题 案例
凭证,保存在客户端 不安全,数据太大时响应变慢,所以发明了session
session 会话(指打个电话,拨通,讲完之后挂掉,这叫一次会话)在web这个领域,session什么意思呢,其实就是打开浏览器,访问某一个网站,在这个网站上点点点点点点,最后关闭这个网站,关闭这个浏览器,整个一个过程就叫做session,就叫一次会话基于cookie,session把数据 保存在服务端(不同的框架,不同的人实现的时候不一样,有人会把session存在数据库,有人会把session放在内存里面,有人会把session信息存在文件)
session是怎么运作的?
简单理解,我在服务器,维持一个大字典,每个客户的信息我用这个大字典来表示,我给每个客户生成一个cookie,叫做session ID,生成一个随机的,独立的字符串,每一次只要把这个session ID携带过来就可以了,你登录的时候我就在我的字典里面去新建一个字典,这个字典的key就是session ID,然后把你的值放到那个你的session ID对应的那个字典里面,那我可以存很多信息,这个时候我的信息,我的用户名和密码我不会存在里面,即使被窃取了,也无非是别人能够登陆一下,但是我们支付又要输密码,没办法去绕过,无形中比cookie安全高了很多,另外我存储信息也可以存的多一点,我不需要传给你,你只需要发一个session ID给我,一个session ID最多64字节
2.2.4 网络资源
可以通过互联网去获取网页、图片,音频、视频、媒体文件意见其他文件的集合的总称
爬虫的目标,定位
2.2.5 URL
统一资源定位符,网址,标识互联网上某一处网络资源的地址

没有用默认端口,需要显示的写上,他的端口不是80,那就必须在域名的后面加上‘:8080’
/开始到?前面代表的是路径,你是要干什么,你是要首页面还是要登录页面,还是要登录,还是要注册,还是要付款你就通过后面这个路径去区分,我们刚才说的那个cookie,他会根据这个进行区分
路径参数,在URL里面我们可以带上这个参数,这个参数可以在服务器解析,一般情况下这个参数是用来做查询参数的,如果要传大量的数据要放在请求体里面
用来标识资源在互联网上的位置,前面代表协议,我这个资源要通过这个协议可以访问,在哪里呢,这个域名和端口就会指向这台计算机,什么信息呢,通过这个路径就指定这个信息,需要哪些参数,后面加上参数,举个例子,我要访问互联网上的某张图片
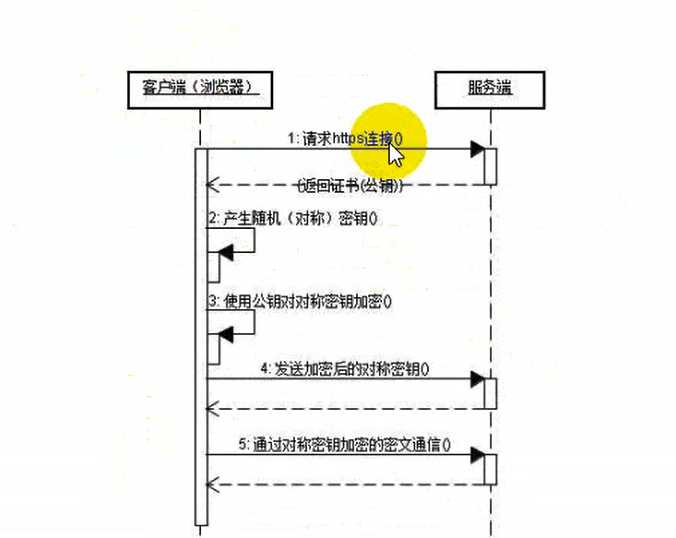
2.3 https 超文本传输安全协议
http有个非常大的缺点,http发送的时候数据都是明文的,没有加密的
ssl?TLS协议 依托于http的,只不过是在http传送的过程中他把数据进行了加密,仅此而已
与http的区别
1.https需要申请证书 - ca证书
2.http是明文的,https加密
3.连接方式:http 80 端口 https 443端口
端口: 我们一个电脑上有很多程序,每个程序他要访问网络的时候公用一个id,怎么区分不同的软件,怎么区分不同的请求,就通过端口
4.
3. 应用领域
3.1 数据采集
淘宝,阿里巴巴,腾讯,百度,华为这种大公司大平台,他们的数据,他们其实有很多免费的,比如说百度有很多免费的服务其实你是付了费的,付了什么费呢,有你的信息,像很多论坛啊,免费的,你觉得你是免费的时候,当然你也是免费的,他也是提供了服务给你,其实这些大公司的布局都是获取用户数据,对于大公司来说,他有自己的平台,有自己的渠道能够拿到数据,那很多中小企业怎么办呢?两个办法,第一个就是买,找大公司去买数据,我和腾讯合作,我和阿里巴巴合作,比如说电商平台和阿里巴巴去合作,搞一个淘宝直通车,广告费用。还有个渠道呢,在很长一段时间就是个爬虫,比如去爬淘宝的商品,你要去爬饿了么,爬美团都有
3.2 搜索引擎
谷歌 它发展起来,最开始就是一个爬虫,发展到现在一个世界级的顶尖的公司,谷歌公司叫做‘’程序员的殿堂‘’如果你有谷歌公司的工作经验,你在国内BAT这种公司你就随便进,如果你有BAT的工作经验,一般的其他企业你也随便进,对不对。谷歌公司最开始其实就是一个爬虫,百度他的搜索也就是一个爬虫,所有的搜索引擎其实都是爬虫,他不停的在互联网上不分日夜的到处去爬,他抽象把互联网当做一个节点这样一个网络,爬虫程序在里面,这样去形象的去比喻,把别人网站的信息收入到自己的数据库,比如说你搜索一个图片,所有图片相关的网站通通都会搜索出来,他在早期怎么做呢,他就是去根据你那个,他的爬虫有个规则啊,他不会爬你整个网页,他只会爬你的头部,我们打开一个网页的时候
他这里有个meta,它这里面有 很多的信息。
3.3 模拟操作
有时候我们一些重复的劳动,我们都知道现在要智能化,自动化,有灌水机器人,以前论坛里面要灌水嘛,要把帖子给顶上去,一下子几十万哪里找这么多人,虽然说有水军,但是这个水军要钱的,技术人员通过写爬虫模拟用户去登录,去发帖子。还有测试的,软件行业搞测试的,写好一个软件,在发布的时候需要去做各种测试,自动化测试。12306抢票程序,通过爬虫我可以实现,设定好时间,设定好我去哪里,买哪趟车,这个程序帮我自动运行,帮我去抢票,这个也是爬虫。
二、开发流程
1.分析请求流程
2. 发送请求
3. 获取响应内容
4. 解析内容
5. 数据持久化
1. 分析请求流程
目的:找到目标资源的http请求。具体指标:
1. 请求方法
2. url
3. 请求头
4. 请求数据(参数)
1.1 工具(抓包)
1.1.1 fiddler
1.1.2 谷歌浏览器
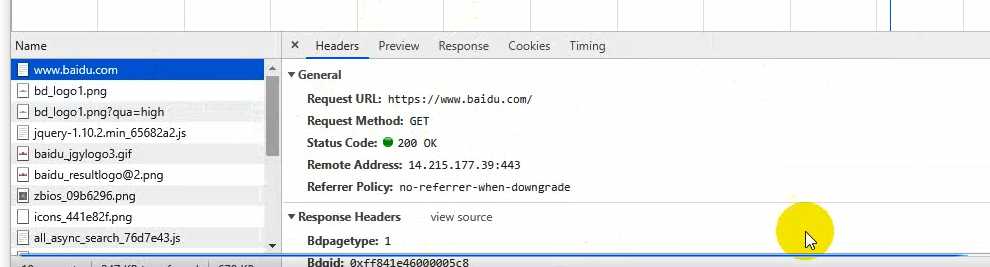
基本上我们写的爬虫80%以上用谷歌浏览器就足够,提供了一个开发者调试工具,能对我们的http请求进行监控,按下F12打开,Network点开,输入网站一回车,分析网页结构就用Elements,分析页面用Network,下面的每一条都是一次http事务。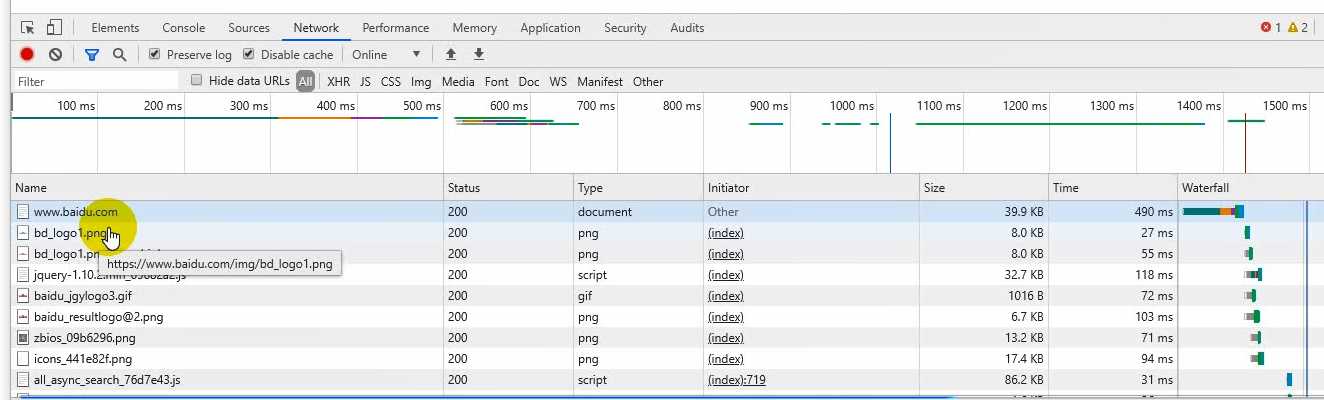
右边是请求的详细信息,Headers是头部信息,Preview是对结果的渲染,这里为什么是白板呢?我这里要跟大家讲个概念,一个网页并不是一次请求就可以搞定的,现阶段的网站一个页面他不可能是一个html,(在互联网的古时候那个时候都是静态页面,一个网页就是一个请求),一个页面在加载的时候不止一个请求,然后请求也有先后顺序。Response是第一次响应回来的数据
2. 发送请求
2.1 通过socket 发送HTTP请求
from socket import socket
创建客户端
client = socket()
连接服务端
client.connect((‘www.baidu.com‘,80))
构建http请求报文
data = b‘GET / HTTP/1.0\r\nHost: www.baidu.com\r\n\r\n‘
发送报文
client.send(data)
接受响应
res = ‘b‘
temp = client.recv(1024)
print(‘*‘*20)
while temp:
res +=temp
temp = client.recv(1024)
print(res)
client.close()
2.2 工具库
1.urllib python的标准库,网络请求的
2. urllib3 基于python3
3. requests
这个库使得爬虫泛滥,间接导致很多网站的反爬技术不断升级,使用这个equests库可以非常简单的,毫无门槛的去下载很多很多的资源
2.2.1 requests
特点,专为人类而构建,是优雅和简单的python库,也是有史以来下载次数做多的python软件包之一。
3.获取响应内容
3.1 利用socket 下载一张图片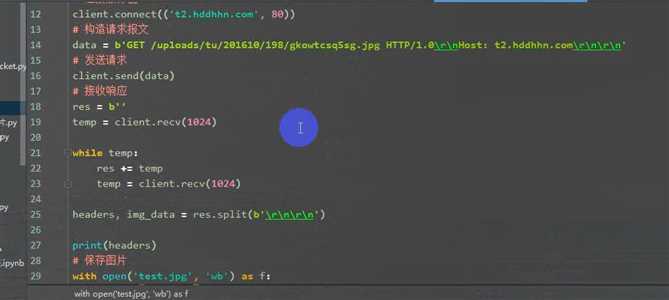
3..2 requests下载
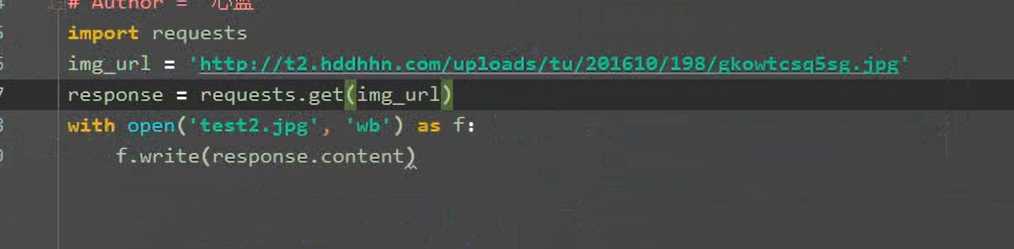
4. 解析内容
响应体:一个是文本,还有个是二进制数据
文本:html,json,(js,css)
4.1 html 解析
4.1.1 正则表达式
4.1.2 beautiful soup
4.1.3 xpath
4.2 json 解析
4.2.1 jsonpath
我们写爬虫的时候有很大一部分工作需要去解析,对数据进行解析,然后提取我们需要的内容
5. 数据持久化
1. 写文件
二进制数据,少量的一般情况下都是写文件,比如下载图片,mp3,下载视频,变成文件存回来
2. 写数据库
有大量的文本数据,结构性的,存到数据库,比如说查某个商品的销售数据,网上找论文,小说,下载整个网站的小说要把它存到数据库
三、重点和难点
1. 数据获取
有很多反爬措施,反爬技术突飞猛进
1.1 请求头反爬
比如只要浏览器访问,加一个UA,基本上没有用,处理起来非常方便
1.2 cookie
cookie 处理起来也不难,requests已经帮我们做了cookie 处理了
1.3 验证码
点触、图形、字符、滑动、短信、语音验证码等等,有的验证码是破解不了的,验证码的处理上面难度非常大,在需要登录或者验证码的处理上其实是一个比较难的地方
1.4 行为检测
机器学习,通过对用户的行为,比如点击频率,网页的停留时间,他会进行学习,然后通过这些指标,通过一些模型来判断这个是一个爬虫还是一个人,这个的难点在你要发现它的规则,也就是他通过什么去判断。举个简单例子,比如时间间隔,爬虫一般你设定的是比如每秒钟它去爬一次,他就每秒钟,分毫不差,但是人点击时间是随机的,为了处理这个,我就在每次爬取的时候在中间加个随机值,随机休眠一段时间我再去爬,就可以解决这个问题。
1.5 参数加密
比较困难,需要去研究,去调试它的gs,看他是用什么方法去加密的数据,需要足够的耐心去gs调试和分析
1.6 字体反爬
爬不到具体的数字,每次自定义的字体,需要去学习相应的字体,把关键的字用自己的字体,比较困难
2. 爬取效率
2.1 并发
你在你的电脑上同时运行多个程序
2.2 异步
2.3 分布式
爬虫会检测ip,如果同一个IP访问次数过多,我就觉得你有可能有问题,我可能会封你的ip,这个时候就需要分布式,你把你的爬虫在不同的电脑上,部署在不同的主机上面去运行,去爬取
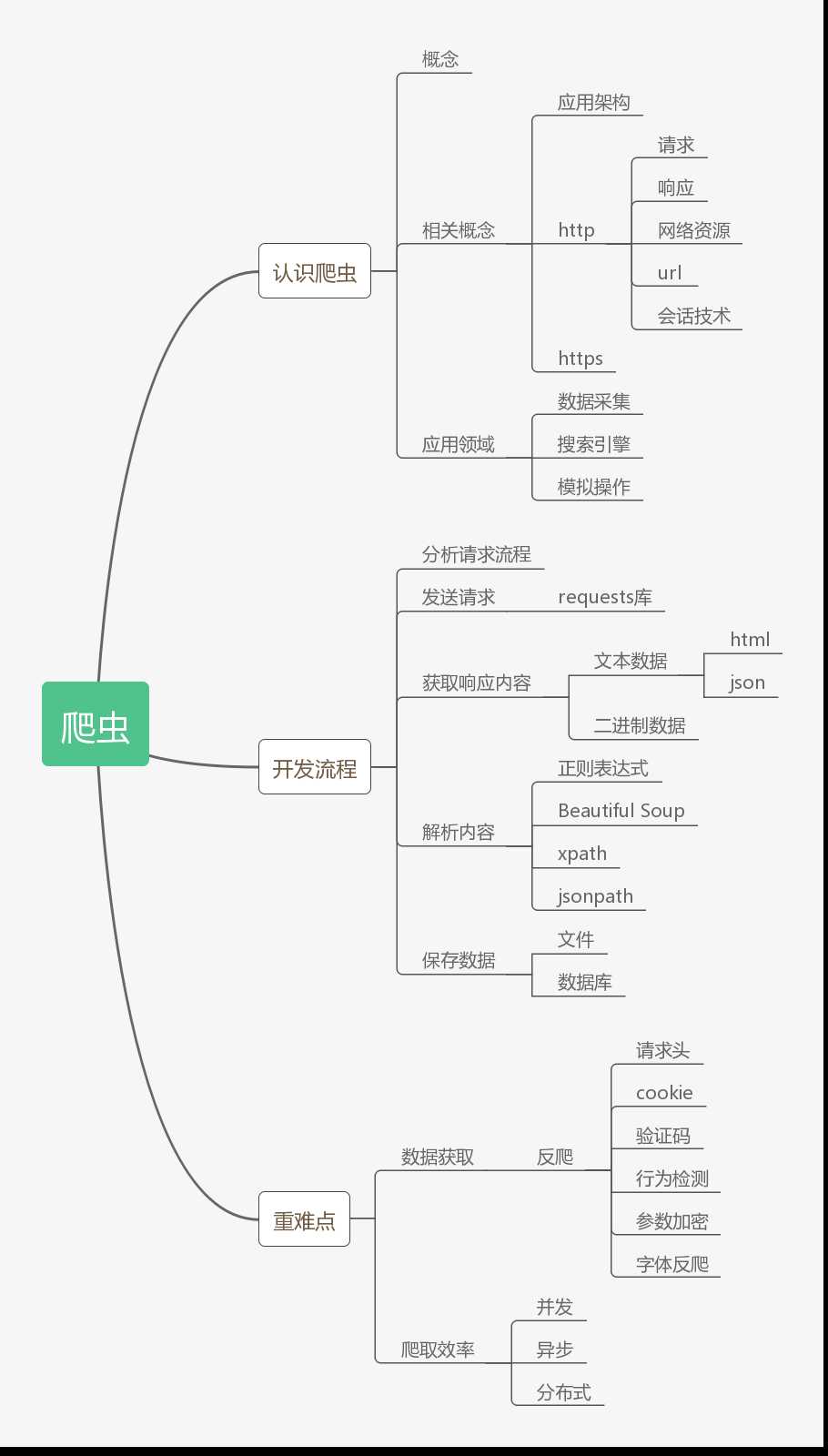
总结如下:
标签:不同 阿里巴巴 网上 request 基本 表示 工具 它的 电脑
原文地址:https://www.cnblogs.com/LWH999/p/11600953.html