标签:nop 机制 道路 权限错误 运行时 继承 比较 eof 自定义类
本文索引
golang1.13发布已经有一个月了,本文将会列举其中几个较为重要的特性。我们将会从语言变化、库变化以及工具链的改进这三方面逐个介绍新版本中引入的新特性。
go团队一直承诺1.x版本的向前兼容,所以虽然1.13作为第一个开始向go2过渡的版本,其引入的语言变化是极少的,主要只有这两点:更多的数字字面量和改进的panic信息。
数字字面量是大家再熟悉不过的东西了,比如100,0.99,1.等。
然而奇怪的是,1.13之前的golang仅支持10进制和16进制的字面量,而在其它语言中广泛支持的二进制和八进制却不受支持。例如下面的代码是无法编译的:
fmt.Println(0b101)
fmt.Println(0o10)在go1.13中上述字面量语法已经被支持了你可以通过0b或0B前缀来表明一个二进制数字的字面量,以及用0o和0O来表明八进制字面量。值得注意的是虽然两种写法都可以,但是gofmt默认会全部转换为小写,所以我更推荐使用0b和0o使你的代码风格尽量统一。
数字字面量的另一个变化就是引入了16进制浮点数的支持。
16进制浮点数是按照16进制来表示浮点数的方法,需要注意的是这里指的不是将浮点数表示为对应二进制值的16进制形式,而是形式如下的16进制数字:
0X十六进制整数部分.十六进制小数部分p指数其中整数和小数部分和普通浮点字面量一样可以省略,省略的部分默认为0。p+指数的部分不可省略,指数可以有符号,它的值是2的指数。
一个16进制浮点字面量最终的结果,假设p之前的部分的值为a,p后的指数是b,最终的值如下:a * 2^b。
看上去和科学计数法很像,事实上也就是把e换成了p,指数计算从10变为了2。另外因为是每16进1,所以0x0.1p0看上去像0.1,然而它表示的是1/16,而0x0.01p0则是1/16的1/16,初见会不太直观,但是习惯后就不会有什么问题了。举点例子:
二进制和八进制字面量是比较常用的,那16进制浮点数呢?答案是更高的精度和统一的表达。
0x0.1p0表示的十进制值是0.0625,而0x0.01p0是0.00390625,已经超过了float32的精度范围,所以16进制浮点字面量可以在有限的精度范围内表示更精确的数值。统一表达自然不用多解释,习惯16进制表达的开发者更乐于使用类似形式。
具体的示例可以参考这里。
最后对于数字字面量还有一个小小的改进,那就是现在可以用下划线分隔数字增加可读性。举个例子:
fmt.Println(100000000)
fmt.Println(1_0000_0000)
fmt.Println(0xff_ff_ff)分隔符可以出现在任意位置,但是像0x之类的算是一个完整的符号的中间不可以插入下划线,分隔符之间字符的数量没有规定必须相等,但为了可读性最好按照现有的习惯每3个数字或四个数字进行一次分隔。
虽然我将其归为语言变化,但事实上将其定义为运行时改进更为恰当。
众所周知golang对数组和slice的越界引用是0容忍的,一旦越界就会panic,例如下面的例子:
package main
import "fmt"
func main() {
arr := [...]int{1,2,3,4,5}
for i := 0; i <= len(arr); i++ {
fmt.Println(arr[i])
}
}如果运行这个程序那么你会收到一个不短的抱怨:
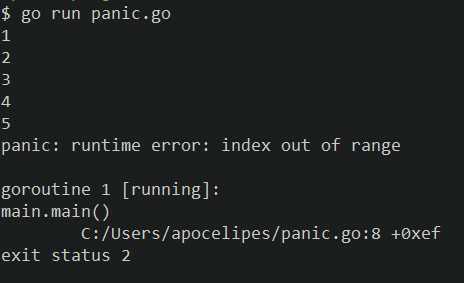
这里的例子很简单,所以调用堆栈信息追溯起来不是很困难,可以方便得定位问题,但如果调用链较深或者你处于一个高并发程序之中,事情就变得麻烦了,要么依赖日志调试并最终分析排除大量杂音来定位问题,要么依赖断点进行单步调试,无论哪种都需要耗费大量的精力,而核心问题只是我们想直到为什么会越界,再浅一步,我们有时候或许只要知道导致越界的值就可以大致确定问题的原因,遗憾的是panic提供的信息中不包含上述内容,直到golang1.13。
现在golang会将导致越界的值打印出来,无疑是雪中送碳:
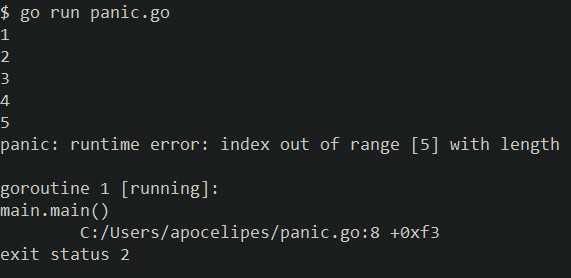
当然,panic信息再完善也不是灵丹妙药,完善的单元测试和严谨的工作态度才是bug最好的预防针。
语言层面的变动不是很大,但工具链就不一样了,除了去除了godoc程序,最大的变化仍旧集中在go modules上。
这次golang加入了三个环境变量来共同控制modules的行为,下面分别进行介绍。
其实这个变量在1.12中就引入了,这次为其加上了默认值https://proxy.golang.org,direct,这是一个逗号分隔的列表,后面两个变量的值和它相同,其中direct表示不经过代理直接连接,如果设置为off,则进制下载任何package。
在go get等命令获取package时,会从左至右依次查找,如果都没有找到匹配的package,则会报错。
proxy的好处自然不用多说,它可以使国内开发者畅通无阻地访问某些国内环境无法获取的包。更重要的是默认的proxy是官方提供和维护的,比起第三方方案来说安全性有了更大的保障。
这个变量实际上相当于指定了一个由官方管理的在线的go.sum数据库。具体介绍之前我们先来看看golang是如何验证packages的:
这个机制是建立在本地的cache在整个开发生命周期中不会变动之上的(因为依赖库的版本很少会进行更新,除非出现重大安全问题),上述机制可以避免他人误更新依赖或是本地的恶意篡改,然而现在更多的安全问题是发生在远程环境的,因此这一机制有很大的安全隐患。
好在加入了GOSUMDB,它的默认值为“sum.golang.org”,国内部分地区无法访问,可以改为“sum.golang.google.cn”。现在的工作机制是这样的:
安全性得到了增强。
最后要介绍的是GOPRIVATE,默认为空,你可以在其中使用类似Linux glob通配符的语法来指定某些或某一类包不从proxy下载,比如某些rpc套件自动生成的package,这些在proxy中并不会存在,而且即使上传上去也没有意义,因此你需要把它写入GOPRIVATE中。
还有一个与其类似的环境变量叫GONOPROXY,值的形式一样,作用也基本一样,不过它会覆盖GOPRIVATE。比如将其设为none时所有的包都会从proxy进行获取。
从这些变化来看go团队始终在寻找一种能细粒度控制的统一的包管理解决方案,虽然目前和npm、pypi还有巨大的差距,但仍不失为成功道路上的坚实一步。
每次新版本发布都会给标准库带来大把的新功能新特性,这次也不例外。
本节会介绍一个小的新功能,以及一个重要的新变化。
golang中任何类型的0值都有明确的定义,然而遗憾的是不同的类型0值不同,特别是那些自定义类型,如果你要判断一个变量是否0值那么将会写出复杂繁琐而且扩展困难的代码。
因此reflect中新增了这一功能简化了操作:
package main
import (
"fmt"
"reflect"
)
func main() {
a := 0
b := 1
c := ""
d := "a"
fmt.Println(reflect.ValueOf(a).IsZero()) // true
fmt.Println(reflect.ValueOf(b).IsZero()) // false
fmt.Println(reflect.ValueOf(c).IsZero()) // true
fmt.Println(reflect.ValueOf(d).IsZero()) // false
}当然,反射一劳永逸的代价是更高的性能消耗,所以具体取舍还要参照实际环境。
其实算不上革新,只是对现有做法的小修小补。golang团队始终有觉得error既然是值那就一定得体现value的equal操作的怪癖,所以整体上还是很怪。
首先要介绍错误链(error chains)的概念。
在1.13中,我们可以给error实现一个Unwrap的方法,从而实现对error的包装,比如:
type PermError {
os.SyscallError
Pid uint
Uid uint
}
func (err *PermError) String() string {
return fmt.Sprintf("permission error:\npid:%v\nuid:\ninfo:%v", err.Pid, err.Uid, err.SyscallError)
}
func (err *PermError) Error() string {
return err.String()
}
// 重点在这里
func (err *PermError) Unwrap() error {
return err.SyscallError
}假设我们包装了一个基于SyscallError的权限错误,包括了所有因为权限问题而触发的error。String和Error方法都是常规的自定义错误中会实现的方法,我们重点看Unwrap方法。
Unwrap字面意思就是去包装,也就是我们把包装好的上一层错误重新分离出来并返回。os.SyscallError也实现了Unwrap,于是你可以继续向上追溯直达最原始的没有实现Unwrap的那个error为止。我们称从PermError开始到最顶层的error为一条错误链。
如果我们用→指向Unwrap返回的对象,会形成下面的结构:
PermError → os.SyscallError → error
还可以出现更复杂的结构:
A → Err1 ___________
|
V
B → Err2 → Err3 → error
这样无疑提升了错误的表达力,如果不想自己单独定义一个错误类型,只想附加某些信息,可以依赖fmt.Errorf:
newErr := fmt.Errorf("permission error:\npid:%v\nuid:\ninfo:%w", pid, uid, sysErr)
sysErr == newErr.(interface {Unwrap() error}).Unwrap()fmt.Errorf新的占位符%w只能在一个格式化字符串中出现一次,他会把error的信息填充进去,然后返回一个实现了Unwrap的新error,它返回传入的那个error。另外提案里的Wrapper接口目前还没有实现,但是标准库用了我在上面的做法暂时实现了Wrapper的功能。
因为错误链的存在,我们不能在简单的用等于号基于判断基于值的error了,但好处是我们现在还可以判断基于类型的error。
为了能继续让error表现自己的值语义,errors包里增加了Is和As以及辅助它们的Unwrap函数。
errors.Unwrap会调用传入参数的Unwrap方法,As和Is使用它来追溯整个错误链。
像上一小节的代码就可以简化成这样:
newErr := fmt.Errorf("permission error:\npid:%v\nuid:\ninfo:%w", pid, uid, sysErr)
sysErr == errors.Unwrap(newErr).Unwrap()我们提到等于号的比较很多时候已经不管用了,有的时侯一个error只是对另一个的包装,当这个error产生时另一个也已经发生了,这时候我们只需要比较处于上层的error值即可,这时候你就需要errors.Is帮忙了:
newErr := fmt.Errorf("permission error:\npid:%v\nuid:\ninfo:%w", pid, uid, sysErr)
errors.Is(newErr, sysErr)
errors.Is(newErr, os.ErrExists)你永远也不知道程序会被怎样扩展,也不知道error之间的关系未来会怎样变化,因此总是用Is代替==是不会犯错的。
不过凡事总有例外,例如io.EOF就不需要使用Is去比较,因为它程序意义上算不上是error,而且一般也不会有人包装它。
除了传统的基于值的判断,对某个类型的错误进行处理也是一个常见需求。例如前文的A,B都来自error,假设我们现在要处理所有基于这个error的错误,常见的办法是switch进行比较或者依赖于基类的多态能力。
显而易见的是switch判断的做法会导致大量重复的代码,而且扩展困难;而在golang里没有继承只有组合,所以有运行时多态能力的只有interface,这时候我们只能借助错误链让errors.As帮忙了:
// 注意As的第二个参数只能是你需要判断的类型的指针,不可以直接传一个nil进去
var p1 *os.SyscallError
var p2 *os.PathError
errors.As(newErr, &p1)
errors.As(newErr, &p2)如果p1和p2的类型在newErr所在的错误链上,就会返回true,实现了一个很简陋的多态效果。As总是用于替代if _, ok := err.(type); ok这样的代码。
当然,上面的函数一方面让你少写了很多代码,另一方面又严重依赖反射,特别是错误链很长的时候需要反复追溯多次,所以这里有两条忠告:
就个人而言我不认为新的错误处理方法解决了什么本质的问题,但作为迈出尝试的第一步,还是值得肯定的。
标签:nop 机制 道路 权限错误 运行时 继承 比较 eof 自定义类
原文地址:https://www.cnblogs.com/apocelipes/p/11600855.html