标签:att 第一个 center 选择 com 过滤 是否有效 决定 主机名
目录
redis除了可以作为db存储用,还有一些场景是做二级缓存(比如mysql+redis或者mysql+memcached),所以这里总结下作为缓存时需要考虑的一些问题及解决方案
当一份数据存在多个数据源(比如mysql+redis)或者多个redis实例(redis cluster模式下)时需要考虑其最终一致性问题,避免脏读。

1)线程A发起一个写操作,第一步write DB
2)线程A第二步del cache
3)线程B发起一个读操作,cache miss
4)线程B从DB获取最新数据
5)线程B同时set cache

1)读取缓存中是否有相关数据
2)如果缓存中有相关数据value,则返回
3)如果缓存中没有相关数据,则从数据库读取相关数据放入缓存中key->value,再返回
4)如果有更新数据,则先更新数据,再删除缓存
5)为了保证第四步删除缓存成功,使用binlog异步删除
6)如果是主从数据库,binglog取自于从库
7)如果是一主多从,每个从库都要采集binlog,然后消费端收到最后一台binlog数据才删除缓存
Sentinel 是 Redis 高可用的解决方案,由一个或者多个 Sentinel 实例组成的系统可以监视 Redis 主节点及其从节点,当检测到 Redis 主节点下线时,会根据特定的选举规则从该主节点对应的所有从节点中选举出一个“最优”的从节点升主,然后由升主的新主节点处理请求。
单实例 Redis 虽然简单,但瓶颈明显。一是容量问题,在一些应用场景下,数据规模可达数十 G,甚至数百G,而物理机的资源却是有限的,内存无法无限扩充;二是并发性能问题,Redis 号称单实例10万并发,但也仅仅是10万并发。鉴于单机模式的局限性,历时三年,Redis-Cluster应运而生。
节点互通:所有的Redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽;
去中心化:Redis-Cluster不存在中心节点,每个节点都记录有集群的状态信息,并且通过Gossip协议,使每个节点记录的信息实现最终一致性;
客户端直连:客户端与Redis节点直连,不需要中间proxy层,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可;
数据分片: Redis-Cluster的键空间被分割为 16384 个slot,这些slot被分别指派给主节点,当存储Key-Value 时,根据 CRC16(key) Mod 16384的值,决定将一个 Key-value 放到哪个 Slot 中;
多数派原则:对于集群中的任何一个节点,需要超过半数的节点检测到它失效(pFail),才会将其判定为失效(Fail);
自动Failover:当集群中某个主节点故障后(Fail),其它主节点会从故障主节点的从节点中选举一个”最佳“从节点升主,替代故障的主节点;
功能弱化:集群模式下,由于数据分布在多个节点,不支持单机模式下的集合操作,也不支持多数据库功能,集群只能使用默认的0号数据库;
集群规模:官方推荐的最大节点数量为 1000 个左右,这是因为当集群规模过大时,Gossip协议的效率会显著下降,通信成本剧增;
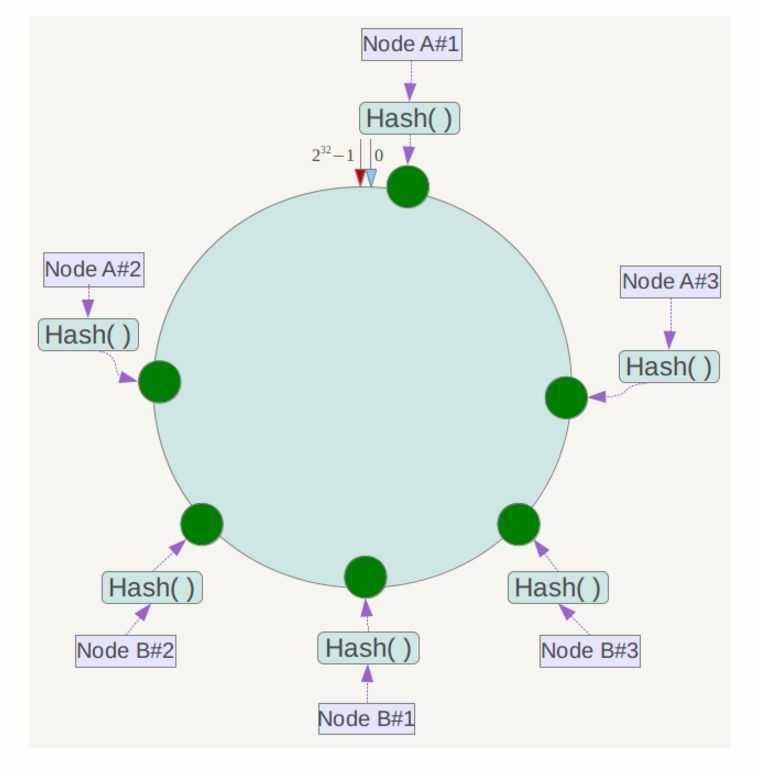
哈希函数H(CRC32)的值空间为0-2^32-1(即哈希值是一个32位无符号整形)
整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6…
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置.
将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器.
一般的,在一致性Hash算法中,如果一台服务器增删,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响
为了解决数据倾斜问题(被缓存的对象大部分集中缓存在某一台服务器上),一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器IP或主机名的后面增加编号来实现。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
标签:att 第一个 center 选择 com 过滤 是否有效 决定 主机名
原文地址:https://www.cnblogs.com/arachis/p/redis_cache.html