标签:一个 之间 队列 分布式应用 字节 连通 mis 告诉 文件写入
Hadoop
是一个开源框架,可编写和运行分布式应用处理大规模数据
Hadoop框架的核心是HDFS 和 MapReduce
HDFS是分布式文件系统(存储)
MapReduce是分布式数据处理模型和执行环境(计算)
作者:Doug Cutting
Hadoop特点
扩容能力
能可靠地存储和处理千兆字节(PB)数据
成本低
可以通过普通机器组成的服务器群来分布以及处理数据,服务器群总计可达数千个节点
高效率(有待验证)
通过分发数据,hadoop可以在数据所在的节点上并行地处理他们。使得处理速度非常快
可靠性
hadoop能自动地维护数据的多分备份,并在任务失败后能自动重新部署计算任务
Hadoop应用场景
大数据量存储
日志处理
Hadoop安装模式
(1)单机模式配置方式
单击模式不需要配置,经常用来调试
(2)伪分布模式
相当于只有一个节点(机器)的集群,这个节点既是Master也是Slave;既是NameNode,也是DataNode
(3)完全分布式模式
设置SSH免密码登录,把各从节点生成的公钥添加到主节点的信任列表
在所有主机安装JDK和Hadoop,组成连通网络
修改3个配置文件:core-site.xml、hdfs-site.xml、mapred-site.xml,指定NameNode和JobTraker的位置和端口,设置文件的副本等参数
格式化文件系统
开机
HDFS架构
1.HDFS的架构
·主从结构分为主节点(只有一个namenode)、从节点(多个,datanode)
namenode作用:接收用户操作请求,
维护文件系统的目录结构
管理文件与block(块)之间关系,block与datanode之间关系
datanode作用
存储文件、文件被分成block存储在磁盘上。
为保证书安全,文件会有多个副本
2.Yarn的架构
是一个资源的调度和管理平台
···主从结构
主节点 :1个ResourceManager
从节点:多个NodeManager
···作用
管理ResourceManager的分配和调度
MapReduce、Storm、Spark应用,必须实现ApplicationMaster接口,才能被RM管理
···NodeManager作用
单节点资源的管理
3.HDFS2的架构(HDFS升级2.0)
负责数据的分布式存储
主从结构
主节点:2个namenode(多一个备份,防止一个namenode挂掉)
从节点 :多个datanode
namenode作用
接收用户操作请求,用户操作的入口
维护文件系统的目录结构,称作命名空间
datanode作用
存储文件
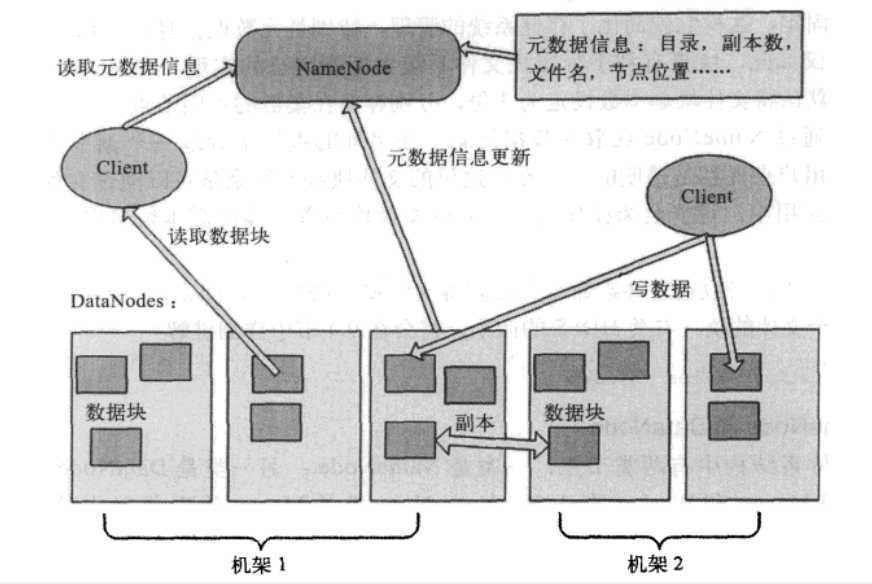
NameNode存储:元数据信息:目录,副本数,文件名,节点位置!!!
写入数据:client端(客户端)通过机架感应的策略选择离自己最近的机架的一个节点按照128M为一个基本块的格式存放,并在本机架另一节点做备份,在选择另一机架的一个节点备份,共三份数据存储,默认副本系数是3
优点:改进数据可靠性、可用性和网络带宽的利用率。放在两个机架而不是三个机架,从而减少机架间的数据传输,从而提高写操作效率。
读取数据:client端先读取离最近的机架,如果有数据就读取,没有选择远端的机架读取数据
优点:读取离他最近的副本。从而降低整体的带宽消耗和读取延时,减少了读取数据时需要的网络传输总带宽
NameNode介绍
NameNode管理文件系统的命名空间,它维护者文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。
NameNode的目录结构
绝对路径:/usr/local/hadoop/hadoop-2.6.4/tmp/dfs/name/current
包含
VERSION文件
是Java属性文件
#Sun Dec 20 03:37:06 CST 2015
namespaceID=1140004446
clusterID=CID-0e42b743-6a24-4058-bf00-37490389ba66
cTime=0
storageType=NAME_NODE
blockpoolID=BP-1343100618-192.168.20.10-1501171529454
layoutVersion=-60
-
namespaceID:是文件系统的唯一标识符,在文件系统首次格式化之后生成的
-
cTime:表示NameNode存储时间的创建时间,NameNode更新之后,此处的值 为更新时间戳。
-
storageType:存储的是什么进程的数据结构信息(如果是DataNode,storageType=DATA_NODE)
-
clusterID:是系统生成或手动指定的集群ID(集群所有节点都相同)
fsimage文件
是Hadoop文件系统元数据的一个永久性的检查点,其中包含Hadoop文件系统中的所有目录和文件idnode的序列化信息。
存放着元数据信息
edits文件
存放的是Hadoop文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。(就是说更新的文件都首先在edits文件中存放,在固定时间在和fsimage文件合并)
重要性:fsimage文件存放所有元数据信息,及文件idnode的序列化信息;edits存放更新的文件。所以一旦这两文件损坏,就算DataNode有数据,也好不到该文件的位置。所以要既是备份fsimage和edits文件
HDFS2 示意图
-
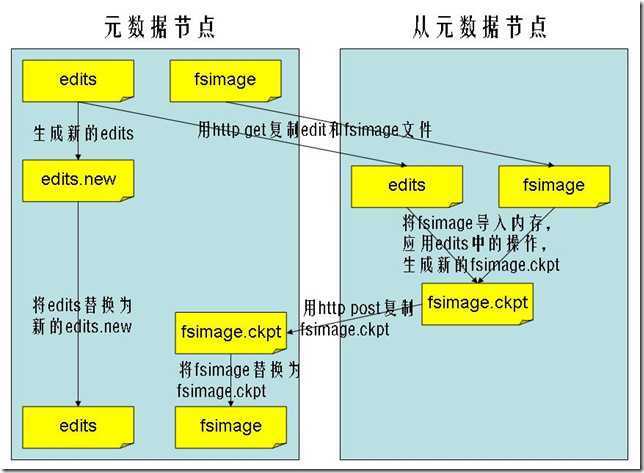
Secondary NameNode请求NameNode进行edit log的滚动(即创建一个新的edit log)将新的编辑操作记录到新生成的edit log文件;
-
通过http get方式,读取nameNode上的fsimage和edit文件,到Secondary NameNode上
-
读取fsimage到内存中,即加载fsimage到内存,然后执行edits中所有操作,并生成一个新的fsimage文件,即这个检查点被创建
-
通过http post方式,将新的fsimage文件传送到namenode
-
Namenode使用新的fsimage文件替换原来的fsimage文件,让1,创建的edits替代原来的edits文件,并且更新fsimage文件的检查点时间,整个处理过程完成。
-
Secondary nameNode 的处理,是将fsimage和的its文件周期合并,不会造成NameNode重启时造成长时间不可访问的情况。
NameNode容错机制
Hadoop提供了两种机制(Namenode主要负责存储HDFS的元数据,如果没有NameNode,HDFS不能工作)
一、将持久化存储在本地硬盘的文件系统元数据备份
Hadoop可以通过配置来让Namenode将他的持久化状态文件写到不同的文件系统中,这种写操作是同步并且是原子化的。
比较常见的配置是在将持久化状态写到本地硬盘的同时,也写入到一个远程挂载的网络文件系统
二、运行一个辅助的Namenode(Secondary Namenode)
Secondary Namenode 并不能用作Namenode,它主要作用是定期将Namespace镜像与操作日志文件合并,以防止操作日志文件变得过大,通常,Secondary Namenode运行在一个单独的物理机上,因为合并操作需要占用大量的CPU时间以及和Namenode相当的内存。辅助Namenode保存着合并后的Namespace镜像的一个备份
Secondary NameNode介绍
是一个用来监控HDFS状态的辅助后台程序,每个集群都有一个Secondary NameNode,并且部署一个单独的服务器上
Secondary NameNode不同于Namenode,它不接受或者记录任何实时的数据变化,但是它与NameNode进行通信,以便定期的保存HDFS元数据的快照。由于NameNode是单点的,通过Secondary NameNode的快照功能,可以将NameNode的宕机时间和数据损失降低到最小
Datanode介绍
是文件系统的工作节点,他们根据客户端或者是Namenode的调度存储和检索数据,并且定期向Namenode发送他们所存储的块的列表
集群中的每个服务器都运行一个DataNode后台程序,这个后台程序负责把HDFS数据块读写到本地的文件系统,当需要通过客户端读/写某个数据时,先由NameNode告诉客户端去哪个DataNode进行具体的读/写操作,然后,客户端直接与这个DataNode服务器上的后台程序进行通信,并且对相关的数据块进行读/写操作。
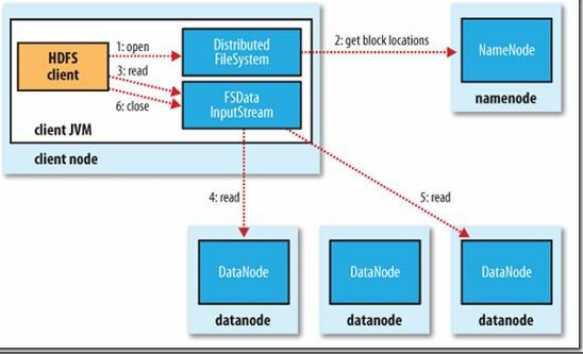
Hadoop文件读取
-
client端通过DistributedFileSystem对象的open函数调用Namenode请求文件块所在的位置(三个副本位置都会获取到),然后返回给client端。
-
client端在FSDataInputSteam调用read函数,然后连接文件第一个块最近的DataNode,第一个读取完毕后,再查找存储下一个块所在最近的DataNode,直到整个文件块读取完毕后,返回给client端,并关闭读流close函数
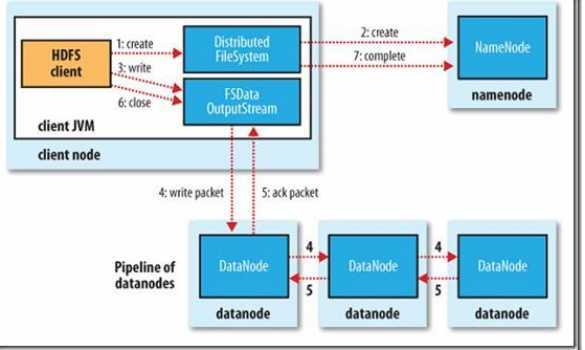
Hadoop文件写入
DataNode中的副本是异步完成的
-
client端通过调用DistributedFileSystem对象中的create()函数在NameNode的文件系统命名空间中创建一个新文件。
-
Namenode会通过多种验证保证新的文件不存在文件系统中,并且确保请求client端拥有创建文件的权限。当所有验证通过时,NameNode会创建一个新文件的记录,如果创建失败则抛处IOException异常;如果成功,则DistributedFileSystem返回一个FSDataOutputStream给client端用来写入数据。其中FSDataOutputStream包含一个数据流对象DFSOutputStream,client端将使用它来处理和DataNode即NameNode之间的通信。
-
当client端写入数据时,DFSOutputStream会将文件分割成包,然后放入一个内部队列,我们成为“数据队列”
-
DataStream会将这些小的文件包放入数据流中,DataStreamer的作用是请求NameNode为新的文件包分配合适的DataNode存放副本,返回的DataNode列表形成一个“管道”,
假设副本数为3,name这个管道中就会有3个DataNode,DataStreamer将文件包以流的方式传送给队列中的第一个DataNode。第一个DataNode会存储这个包,然后将它推送到第二个DataNode中,随后照这样进行,直到管道中的最后一个DataNode。
DFSOutputStream同时也会保存一个包的内部队列,用来等待管道中的DataNode返回确认信息,这个队列被称为确认队列,只有当所有的管道中的DataNode都返回了写入成功的信息文件包,才会从确认队列中删除
HDFS写入失败如何处理
-
HDFS首先会关闭管道。
-
然后在确认通知队列中的文件包都会被添加到数据队列的前端,当前存放于正常工作的DataNode之上的文件块会被赋予一个新的身份,并且和NameNode进行关联。
-
失败的DataNode过段时间从故障中恢复过来,之前存放进去的部分数据块会被删除,然后管道把失败的DataNode删除
-
在步骤2中的文件块继续被写到管道中的另外两个DataNode中
-
最后NameNode会注意到现在的文件块副本数没有达到配置属性要求,会在另外的DataNode上重新安排创建一个副本,随后的文件会正常执行写入操作
格式化文件
重新格式化步骤:
-
重新格式化意味着集群的数据会被全部删除,格式化前需考虑数据备份或转移问题,
-
先删除主节点(namenode节点),Hadoop的临时存储目录tmp、namenode存储永久性元数据目录dfs/name、Hadoop系统日志文件目录log中的内容(删除内容,而不是删除文件夹)
-
删除所有数据节点(datanode节点),Hadoop的临时存储目录tmp、namenode存储永久性元数据目录dfs/name、Hadoop系统日志文件目录log中内容
-
格式化一个新的分布式文件系统
注意事项:
-
Hadoop的临时存储目录tmp(即core-site.xml配置文件中的hadoop.tmp.dir属性,默认值是/tmp/hadoop-${user.name}),如果没有配置hadoop.tmp.dir属性,那么hadoop格式化时将会在/tmp目录下创建一个目录
-
Hadoop的namenode元数据目录(即hdfs-site.xml配置文件中dfs.namenode.name.dir属性,默认值是${hadoop.tmp.dir}/dfs/name),同意如果没有配置该属性,那么hadoop在格式化时将自行创建,
-
必须注意格式化前必须清楚所有子节点(DataNode节点)dfs/name 下的内容,否则在启动hadoop时子节点的守护进程会启动失败。因为如果该文件内容存在,格式化时就不会重新创建该目录,则clusterID ,namespaceID与主节点(namenode)不一致,从而hadoop启动失败
Hadoop安装包的目录结构
-
bin : Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop
-
etc : Hadoop配置文件所在的目录,包括core-site.xml 、hdfs-site.xml 、mapred-site.xml 等从Hadoop1.0继承而来的配置文件和yam-site.xml等Hadoop2.0新增的配置文件
-
include : 对外提供的变成库头文件(具体动态库和静态库在lib目录中),这些头文件均是用c++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。
-
lib : 该目录包含了Hadoop对外提供的变成动态库和静态库,与include目录中的头文件结合使用
-
libexec : 各个服务对用的shell 配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。
-
sbin : Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本
-
share : Hadoop各个模块编译后的jar包所在目录
HDFS的配置文件主要有两个
hdfs-site.xml
|
属性
|
默认值
|
属性说明
|
|
dfs.name.dir
|
${hadoop.tmp.dir}/dfs/name
|
NameNode元数据保存路径,多个守则以 “ , ” 分割,不能有空格
|
| dfs.data.dir |
${hadoop.tmp.dir}/dfs/data
|
datanode保存数据库的目录,同上可设置多个
|
|
fs.chexkpoint.period
|
3600秒
|
每隔3600秒secondaryNameNode执行checkpoint来合并fsimage和edits(就是edits与fsimage合并)
|
|
fs.checkpoint.size
|
67108864(64M)
|
当edits文化部达到64M时secondaryNameNode执行checkpoint来合并fsimage和eidts
|
|
dfs.block.size
|
67108864(64M)
|
hdfs每个文件块的大小(HDFS1.0默认64;HDFS2.0默认128)
|
|
dfs.replication
|
3
|
指定副本数;(之后的修改不会对已经上传的文件起作用)
|
|
dfs.permissions
|
true
|
文件操作时的权限检查表示,最好设置成false把,不然操作HDFS可能会报权限异常
|
core-site.xml
|
参数
|
属性值
|
解释
|
|
fs.dafaultFS
|
NameNode URL
|
hdfs://host:port
|
|
io.file.buffer.size
|
131072
|
SequenceFiles文件中,读写缓存size设定
|
1 <configuration>
2 <property>
3 <name>fs.defaultFS</name>
4 <value>hdfs://master:9000</value>
5 <description>
6 master为服务器IP地址,其实也可以使用主机名 </description>
7 </property>
8 <property>
9 <name>io.file.buffer.size</name>
10 <value>131072</value>
11 <description>
12 该属性值单位为KB,131072KB即为默认的64M
13 </description>
14 </property>
15 /configuration>
hdfs-site.xml 配置NameNode
|
参数
|
属性值 |
解释
|
|
dfs.namenode.name.dir
|
在本地文件系统所在的NameNode的存储空间和持续化处理日志
|
如果这是一个以逗号分隔的目录列表,然后将名称表被复制的所有目录,以备不时之需
|
|
dfs.namenode.hosts/
dfs.namenode.hosts.exclude
|
Datanodes permitted/excluded列表
|
如有必要,可以使用这些文件来控制允许数据节点的列表
|
| dfs.blocksize |
268435456
|
大写的文件系统HDFS块大小为256MB
|
|
dfs.namenode.handler.count
|
100
|
设置更多的namenode线程,处理从datanode发出的大量RPC请求
|
例
1 <configuration>
2 <property>
3 <name>dfs.replication</name>
4 <value>1</value>
5 <description>分片数量,伪分布式将其配置成1即可</description>
6 </property>
7 <property>
8 <name>dfs.namenode.name.dir</name>
9 <value>/usr/local/hadoop/tmp/namenode</value>
10 <description>命名空间和事务在本地文件系统永久存储的路径</description>
11 </property>
12 <property>
13 <name>dfs.namenode.hosts</name>
14 <value>slaver1, slaver2</value>
15 <description>datanode1, datanode2分别对应DataNode所在服务器主机名</description>
16 </property>
17 <property>
18 <name>dfs.blocksize</name>
19 <value>268435456</value>
20 <description>大文件系统HDFS块大小为256M,默认值为64M</description>
21 </property>
22 <property>
23 <name>dfs.namenode.handler.count</name>
24 <value>100</value>
25 <description>更多的NameNode服务器线程处理来自DataNodes的RPCS</description>
26 </property>
27 </configuration>
配置DataNode实例
1 <configuration>
2 <property>
3 <name>dfs.datanode.data.dir</name>
4 <value>file:/usr/local/hadoop/tmp/datanode</value>
5 <description>DataNode在本地文件系统中存放块的路径</description>
6 </property>
7 </configuration>
mapred-site.xml
配置mapreduce
|
参数
|
属性值
|
解释
|
|
mapreduce.framework.name
|
yarn
|
执行框架设置为Hadoop YARN
|
|
mapreduce.map.memory.mb
|
1536
|
对maps更大的资源限制的
|
|
maperduce.map.java.opts
|
-Xmx2014M
|
maps中对jvm child 设置更大的堆大小
|
|
mapreduce.reduce.memory.mb
|
3072
|
设置reduces对于较大的资源限制
|
|
mapreduce.reduce.java.opts
|
-Xmx2560M
|
reduces对jvm child 设置更大的堆大小
|
| mapreduce.task.io.sort.mb |
512
|
更高的内存限制,而对数据进行排序的效率
|
|
mapreduce.task.io.sort.factor
|
100
|
在文件排序中更多的流合并为一次
|
|
mapreduce.reduce.shuffle.prarllelcopies
|
50
|
通过reduces从更多的map中读取较多的平行 副本
|
例
1 <configuration>
2 <property>
3 <name> mapreduce.framework.name</name>
4 <value>yarn</value>
5 <description>执行框架设置为Hadoop YARN</description>
6 </property>
7 <property>
8 <name>mapreduce.map.memory.mb</name>
9 <value>1536</value>
10 <description>对maps更大的资源限制的</description>
11 </property>
12 <property>
13 <name>mapreduce.map.java.opts</name>
14 <value>-Xmx2014M</value>
15 <description>maps中对jvm child设置更大的堆大小</description>
16 </property>
17 <property>
18 <name>mapreduce.reduce.memory.mb</name>
19 <value>3072</value>
20 <description>设置 reduces对于较大的资源限制</description>
21 </property>
22 <property>
23 <name>mapreduce.reduce.java.opts</name>
24 <value>-Xmx2560M</value>
25 <description>reduces对 jvm child设置更大的堆大小</description>
26 </property>
27 <property>
28 <name>mapreduce.task.io.sort</name>
29 <value>512</value>
30 <description>更高的内存限制,而对数据进行排序的效率</description>
31 </property>
32 <property>
33 <name>mapreduce.task.io.sort.factor</name>
34 <value>100</value>
35 <description>在文件排序中更多的流合并为一次</description>
36 </property>
37 <property>
38 <name>mapreduce.reduce.shuffle.parallelcopies</name>
39 <value>50</value>
40 <description>通过reduces从很多的map中读取较多的平行副本</description>
41 </property>
42 </configuration>
yarn-site.xml
配置ResourceManager 和 NodeManager
RM : ResourceManager
NM : NodeManager
|
参数
|
属性值
|
解释 |
|
yarn.nodemanager.aux-services
|
NodeManager上运行的附属服务。需配置或mapreduce_shuffle,才可运行MapReduce程序
|
|
|
yarn.resourcemanager.hostname
|
MR 的hostname
|
|
小记---------Hadoop读、写文件步骤,HDFS架构理解
标签:一个 之间 队列 分布式应用 字节 连通 mis 告诉 文件写入
原文地址:https://www.cnblogs.com/yzqyxq/p/11606641.html