标签:aci size 实例 jdk 类型 内存映射 lips 调用 blob
Buffer?我们很容易想到缓冲区的概念,在NIO中,它是直接和Channel打交道的缓冲区,通常场景或是从Buffer写入Channel,或是从Channel读入Buffer。Buffer是一个抽象类,Java提供如下图的实现类,我是直接在Eclipse截出来的^_^
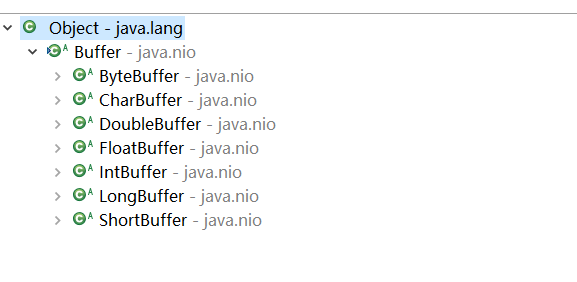
其实核心是ByteBuffer,除了布尔类型,所有原始类型都有相应的Buffer实现,只是包装了一下ByteBuffer而已,我们使用最多的通常是ByteBuffer。
我们应该将Buffer理解为一个数组,IntBuffer、CharBuffer、DoubleBuffer 等分别对应int[]、char[]、double[]等。
上图没有包括MappedByteBuffer,该类用户内存映射文件,放到最后再说吧。
Buffer有四个重要的属性,分别为:mark、position、limit、capacity,和两个重要方法分别为:flip和clear。Buffer的底层存储结构为数组。这四个属性有以下特点:
1 | mark <= position <= limit <= capacity |
那么这几个属性分别起着什么作用呢?下面的介绍都以ByteBuffer为例,来分析ByteBuffer的使用流程和原理。
下面是这四个属性的简单介绍:
对ByteBuffer操作主要包括读和写,向缓冲区写入数据和从缓冲区读取数据会影响以上四个属性的值的变化,我们分别对读和写以及之间切换进行分析。
写操作
首先分配1024字节的缓冲区,然后向缓冲区放入5字节的字符串“abcde”,代码如下:
1 | String str="abcde"; |
初始化position,limit,capacity位置如下图所示
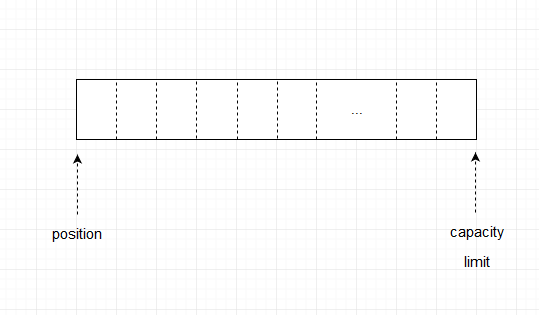
我们发现position为0,而limit和capacity均指向内存区域最大位置,代表此时缓存区内是空的,已放入capacity大小的数据。
当我们向缓冲区放入5个字节的数据,position,limit,capacity位置发生了变化,如下图所示
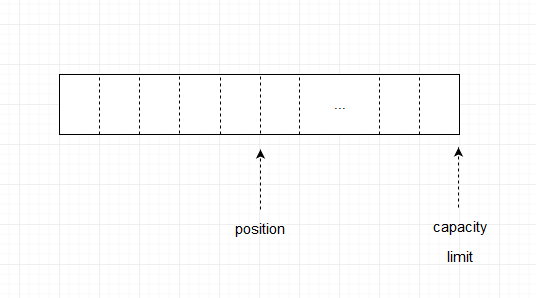
从上图可以看出,在写入数据后,position会向后移动5个位置,指向第六个位置,代表下次写数据的位置,limit和capacity没有改变。
切换到读操作
由写模式切换到读模式需要调用flip方法,这个方法是什么意思呢?在JDK源码中,此方法的代码如下:
1 | public final Buffer () { |
从代码中我们可以清晰的看出,limit被设置为当前position的大小,position归0,mark还是为默认值-1,我们还是看图比较直观,如下图所示:
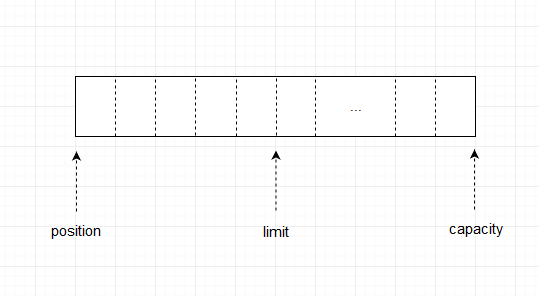
和上一张图片进行对比,我们可以发现limit替换了position的位置,代表当前可以操作的位置,在写的时候,limit的值代表最大的可写位置,在读的时候,limit的值代表最大的可读位置。很明显我们现在是要读数据,就代表最大可读位置。
读操作
通过filp方法切换为读模式后,我们就可以从缓存区里面读取数据,代码如下:
1 |
|
此时position,limit,capacity位置如下图所示
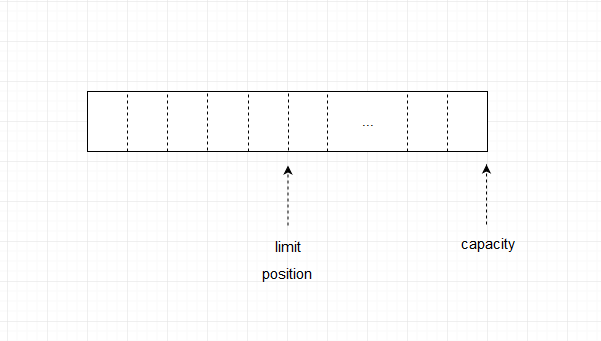
从上图可以看出,position的位置变成了5,由于我们将缓存区里面的数据读完了,就是这个情况,所以读操作的时候,每读一个值,position 就自动加 1。在HeapByteBuffer源码中,就是增加一个offset的偏移量。
1 | protected int ix(int i) { |
重复读数据
上一步读数据的操作已经将position移动了limit的位置,我们想读数据就读不到了,但能不能重复读取数据呢?肯定可以呀,这时我们就可以用rewind方法来重复读写,代码如下:
1 | //rewind 可重复读数据 |
此时position,limit,capacity位置如下图所示

有没有发现和flip操作后一致,此时肯定要一样了,这样我们才可以重复读取。
清空缓冲区
此时我们不想要缓冲区的数据了,需要清空掉,可以用clear方法来操作,代码如下
1 | // 清空缓冲区,缓冲区的数据仍然存在,但处于被遗忘的状态,不能被读取 |
此时position,limit,capacity位置如下图所示
![]()
注意缓冲区的数据仍然存在,但处于被遗忘的状态,不能被读取
mark() & reset()
除了 position、limit、capacity 这三个基本的属性外,还有一个常用的属性就是 mark。
mark 用于临时保存 position 的值,每次调用 mark() 方法都会将 mark 设值为当前的 position,便于后续需要的时候使用。
1 | public final Buffer mark() { |
那到底什么时候用呢?考虑以下场景,我们在 position 为 5 的时候,先 mark() 一下,然后继续往下读,读到第 10 的时候,我想重新回到 position 为 5 的地方重新来一遍,那只要调一下 reset() 方法,position 就回到 5 了。
1 | public final Buffer reset() { |
rewind() & clear() & compact()
rewind():会重置 position 为 0,通常用于重新从头读写 Buffer。
1 | public final Buffer rewind() { |
clear():有点重置 Buffer 的意思,相当于重新实例化了一样。
通常,我们会先填充 Buffer,然后从 Buffer 读取数据,之后我们再重新往里填充新的数据,我们一般在重新填充之前先调用 clear()。
1 | public final Buffer clear() { |
compact():和 clear() 一样的是,它们都是在准备往 Buffer 填充新的数据之前调用。
前面说的 clear() 方法会重置几个属性,但是我们要看到,clear() 方法并不会将 Buffer 中的数据清空,只不过后续的写入会覆盖掉原来的数据,也就相当于清空了数据了。
而 compact() 方法有点不一样,调用这个方法以后,会先处理还没有读取的数据,也就是 position 到 limit 之间的数据(还没有读过的数据),先将这些数据移到左边,然后在这个基础上再开始写入。很明显,此时 limit 还是等于 capacity,position 指向原来数据的右边。
参考:
原文:大专栏 NIO之Buffers
标签:aci size 实例 jdk 类型 内存映射 lips 调用 blob
原文地址:https://www.cnblogs.com/petewell/p/11612074.html