标签:ber code 运算 而不是 form parse 效果 inpu cal
一、全表查询和特定列查询
1、全表查询:
-------------------------------------------------------------------
hive (db_test)> select * from dept;
OK
dept.deptno dept.dname dept.loc
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
Time taken: 0.306 seconds, Fetched: 4 row(s)
---------------------------------------------------------------
hive (db_test)> select * from emp;
OK
emp.empno emp.ename emp.job emp.mrg emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
Time taken: 0.075 seconds, Fetched: 14 row(s)
----------------------------------------------------------------------------------------------------------------------------
2、特定列查询:
-----------------------------------------------------------------------------------------------------------------------------
//hive的HQL对于字母的大小写不敏感;
hive (db_test)> SELECT ENAME FROM EMP;
OK
ename
SMITH
ALLEN
WARD
JONES
MARTIN
BLAKE
CLARK
SCOTT
KING
TURNER
ADAMS
JAMES
FORD
MILLER
Time taken: 0.087 seconds, Fetched: 14 row(s)
===========================================================================================================================================================
二、列别名
1、使用AS关键字来确定列的别名:
-----------------------------------------------------------------------------------------------------------------------------
hive (db_test)> select deptno as no,dname as name,loc as dloc from dept;
OK
no name dloc
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
Time taken: 0.101 seconds, Fetched: 4 row(s)
-----------------------------------------------------------------------------------------------------------------------------------
2、不使用AS关键字来确定列的别名:
----------------------------------------------------------------------------------------------------------------------------------
hive (db_test)> select deptno no,dname name,loc dloc from dept;
OK
no name dloc
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
Time taken: 0.083 seconds, Fetched: 4 row(s)
===========================================================================================================================================================
三、算术运算符
|
运算符 |
描述 |
|
A+B |
A和B 相加 |
|
A-B |
A减去B |
|
A*B |
A和B相乘 |
|
A/B |
A除以B |
|
A%B |
A对B取余/模 |
|
A&B |
A和B按位取与 |
|
A|B |
A和B按位取或 |
|
A^B |
A和B按位取异或 |
|
~A |
A按位取反 |
------------------------------------------------------------------------------------------------
hive (db_test)> select t.sal from emp t;
OK
t.sal
800.0
1600.0
1250.0
2975.0
1250.0
2850.0
2450.0
3000.0
5000.0
1500.0
1100.0
950.0
3000.0
1300.0
Time taken: 0.08 seconds, Fetched: 14 row(s)
-----------------------------------------------------------------------------------------------
1、A+B
hive (db_test)> select t.sal+1000 from emp t;
OK
_c0
1800.0
2600.0
2250.0
3975.0
2250.0
3850.0
3450.0
4000.0
6000.0
2500.0
2100.0
1950.0
4000.0
2300.0
Time taken: 0.107 seconds, Fetched: 14 row(s)
---------------------------------------------------------------------------------------
2、A-B
---------------------------------------------------------------------------------------
hive (db_test)> select t.sal-100 from emp t;
OK
_c0
700.0
1500.0
1150.0
2875.0
1150.0
2750.0
2350.0
2900.0
4900.0
1400.0
1000.0
850.0
2900.0
1200.0
Time taken: 0.103 seconds, Fetched: 14 row(s)
-----------------------------------------------------------------------------------
3、A*B
-----------------------------------------------------------------------------------
hive (db_test)> select t.sal*10 from emp t;
OK
_c0
8000.0
16000.0
12500.0
29750.0
12500.0
28500.0
24500.0
30000.0
50000.0
15000.0
11000.0
9500.0
30000.0
13000.0
Time taken: 0.081 seconds, Fetched: 14 row(s)
---------------------------------------------------------------------------
4、A/B
----------------------------------------------------------------------------
hive (db_test)> select t.sal/10 from emp t;
OK
_c0
80.0
160.0
125.0
297.5
125.0
285.0
245.0
300.0
500.0
150.0
110.0
95.0
300.0
130.0
Time taken: 0.072 seconds, Fetched: 14 row(s)
------------------------------------------------------------------------------------------
5、A%B,A对B取模
------------------------------------------------------------------------------------------
hive (db_test)> select t.sal%4 from emp t;
OK
_c0
0.0
0.0
2.0
3.0
2.0
2.0
2.0
0.0
0.0
0.0
0.0
2.0
0.0
0.0
Time taken: 0.093 seconds, Fetched: 14 row(s)
-------------------------------------------------------------------------------
6、A&B
--------------------------------------------------------------------------------
hive (db_test)> select t.empno&3 from emp t where t.empno = 7369;
OK
_c0
1
Time taken: 0.075 seconds, Fetched: 1 row(s)
--------------------------------------------------------------------------------------
7、A|B
---------------------------------------------------------------------------------------
hive (db_test)> select t.empno|3 from emp t where t.empno = 7369;
OK
_c0
7371
Time taken: 0.073 seconds, Fetched: 1 row(s)
-------------------------------------------------------------------------------------------
8、A^B
------------------------------------------------------------------------------------------
hive (db_test)> select t.empno^3 from emp t where t.empno = 7369;
OK
_c0
7370
Time taken: 0.066 seconds, Fetched: 1 row(s)
-------------------------------------------------------------------------------------------
9、~A
-------------------------------------------------------------------------------------------
hive (db_test)> select ~t.empno from emp t where t.empno = 7369;
OK
_c0
-7370
Time taken: 0.071 seconds, Fetched: 1 row(s)
================================================================
四、常用函数
1、count()
-------------------------------------------------------------------------
hive (db_test)> select count(*) from dept;
Query ID = root_20190930120201_17286059-5adb-4787-9f93-7326f42c6000
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1569814058022_0001, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0001/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-09-30 12:02:12,709 Stage-1 map = 0%, reduce = 0%
2019-09-30 12:02:22,467 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.08 sec
2019-09-30 12:02:30,828 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.14 sec
MapReduce Total cumulative CPU time: 3 seconds 140 msec
Ended Job = job_1569814058022_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.14 sec HDFS Read: 6518 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 140 msec
OK
_c0
4
Time taken: 30.278 seconds, Fetched: 1 row(s)
-----------------------------------------------------------------------------------
2、sum()
--------------------------------------------------------------------------------------
hive (db_test)> select sum(t.deptno) from dept t;
Query ID = root_20190930120410_ee43b390-f605-4942-9ac0-d3a061f6e6ed
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1569814058022_0002, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0002/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-09-30 12:04:32,368 Stage-1 map = 0%, reduce = 0%
2019-09-30 12:04:40,677 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.74 sec
2019-09-30 12:04:51,174 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.72 sec
MapReduce Total cumulative CPU time: 3 seconds 720 msec
Ended Job = job_1569814058022_0002
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.72 sec HDFS Read: 6822 HDFS Write: 4 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 720 msec
OK
_c0
100
Time taken: 42.547 seconds, Fetched: 1 row(s)
------------------------------------------------------------------------------------
3、avg()
----------------------------------------------------------------------------
hive (db_test)> select avg(t.deptno) from dept t;
Query ID = root_20190930120604_ee253875-e364-4ea9-b7d4-3ea33eed4007
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1569814058022_0003, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0003/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0003
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-09-30 12:06:18,094 Stage-1 map = 0%, reduce = 0%
2019-09-30 12:06:29,527 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 7.32 sec
2019-09-30 12:06:37,151 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 8.35 sec
MapReduce Total cumulative CPU time: 8 seconds 350 msec
Ended Job = job_1569814058022_0003
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 8.35 sec HDFS Read: 7184 HDFS Write: 5 SUCCESS
Total MapReduce CPU Time Spent: 8 seconds 350 msec
OK
_c0
25.0
Time taken: 34.397 seconds, Fetched: 1 row(s)
===========================================================
五、limit语句
1、limit语句不支持SQL语句的limit 1 2
--------------------------------------------------------------------------
hive (db_test)> select * from dept t limit 1 2;
FAILED: ParseException line 1:29 extraneous input ‘2‘ expecting EOF near ‘<EOF>‘
----------------------------------------------------
2、limit语句只支持前X行数据返回,limit 3
-----------------------------------------------------------------
hive (db_test)> select * from dept t limit 3;
OK
t.deptno t.dname t.loc
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
Time taken: 0.056 seconds, Fetched: 3 row(s)
====================================================
六、where语句
1、where语句紧随from语句后面
----------------------------------------------------------------
hive (db_test)> select * from dept t where t.loc = 1700;
OK
t.deptno t.dname t.loc
10 ACCOUNTING 1700
40 OPERATIONS 1700
Time taken: 0.084 seconds, Fetched: 2 row(s)
=============================================
七、比较运算符
|
操作符 |
支持的数据类型 |
描述 |
|
A=B |
基本数据类型 |
如果A等于B则返回TRUE,反之返回FALSE |
|
A<=>B |
基本数据类型 |
如果A和B都为NULL,则返回TRUE,其他的和等号(=)操作符的结果一致,如果任一为NULL则结果为NULL |
|
A<>B, A!=B |
基本数据类型 |
A或者B为NULL则返回NULL;如果A不等于B,则返回TRUE,反之返回FALSE |
|
A<B |
基本数据类型 |
A或者B为NULL,则返回NULL;如果A小于B,则返回TRUE,反之返回FALSE |
|
A<=B |
基本数据类型 |
A或者B为NULL,则返回NULL;如果A小于等于B,则返回TRUE,反之返回FALSE |
|
A>B |
基本数据类型 |
A或者B为NULL,则返回NULL;如果A大于B,则返回TRUE,反之返回FALSE |
|
A>=B |
基本数据类型 |
A或者B为NULL,则返回NULL;如果A大于等于B,则返回TRUE,反之返回FALSE |
|
A [NOT] BETWEEN B AND C |
基本数据类型 |
如果A,B或者C任一为NULL,则结果为NULL。如果A的值大于等于B而且小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可达到相反的效果。 |
|
A IS NULL |
所有数据类型 |
如果A等于NULL,则返回TRUE,反之返回FALSE |
|
A IS NOT NULL |
所有数据类型 |
如果A不等于NULL,则返回TRUE,反之返回FALSE |
|
IN(数值1, 数值2) |
所有数据类型 |
使用 IN运算显示列表中的值 |
|
A [NOT] LIKE B |
STRING 类型 |
B是一个SQL下的简单正则表达式,如果A与其匹配的话,则返回TRUE;反之返回FALSE。B的表达式说明如下:‘x%’表示A必须以字母‘x’开头,‘%x’表示A必须以字母’x’结尾,而‘%x%’表示A包含有字母’x’,可以位于开头,结尾或者字符串中间。如果使用NOT关键字则可达到相反的效果。 |
|
A RLIKE B, A REGEXP B |
STRING 类型 |
B是一个正则表达式,如果A与其匹配,则返回TRUE;反之返回FALSE。匹配使用的是JDK中的正则表达式接口实现的,因为正则也依据其中的规则。例如,正则表达式必须和整个字符串A相匹配,而不是只需与其字符串匹配。 |
1、A=B
------------------------------
hive (db_test)> select * from dept t where t.loc = 1700;
OK
t.deptno t.dname t.loc
10 ACCOUNTING 1700
40 OPERATIONS 1700
Time taken: 0.084 seconds, Fetched: 2 row(s)
-----------------------------
2、A>B
---------------------------
hive (db_test)> select * from dept t where t.loc > 1800;
OK
t.deptno t.dname t.loc
30 SALES 1900
Time taken: 0.095 seconds, Fetched: 1 row(s)
---------------------------------
3、between...and...
--------------------------------
hive (db_test)> select * from dept t where t.loc between 1700 and 1800;
OK
t.deptno t.dname t.loc
10 ACCOUNTING 1700
20 RESEARCH 1800
40 OPERATIONS 1700
Time taken: 0.046 seconds, Fetched: 3 row(s)
----------------------------------
4、like
----------------------------------
hive (db_test)> select * from dept t where t.dname like ‘A%‘;
OK
t.deptno t.dname t.loc
10 ACCOUNTING 1700
Time taken: 0.054 seconds, Fetched: 1 row(s)
hive (db_test)> select * from dept t where t.dname like ‘%A%‘;
OK
t.deptno t.dname t.loc
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
Time taken: 0.067 seconds, Fetched: 4 row(s)
hive (db_test)> select * from dept t where t.dname like ‘_A%‘;
OK
t.deptno t.dname t.loc
30 SALES 1900
Time taken: 0.09 seconds, Fetched: 1 row(s)
------------------------------------
5、is null 或者is not null
----------------------------------------
hive (db_test)> select * from dept t where t.dname is not null;
OK
t.deptno t.dname t.loc
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
Time taken: 0.066 seconds, Fetched: 4 row(s)
-------------------------------------------------
6、in
------------------------------------------
hive (db_test)> select * from dept t where t.loc in (1700,1900);
OK
t.deptno t.dname t.loc
10 ACCOUNTING 1700
30 SALES 1900
40 OPERATIONS 1700
Time taken: 0.089 seconds, Fetched: 3 row(s)
==========================================
八、逻辑运算符
1、and
------------------------------------------
hive (db_test)> select * from dept t where t.loc > 1700 and t.loc <= 1800;
OK
t.deptno t.dname t.loc
20 RESEARCH 1800
Time taken: 0.087 seconds, Fetched: 1 row(s)
--------------------------------------
2、or
-----------------------------------
hive (db_test)> select * from dept t where t.loc > 1700 or t.loc <= 1800;
OK
t.deptno t.dname t.loc
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
Time taken: 0.071 seconds, Fetched: 4 row(s)
-----------------------------------------
3、not
----------------------------------------
hive (db_test)> select * from dept t where t.loc not in (1700,1900);
OK
t.deptno t.dname t.loc
20 RESEARCH 1800
Time taken: 0.077 seconds, Fetched: 1 row(s)
======================================
九、分组
1、group by
-------------------------------------------------
hive (db_test)> select t.deptno, avg(t.sal) avg_sal from emp t group by t.deptno;
Query ID = root_20190930122718_7a438ccb-9267-4674-a404-3ce5e259b881
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1569814058022_0004, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0004/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0004
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-09-30 12:27:24,514 Stage-1 map = 0%, reduce = 0%
2019-09-30 12:27:31,939 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.64 sec
2019-09-30 12:27:37,285 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.59 sec
MapReduce Total cumulative CPU time: 2 seconds 590 msec
Ended Job = job_1569814058022_0004
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.59 sec HDFS Read: 8660 HDFS Write: 54 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 590 msec
OK
t.deptno avg_sal
10 2916.6666666666665
20 2175.0
30 1566.6666666666667
Time taken: 19.98 seconds, Fetched: 3 row(s)
-------------------------------------------------------------
2、having语句
------------------------------------------------------------
hive (db_test)> select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
Query ID = root_20190930122942_beda499a-05d4-45ec-bc06-ab986cd70606
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1569814058022_0005, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0005/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0005
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-09-30 12:29:48,644 Stage-1 map = 0%, reduce = 0%
2019-09-30 12:29:54,969 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.8 sec
2019-09-30 12:30:00,273 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 1.93 sec
MapReduce Total cumulative CPU time: 1 seconds 930 msec
Ended Job = job_1569814058022_0005
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 1.93 sec HDFS Read: 9085 HDFS Write: 32 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 930 msec
OK
deptno avg_sal
10 2916.6666666666665
20 2175.0
Time taken: 20.192 seconds, Fetched: 2 row(s)
===============================================
十、join语句
1、等值join,使用join...on...
---------------------------------
hive (db_test)> select e.empno, e.ename, d.deptno, d.dname from emp e join dept d on e.deptno = d.deptno;
Query ID = root_20190930123206_4d6696e1-1dcd-4a96-884f-83a5348e404c
Total jobs = 1
Execution log at: /tmp/root/root_20190930123206_4d6696e1-1dcd-4a96-884f-83a5348e404c.log
2019-09-30 12:32:09 Starting to launch local task to process map join; maximum memory = 518979584
2019-09-30 12:32:10 Dump the side-table for tag: 1 with group count: 4 into file: file:/tmp/root/baf87d5f-4ba1-4620-b4ab-bd3376a8fa5b/hive_2019-09-30_12-32-06_032_3171528312371325101-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile01--.hashtable
2019-09-30 12:32:10 Uploaded 1 File to: file:/tmp/root/baf87d5f-4ba1-4620-b4ab-bd3376a8fa5b/hive_2019-09-30_12-32-06_032_3171528312371325101-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile01--.hashtable (373 bytes)
2019-09-30 12:32:10 End of local task; Time Taken: 0.974 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there‘s no reduce operator
Starting Job = job_1569814058022_0006, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0006/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0006
Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
2019-09-30 12:32:17,309 Stage-3 map = 0%, reduce = 0%
2019-09-30 12:32:23,507 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 0.94 sec
MapReduce Total cumulative CPU time: 940 msec
Ended Job = job_1569814058022_0006
MapReduce Jobs Launched:
Stage-Stage-3: Map: 1 Cumulative CPU: 0.94 sec HDFS Read: 7249 HDFS Write: 310 SUCCESS
Total MapReduce CPU Time Spent: 940 msec
OK
e.empno e.ename d.deptno d.dname
7369 SMITH 20 RESEARCH
7499 ALLEN 30 SALES
7521 WARD 30 SALES
7566 JONES 20 RESEARCH
7654 MARTIN 30 SALES
7698 BLAKE 30 SALES
7782 CLARK 10 ACCOUNTING
7788 SCOTT 20 RESEARCH
7839 KING 10 ACCOUNTING
7844 TURNER 30 SALES
7876 ADAMS 20 RESEARCH
7900 JAMES 30 SALES
7902 FORD 20 RESEARCH
7934 MILLER 10 ACCOUNTING
Time taken: 18.543 seconds, Fetched: 14 row(s)
-------------------------------------------
2、等值join,不使用join...on...
-------------------------------------------
hive (db_test)> select e.empno, e.ename, d.deptno, d.dname from emp e,dept d where e.deptno = d.deptno;
Query ID = root_20190930123441_eed205eb-d124-4b1b-a257-6c710a2c5d18
Total jobs = 1
Execution log at: /tmp/root/root_20190930123441_eed205eb-d124-4b1b-a257-6c710a2c5d18.log
2019-09-30 12:34:44 Starting to launch local task to process map join; maximum memory = 518979584
2019-09-30 12:34:45 Dump the side-table for tag: 1 with group count: 4 into file: file:/tmp/root/baf87d5f-4ba1-4620-b4ab-bd3376a8fa5b/hive_2019-09-30_12-34-41_441_1122507582180625669-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile11--.hashtable
2019-09-30 12:34:45 Uploaded 1 File to: file:/tmp/root/baf87d5f-4ba1-4620-b4ab-bd3376a8fa5b/hive_2019-09-30_12-34-41_441_1122507582180625669-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile11--.hashtable (373 bytes)
2019-09-30 12:34:45 End of local task; Time Taken: 0.888 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there‘s no reduce operator
Starting Job = job_1569814058022_0007, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0007/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0007
Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
2019-09-30 12:34:53,311 Stage-3 map = 0%, reduce = 0%
2019-09-30 12:34:59,640 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 1.14 sec
MapReduce Total cumulative CPU time: 1 seconds 140 msec
Ended Job = job_1569814058022_0007
MapReduce Jobs Launched:
Stage-Stage-3: Map: 1 Cumulative CPU: 1.14 sec HDFS Read: 7522 HDFS Write: 310 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 140 msec
OK
e.empno e.ename d.deptno d.dname
7369 SMITH 20 RESEARCH
7499 ALLEN 30 SALES
7521 WARD 30 SALES
7566 JONES 20 RESEARCH
7654 MARTIN 30 SALES
7698 BLAKE 30 SALES
7782 CLARK 10 ACCOUNTING
7788 SCOTT 20 RESEARCH
7839 KING 10 ACCOUNTING
7844 TURNER 30 SALES
7876 ADAMS 20 RESEARCH
7900 JAMES 30 SALES
7902 FORD 20 RESEARCH
7934 MILLER 10 ACCOUNTING
Time taken: 19.263 seconds, Fetched: 14 row(s)
-------------------------------------------------------------------
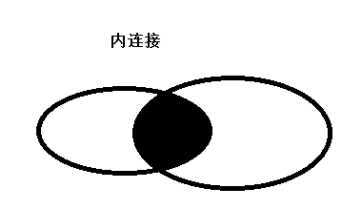
3、内连接,只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。
---------------------------------------------------------------
hive (db_test)> select e.empno, e.ename, d.deptno, d.dname from emp e join dept d on e.deptno = d.deptno;
Query ID = root_20190930123206_4d6696e1-1dcd-4a96-884f-83a5348e404c
Total jobs = 1
Execution log at: /tmp/root/root_20190930123206_4d6696e1-1dcd-4a96-884f-83a5348e404c.log
2019-09-30 12:32:09 Starting to launch local task to process map join; maximum memory = 518979584
2019-09-30 12:32:10 Dump the side-table for tag: 1 with group count: 4 into file: file:/tmp/root/baf87d5f-4ba1-4620-b4ab-bd3376a8fa5b/hive_2019-09-30_12-32-06_032_3171528312371325101-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile01--.hashtable
2019-09-30 12:32:10 Uploaded 1 File to: file:/tmp/root/baf87d5f-4ba1-4620-b4ab-bd3376a8fa5b/hive_2019-09-30_12-32-06_032_3171528312371325101-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile01--.hashtable (373 bytes)
2019-09-30 12:32:10 End of local task; Time Taken: 0.974 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there‘s no reduce operator
Starting Job = job_1569814058022_0006, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0006/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0006
Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
2019-09-30 12:32:17,309 Stage-3 map = 0%, reduce = 0%
2019-09-30 12:32:23,507 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 0.94 sec
MapReduce Total cumulative CPU time: 940 msec
Ended Job = job_1569814058022_0006
MapReduce Jobs Launched:
Stage-Stage-3: Map: 1 Cumulative CPU: 0.94 sec HDFS Read: 7249 HDFS Write: 310 SUCCESS
Total MapReduce CPU Time Spent: 940 msec
OK
e.empno e.ename d.deptno d.dname
7369 SMITH 20 RESEARCH
7499 ALLEN 30 SALES
7521 WARD 30 SALES
7566 JONES 20 RESEARCH
7654 MARTIN 30 SALES
7698 BLAKE 30 SALES
7782 CLARK 10 ACCOUNTING
7788 SCOTT 20 RESEARCH
7839 KING 10 ACCOUNTING
7844 TURNER 30 SALES
7876 ADAMS 20 RESEARCH
7900 JAMES 30 SALES
7902 FORD 20 RESEARCH
7934 MILLER 10 ACCOUNTING
Time taken: 18.543 seconds, Fetched: 14 row(s)
---------------------------------------------------------------------------
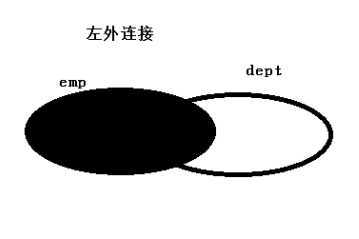
4、左外连接:JOIN操作符左边表中符合WHERE子句的所有记录将会被返回。
----------------------------------------------------
hive (db_test)> select e.empno, e.ename, d.deptno from emp e left join dept d on e.deptno = d.deptno;
Query ID = root_20190930123915_7898d52d-2466-4b26-b2d2-ead6b0ae26d9
Total jobs = 1
Execution log at: /tmp/root/root_20190930123915_7898d52d-2466-4b26-b2d2-ead6b0ae26d9.log
2019-09-30 12:39:19 Starting to launch local task to process map join; maximum memory = 518979584
2019-09-30 12:39:20 Dump the side-table for tag: 1 with group count: 4 into file: file:/tmp/root/baf87d5f-4ba1-4620-b4ab-bd3376a8fa5b/hive_2019-09-30_12-39-15_977_1134579880379913252-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile21--.hashtable
2019-09-30 12:39:20 Uploaded 1 File to: file:/tmp/root/baf87d5f-4ba1-4620-b4ab-bd3376a8fa5b/hive_2019-09-30_12-39-15_977_1134579880379913252-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile21--.hashtable (332 bytes)
2019-09-30 12:39:20 End of local task; Time Taken: 0.79 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there‘s no reduce operator
Starting Job = job_1569814058022_0008, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0008/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0008
Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
2019-09-30 12:39:26,781 Stage-3 map = 0%, reduce = 0%
2019-09-30 12:39:32,928 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 0.65 sec
MapReduce Total cumulative CPU time: 650 msec
Ended Job = job_1569814058022_0008
MapReduce Jobs Launched:
Stage-Stage-3: Map: 1 Cumulative CPU: 0.65 sec HDFS Read: 6960 HDFS Write: 196 SUCCESS
Total MapReduce CPU Time Spent: 650 msec
OK
e.empno e.ename d.deptno
7369 SMITH 20
7499 ALLEN 30
7521 WARD 30
7566 JONES 20
7654 MARTIN 30
7698 BLAKE 30
7782 CLARK 10
7788 SCOTT 20
7839 KING 10
7844 TURNER 30
7876 ADAMS 20
7900 JAMES 30
7902 FORD 20
7934 MILLER 10
Time taken: 18.011 seconds, Fetched: 14 row(s)
-------------------------------------------------------------------------
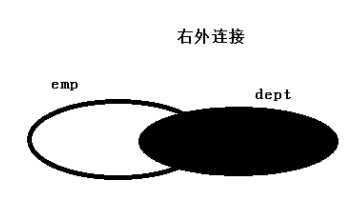
5、右外连接:JOIN操作符右边表中符合WHERE子句的所有记录将会被返回。
----------------------------------------------------------------------
hive (db_test)> select e.empno, e.ename, d.deptno from emp e right join dept d on e.deptno = d.deptno;
Query ID = root_20190930124046_fc46a1de-7993-4f92-aff1-8c258377ff81
Total jobs = 1
Execution log at: /tmp/root/root_20190930124046_fc46a1de-7993-4f92-aff1-8c258377ff81.log
2019-09-30 12:40:50 Starting to launch local task to process map join; maximum memory = 518979584
2019-09-30 12:40:50 Dump the side-table for tag: 0 with group count: 3 into file: file:/tmp/root/baf87d5f-4ba1-4620-b4ab-bd3376a8fa5b/hive_2019-09-30_12-40-46_808_998414055606901395-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile30--.hashtable
2019-09-30 12:40:50 Uploaded 1 File to: file:/tmp/root/baf87d5f-4ba1-4620-b4ab-bd3376a8fa5b/hive_2019-09-30_12-40-46_808_998414055606901395-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile30--.hashtable (498 bytes)
2019-09-30 12:40:50 End of local task; Time Taken: 0.741 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there‘s no reduce operator
Starting Job = job_1569814058022_0009, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0009/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0009
Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
2019-09-30 12:40:58,527 Stage-3 map = 0%, reduce = 0%
2019-09-30 12:41:04,890 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 1.14 sec
MapReduce Total cumulative CPU time: 1 seconds 140 msec
Ended Job = job_1569814058022_0009
MapReduce Jobs Launched:
Stage-Stage-3: Map: 1 Cumulative CPU: 1.14 sec HDFS Read: 6368 HDFS Write: 205 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 140 msec
OK
e.empno e.ename d.deptno
7782 CLARK 10
7839 KING 10
7934 MILLER 10
7369 SMITH 20
7566 JONES 20
7788 SCOTT 20
7876 ADAMS 20
7902 FORD 20
7499 ALLEN 30
7521 WARD 30
7654 MARTIN 30
7698 BLAKE 30
7844 TURNER 30
7900 JAMES 30
NULL NULL 40
Time taken: 19.132 seconds, Fetched: 15 row(s)
------------------------------------------------------------------------
6、满外连接:将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代。

----------------------------------------------------------------------------------
hive (db_test)> select e.empno, e.ename, d.deptno from emp e full join dept d on e.deptno = d.deptno;
Query ID = root_20190930124249_53d14ff5-1c6a-48f6-adb3-986eceeae236
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1569814058022_0010, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0010/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0010
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 1
2019-09-30 12:42:55,962 Stage-1 map = 0%, reduce = 0%
2019-09-30 12:43:08,309 Stage-1 map = 50%, reduce = 0%, Cumulative CPU 2.52 sec
2019-09-30 12:43:09,346 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.19 sec
2019-09-30 12:43:14,475 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.02 sec
MapReduce Total cumulative CPU time: 6 seconds 20 msec
Ended Job = job_1569814058022_0010
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 6.02 sec HDFS Read: 13464 HDFS Write: 205 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 20 msec
OK
e.empno e.ename d.deptno
7934 MILLER 10
7839 KING 10
7782 CLARK 10
7876 ADAMS 20
7788 SCOTT 20
7369 SMITH 20
7566 JONES 20
7902 FORD 20
7844 TURNER 30
7499 ALLEN 30
7698 BLAKE 30
7654 MARTIN 30
7521 WARD 30
7900 JAMES 30
NULL NULL 40
Time taken: 25.576 seconds, Fetched: 15 row(s)
-----------------------------------------------------------------------
7、多表连接,连接 n个表,至少需要n-1个连接条件。例如:连接三个表,至少需要两个连接条件。
-------------------------------------------------------
hive (db_test)> select e.ename,d.deptno,l.loc_name from emp e
> right join dept d
> on d.deptno = e.deptno
> right join location l
> on d.loc = l.loc;
Query ID = root_20190930125110_255f7f0d-c844-4f61-8864-06071747b890
Total jobs = 3
Execution log at: /tmp/root/root_20190930125110_255f7f0d-c844-4f61-8864-06071747b890.log
2019-09-30 12:51:15 Starting to launch local task to process map join; maximum memory = 518979584
2019-09-30 12:51:15 Dump the side-table for tag: 0 with group count: 3 into file: file:/tmp/root/baf87d5f-4ba1-4620-b4ab-bd3376a8fa5b/hive_2019-09-30_12-51-10_608_8487889403003529651-1/-local-10007/HashTable-Stage-7/MapJoin-mapfile50--.hashtable
2019-09-30 12:51:15 Uploaded 1 File to: file:/tmp/root/baf87d5f-4ba1-4620-b4ab-bd3376a8fa5b/hive_2019-09-30_12-51-10_608_8487889403003529651-1/-local-10007/HashTable-Stage-7/MapJoin-mapfile50--.hashtable (456 bytes)
2019-09-30 12:51:15 End of local task; Time Taken: 0.783 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there‘s no reduce operator
Starting Job = job_1569814058022_0011, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0011/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0011
Hadoop job information for Stage-7: number of mappers: 1; number of reducers: 0
2019-09-30 12:51:23,809 Stage-7 map = 0%, reduce = 0%
2019-09-30 12:51:30,118 Stage-7 map = 100%, reduce = 0%, Cumulative CPU 0.76 sec
MapReduce Total cumulative CPU time: 760 msec
Ended Job = job_1569814058022_0011
Stage-8 is selected by condition resolver.
Stage-2 is filtered out by condition resolver.
Execution log at: /tmp/root/root_20190930125110_255f7f0d-c844-4f61-8864-06071747b890.log
2019-09-30 12:51:34 Starting to launch local task to process map join; maximum memory = 518979584
2019-09-30 12:51:35 Dump the side-table for tag: 0 with group count: 3 into file: file:/tmp/root/baf87d5f-4ba1-4620-b4ab-bd3376a8fa5b/hive_2019-09-30_12-51-10_608_8487889403003529651-1/-local-10005/HashTable-Stage-5/MapJoin-mapfile40--.hashtable
2019-09-30 12:51:35 Uploaded 1 File to: file:/tmp/root/baf87d5f-4ba1-4620-b4ab-bd3376a8fa5b/hive_2019-09-30_12-51-10_608_8487889403003529651-1/-local-10005/HashTable-Stage-5/MapJoin-mapfile40--.hashtable (482 bytes)
2019-09-30 12:51:35 End of local task; Time Taken: 0.749 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 3 out of 3
Number of reduce tasks is set to 0 since there‘s no reduce operator
Starting Job = job_1569814058022_0012, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0012/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0012
Hadoop job information for Stage-5: number of mappers: 1; number of reducers: 0
2019-09-30 12:51:41,969 Stage-5 map = 0%, reduce = 0%
2019-09-30 12:51:48,214 Stage-5 map = 100%, reduce = 0%, Cumulative CPU 0.83 sec
MapReduce Total cumulative CPU time: 830 msec
Ended Job = job_1569814058022_0012
MapReduce Jobs Launched:
Stage-Stage-7: Map: 1 Cumulative CPU: 0.76 sec HDFS Read: 5721 HDFS Write: 495 SUCCESS
Stage-Stage-5: Map: 1 Cumulative CPU: 0.83 sec HDFS Read: 5649 HDFS Write: 327 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 590 msec
OK
e.ename d.deptno l.loc_name
CLARK 10 北京
KING 10 北京
MILLER 10 北京
NULL 40 北京
SMITH 20 上海
JONES 20 上海
SCOTT 20 上海
ADAMS 20 上海
FORD 20 上海
ALLEN 30 深圳
WARD 30 深圳
MARTIN 30 深圳
BLAKE 30 深圳
TURNER 30 深圳
JAMES 30 深圳
Time taken: 38.661 seconds, Fetched: 15 row(s)
=================================================
十一、排序
1、全局排序 order by,默认ASC升序
----------------------------------------------------
hive (db_test)> select * from dept t order by t.loc;
Query ID = root_20190930125710_2f1dcad9-9b79-4cd3-8749-eb6670075c3e
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1569814058022_0013, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0013/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0013
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-09-30 12:57:16,683 Stage-1 map = 0%, reduce = 0%
2019-09-30 12:57:23,065 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.34 sec
2019-09-30 12:57:29,412 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.14 sec
MapReduce Total cumulative CPU time: 2 seconds 140 msec
Ended Job = job_1569814058022_0013
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.14 sec HDFS Read: 6106 HDFS Write: 69 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 140 msec
OK
t.deptno t.dname t.loc
40 OPERATIONS 1700
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
Time taken: 20.239 seconds, Fetched: 4 row(s)
-------------------------------------------------------------------
2、全局排序 order by,按照DESC降序
-------------------------------------------------------------------
hive (db_test)> select * from dept t order by t.loc desc;
Query ID = root_20190930125819_031a5e31-e8f8-451c-a74f-6efb574b2218
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1569814058022_0014, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0014/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0014
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-09-30 12:58:25,096 Stage-1 map = 0%, reduce = 0%
2019-09-30 12:58:31,355 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.69 sec
2019-09-30 12:58:36,579 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 1.57 sec
MapReduce Total cumulative CPU time: 1 seconds 570 msec
Ended Job = job_1569814058022_0014
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 1.57 sec HDFS Read: 6106 HDFS Write: 69 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 570 msec
OK
t.deptno t.dname t.loc
30 SALES 1900
20 RESEARCH 1800
40 OPERATIONS 1700
10 ACCOUNTING 1700
Time taken: 18.522 seconds, Fetched: 4 row(s)
-----------------------------------------------------------------------
3、多个列排序
----------------------------------------------------------------
hive (db_test)> select * from emp e order by e.mrg,e.empno desc;
Query ID = root_20190930130533_9399053c-f417-41ad-ba60-691f411168b5
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1569814058022_0017, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0017/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0017
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-09-30 13:05:39,585 Stage-1 map = 0%, reduce = 0%
2019-09-30 13:05:45,719 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.83 sec
2019-09-30 13:05:50,891 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 1.7 sec
MapReduce Total cumulative CPU time: 1 seconds 700 msec
Ended Job = job_1569814058022_0017
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 1.7 sec HDFS Read: 8629 HDFS Write: 661 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 700 msec
OK
e.empno e.ename e.job e.mrg e.hiredate e.sal e.comm e.deptno
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
Time taken: 18.567 seconds, Fetched: 14 row(s)
--------------------------------------------------------------------------
4、Sort By:每个MapReduce内部进行排序,分区规则按照key的hash来运算,(区内排序)对全局结果集来说不是排序。
--------------------------------------------------------------------------
1)设置reduce个数
hive (db_test)> set mapreduce.job.reduces=3;
2)查看设置reduce个数
hive (db_test)> set mapreduce.job.reduces;
mapreduce.job.reduces=3
hive (db_test)> select * from emp e order by e.deptno desc;
Query ID = root_20190930131157_a4d6dece-fd99-49bd-923b-5d7e9270bace
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1569814058022_0018, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0018/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0018
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-09-30 13:12:03,731 Stage-1 map = 0%, reduce = 0%
2019-09-30 13:12:09,906 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.47 sec
2019-09-30 13:12:16,064 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.36 sec
MapReduce Total cumulative CPU time: 2 seconds 360 msec
Ended Job = job_1569814058022_0018
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.36 sec HDFS Read: 8558 HDFS Write: 661 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 360 msec
OK
e.empno e.ename e.job e.mrg e.hiredate e.sal e.comm e.deptno
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
Time taken: 20.518 seconds, Fetched: 14 row(s)
----------------------------------------------------------------------
5、Distribute By:类似MR中partition,进行分区,结合sort by使用。注意,Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。
--------------------------------------------------------------------
hive (db_test)> select * from emp e distribute by e.deptno sort by e.empno desc;
Query ID = root_20190930131823_2bbed4ea-3ee7-4127-b6ab-a4947a80b00d
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 3
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1569814058022_0019, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0019/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0019
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 3
2019-09-30 13:18:29,481 Stage-1 map = 0%, reduce = 0%
2019-09-30 13:18:35,732 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.51 sec
2019-09-30 13:18:42,175 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 3.39 sec
2019-09-30 13:18:43,207 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.28 sec
MapReduce Total cumulative CPU time: 4 seconds 280 msec
Ended Job = job_1569814058022_0019
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 3 Cumulative CPU: 4.28 sec HDFS Read: 16236 HDFS Write: 661 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 280 msec
OK
e.empno e.ename e.job e.mrg e.hiredate e.sal e.comm e.deptno
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
Time taken: 20.63 seconds, Fetched: 14 row(s)
---------------------------------------------------------------------
6、cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是倒序排序,不能指定排序规则为ASC或者DESC。
当distribute by和sorts by字段相同时,可以使用cluster by方式。
------------------------------------------------------------------------------------------
hive (db_test)> select * from emp e distribute by e.deptno sort by e.deptno;
Query ID = root_20190930132139_159d2fa4-f677-46ce-8fef-87e53d8d161b
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 3
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1569814058022_0020, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0020/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0020
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 3
2019-09-30 13:21:45,728 Stage-1 map = 0%, reduce = 0%
2019-09-30 13:21:50,938 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.59 sec
2019-09-30 13:21:58,360 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.85 sec
MapReduce Total cumulative CPU time: 3 seconds 850 msec
Ended Job = job_1569814058022_0020
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 3 Cumulative CPU: 3.85 sec HDFS Read: 16236 HDFS Write: 661 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 850 msec
OK
e.empno e.ename e.job e.mrg e.hiredate e.sal e.comm e.deptno
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
Time taken: 20.082 seconds, Fetched: 14 row(s)
===等价于=====
hive (db_test)> select * from emp e cluster by e.deptno;
Query ID = root_20190930132258_39c0a937-f6da-4286-953b-b16c87fc70cf
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 3
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1569814058022_0021, Tracking URL = http://bigdata112:8088/proxy/application_1569814058022_0021/
Kill Command = /opt/module/hadoop-2.8.4/bin/hadoop job -kill job_1569814058022_0021
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 3
2019-09-30 13:23:04,389 Stage-1 map = 0%, reduce = 0%
2019-09-30 13:23:10,626 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.6 sec
2019-09-30 13:23:16,021 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 2.44 sec
2019-09-30 13:23:17,042 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.4 sec
MapReduce Total cumulative CPU time: 3 seconds 400 msec
Ended Job = job_1569814058022_0021
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 3 Cumulative CPU: 3.4 sec HDFS Read: 16236 HDFS Write: 661 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 400 msec
OK
e.empno e.ename e.job e.mrg e.hiredate e.sal e.comm e.deptno
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
Time taken: 19.748 seconds, Fetched: 14 row(s)
==============================================
标签:ber code 运算 而不是 form parse 效果 inpu cal
原文地址:https://www.cnblogs.com/jeff190812/p/11612349.html