标签:趋势 机器 math 维护 层叠 orm 辅助 还需要 依赖
目录
近年来,深度学习在各个NLP任务中都取得了SOTA结果。这一节,我们先了解一下现阶段在自然语言处理领域最常用的特征抽取结构。
本文部分参考张俊林老师的文章《放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较》(写的非常好,学NLP必看博文),这里一方面对博文进行一定程度上的总结,并加上一些个人理解。
在深度学习流行起来之后,随着我们的网络越做越深,我们的神经网络模型越来越像一个黑箱,我们只要喂给它数据,我们的模型就能够根据我们的给予的目标,自动学习抽取对于该任务最有利的特征(这点在CV中更为明显,比如在卷积神经网络的不同层能够输出图像中不同层面上的细节特征),从而实现了著名的“端到端”模型。在这里,我们可以把我们的CNN、RNN以及Transformer看作抽取数据特征的特征抽取器。下面,本文将为大家简单介绍RNN、CNN及NLP新宠Transformer的基本结构及其优缺点。
在2018年以前,在NLP各个子领域的State of Art的结果都是RNN(此处包含LSTM、GRU等变种)得到的。为什么RNN在NLP领域能够有如此广泛的应用?我们知道如果将全连接网络运用到NLP任务上,其会面临三个主要问题:
为了解决上述问题,我们就有了熟悉的RNN网络结构。其通过扫描数据输入的方式,使得每一个时间步的所有网络参数是共享的,且每个时间步不仅会接收当前时刻的输入,同时会接收上一个时刻的输出,从而使得其能够成功利用过去输入的信息来辅助当前时刻的判断。
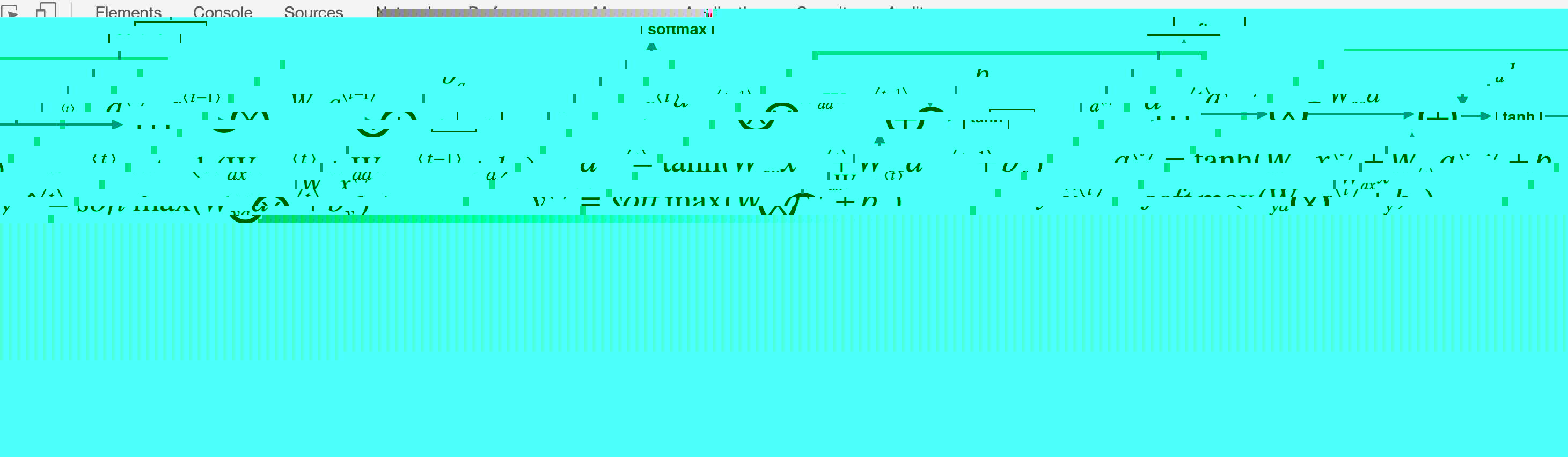
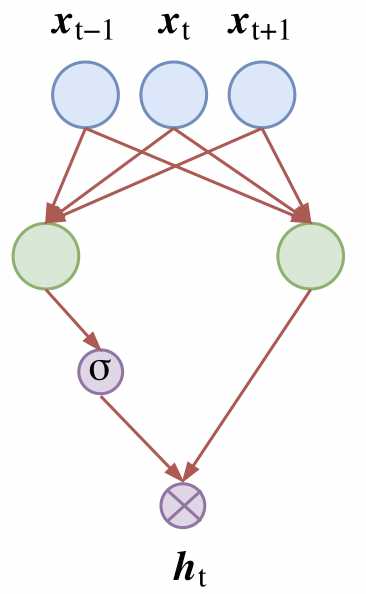
但是,原始的RNN也存在问题,它采取线性序列结构不断从前往后收集输入信息,但这种线性序列结构不擅长捕获文本中的长期依赖关系,如下图所示。这主要是因为反向传播路径太长,从而容易导致严重的梯度消失或梯度爆炸问题。
传统RNN的做法是将的所有知识全部提取出来,不作任何处理的输入到下一个时间步进行迭代。就像参加考试一样,如果希望事先把书本上的所有知识都记住,到了考试的时候,早期的知识恐怕已经被近期的知识完全覆盖了,提取不到长远时间步的信息是很正常的。而人类是这样做的吗?显然不是的,我们通常的做法是对知识有一个理性性判断,重要的知识给予更高的权重,重点记忆,不那么重要的可能没多久就忘了,这样,才能在面对考试的时候有较好的发挥。
在我看来,LSTM的结构更类似于人类对于知识的记忆方式。理解LSTM的关键就在于理解两个状态\(c^{t}\)和\(a^t\)和内部的三个门机制:
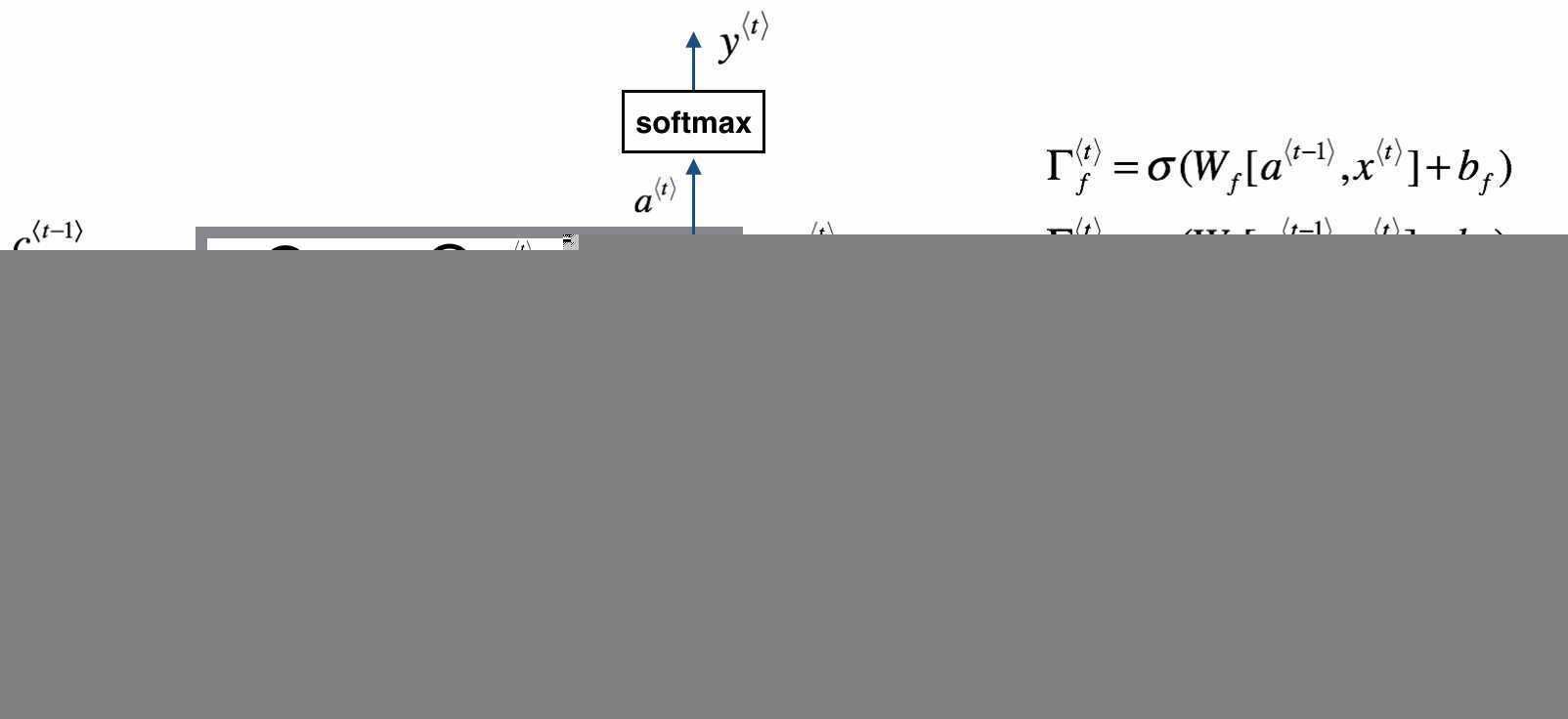
图中我们可以看见,LSTM Cell在每个时间步接收上个时间步的输入有两个,传给下一个时间步的输出也有两个。通常,我们将\(c(t)\)看作全局信息,\(a^t\)看作全局信息对下一个Cell影响的隐藏状态。
遗忘门、输入门(图中的update gate)和输出门分别都是一个激活函数为sigmoid的小型单层神经网络。由于sigmoid在\((0, 1)\)范围内的取值,有效的用于判断是保留还是“遗忘”信息(乘以接近1的值表示保留,乘以接近0的值表示遗忘),为我们提供了信息选择性传输的能力。这样,我们就很好理解门在LSTM是怎样工作的了:
这样看下来,是不是觉得LSTM已经十分"智能"了呢?但实际上,LSTM还是有其局限性:时序性的结构一方面使其很难具备高效的并行计算能力(当前状态的计算不仅要依赖当前的输入,还要依赖上一个状态的输出),另一方面使得整个LSTM模型(包括其他的RNN模型,如GRU)总体上更类似于一个马尔可夫决策过程,较难以提取全局信息。
关于GRU的结构我这里就不细讲了,在参考文献中有很多相关资料,大家想了解的可以去看看,简单来说,GRU可以看作一个LSTM的简化版本,其将\(a^t\)与\(c^t\)两个变量整合在一起,且讲遗忘门和输入门整合为更新门,输出门变更为重制门,大体思路没有太大变化。两者之间的性能往往差别不大,但GRU相对来说参数量更少。收敛速度更快。对于较少的数据集我建议使用GRU就已经足够了,对于较大的数据集,可以试试有较多参数量的LSTM有没有令人意外的效果。
CNN是计算机视觉领域的重大突破,也是目前用于处理CV任务模型的核心。CNN同样适用于NLP任务中的特征提取,但其使用场景与RNN略有不同,这部分我会多写一点,因为关于CNN在NLP任务中的应用大家相对来说应该都没那么了解。
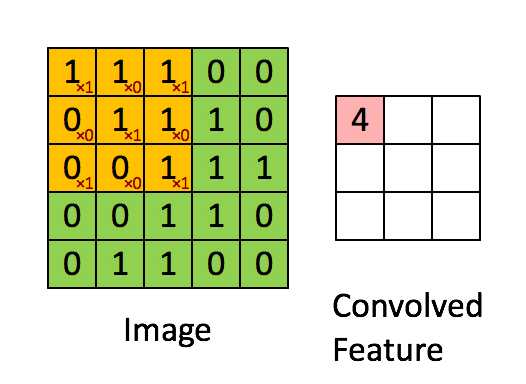
关于二维卷积核的运算如下图所示,我就不赘述了。
从数据结构上来看,CV任务中的输入数据为图像像素矩阵,其各个方向上的像素点之间的相关性基本上是等同的。而NLP任务中的输入数据通常为序列文本,假设句子长度为\(n\),我们词向量的维度为\(d\),我们的输入就成了一个\(n \times d\)的矩阵,显然,该矩阵的行列“像素”之间的相关性是不一样的,矩阵的同一行为一个词的向量表征,而不同行表示不同词。要让卷积网络能够正常的”读“我们的文本,我们在NLP中就需要使用一维卷积。Kim在2014年首次将CNN用于NLP中的文本分类任务,其提出的网络结构如下图所示:
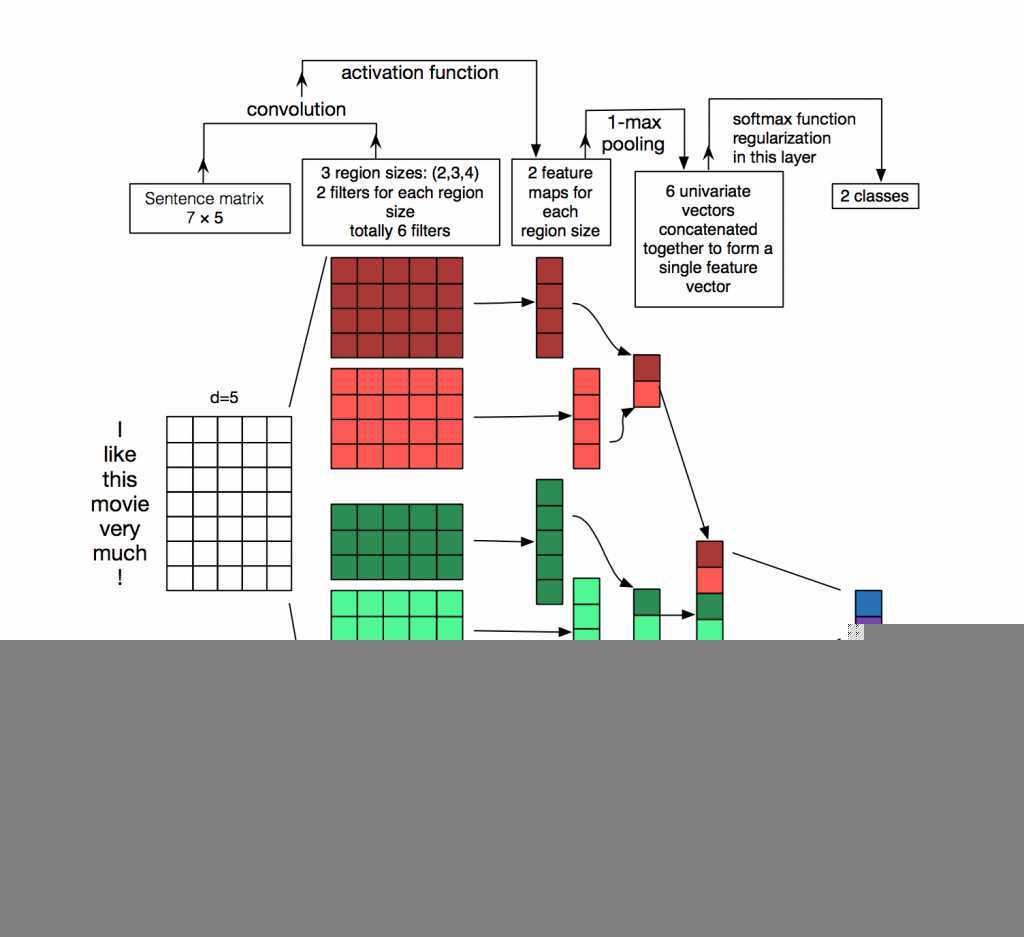
可以看见,一维卷积与二维卷积不同的是,每一个卷积核的宽度与词向量的维度\(d\)是相同的,以保证卷积核每次处理n个词的完整词向量,从上往下依次滑动卷积,这个过程中的输出就成了我们需要的特征向量。这就是CNN抽取特征的过程。在卷积层之后通常接上Max Pooling层(用于抽取最显著的特征),用于对输出的特征向量进行降维提取操作,最后再接一层全连接层实现文本分类。
虽然传统CNN经过简单的改变之后可以成功的应用于NLP任务,且效果还不错,但效果也仅仅是“不错“而已,很多任务还是处于完全被压制的情况。这表明传统的CNN在NLP领域中还是存在一些问题。
谈到CNN在NLP界的进化,我们首先来看看Kim版CNN存在哪些问题。
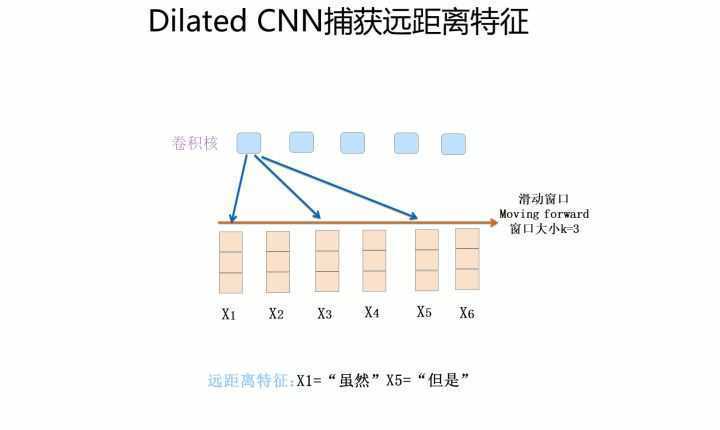
为了解决上述问题,研究者们采取了一系列方法对Kim版的CNN进行改进。
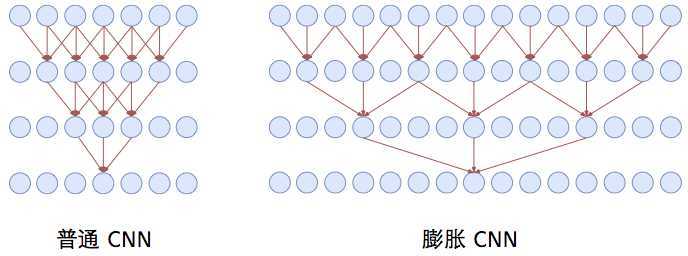
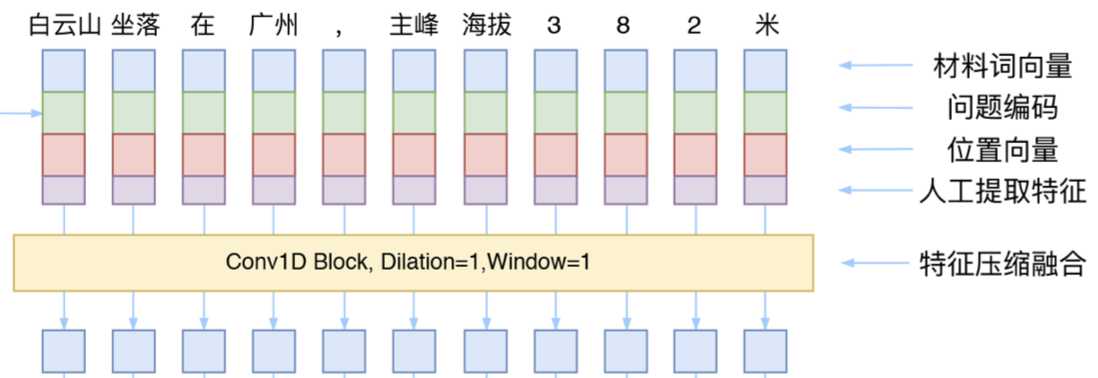
在很多地方都看见CNN比较适用于文本分类的任务,事实上,从《Convolutional Sequence to Sequence Learning》、《Fast Reading Comprehension with ConvNets》等论文与实践报告来看,CNN已经发展成为一种成熟的特征提取器,并且,相比于RNN来说,CNN的窗口滑动完全没有先后关系,不同卷积核之前也没有相互影响,因此其具有非常高的并行自由度,这是其非常好的一个优点。
Transformer是在论文《Attentnion is all you need》里首次被提出的。
Transformer详解推荐这篇文章:https://zhuanlan.zhihu.com/p/54356280
在介绍Transformer之前,我们先来看看Encoder-Decoder框架。现阶段的深度学习模型,我们通常都将其看作黑箱,而Encoder-Decoder框架则是将这个黑箱分为两个部分,一部分做编码,另一部分做解码。
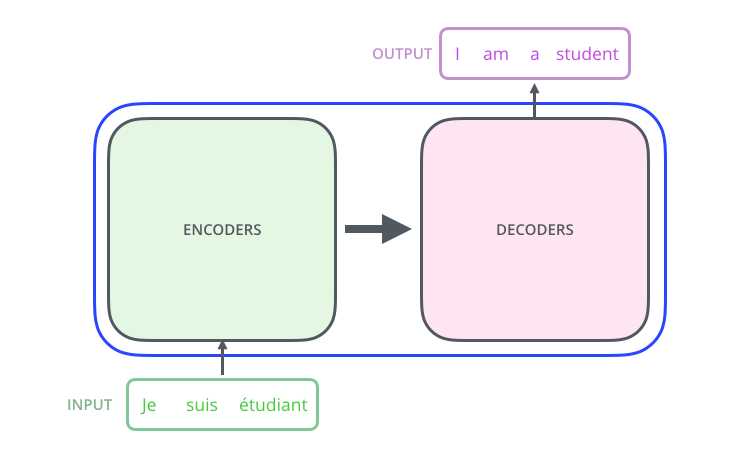
在不同的NLP任务中,Encoder框架及Decoder框架均是由多个单独的特征提取器堆叠而成,比如说我们之前提到的LSTM结构或CNN结构。由最初的one-hot向量通过Encoder框架,我们将得到一个矩阵(或是一个向量),这就可以看作其对输入序列的一个编码。而对于Decoder结构就比较灵活饿了,我们可以根据任务的不同,对我们得到的“特征”矩阵或“特征”向量进行解码,输出为我们任务需要的输出结果。因此,对于不同的任务,如果我们堆叠的特征抽取器能够提取到更好的特征,那么理论上来说,在所有的NLP任务中我们都能够得到更好的表现。
在2018年谷歌推出BERT,刷新各项记录,引爆了整个NLP界,其取得成功的一个关键因素是新的特征提取结构:Transformer的强大作用。
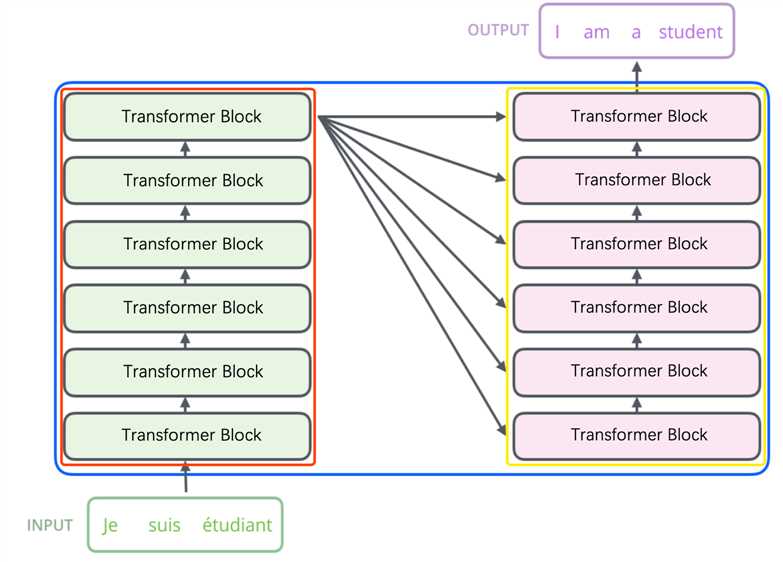
Transformer结构是在论文《Attention is All You Need》中提出的的模型,如上图所示。图中红框内为Encoder框架,黄框内为Decoder框架,其均是由多个Transformer Block堆叠而成的。这里的Transformer Block就代替了我们之前提到的LSTM和CNN结构作为了我们的特征提取器,也是其最关键的部分。更详细的示意图如下图所示。我们可以发现,编码器中的Transformer与解码器中的Transformer是有略微区别的,但我们通常使用的特征提取结构(包括Bert)主要是Encoder中的Transformer,那么我们这里主要理解一下Transformer在Encoder中是怎么工作的。
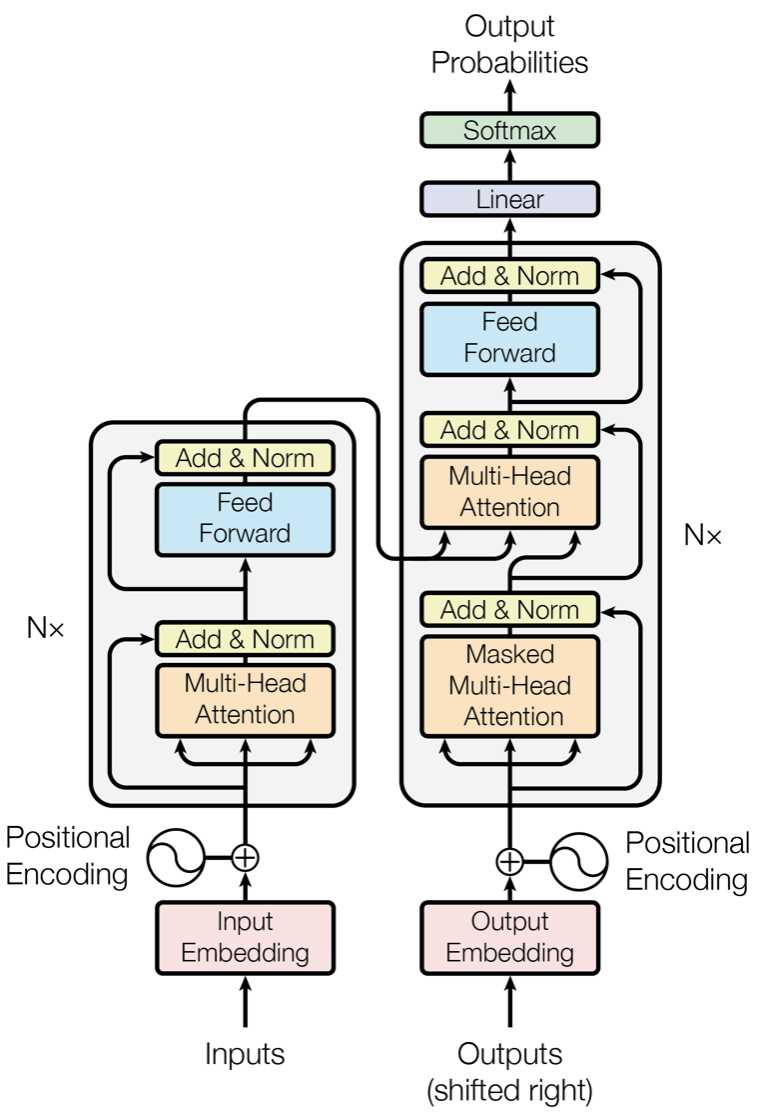
由上图可知,单个的Transformer Block主要由两部分组成:多头注意力机制(Multi-Head Attention)和前馈神经网络(Feed Forward)。
Multi-Head Attention模块结构如下图所示:
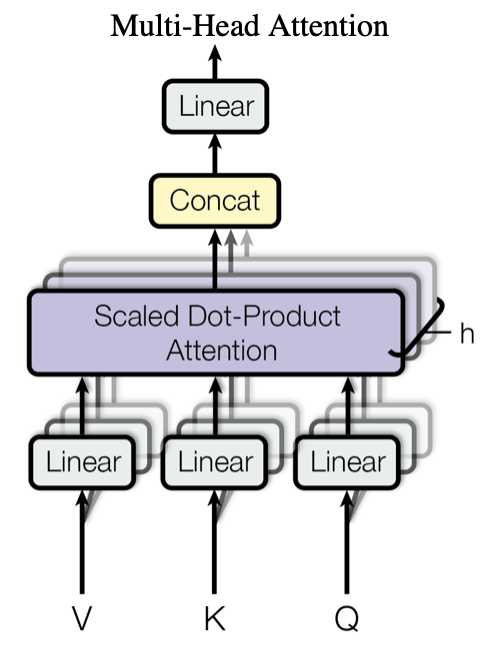
这里,我们就可以明白为什么这一部分被称为Multi-Head了,因为其本身就是由\(h\)个子模块Scaled Dot-Product Attention堆叠而成的,该模块也被称为Self-Attention模块。关于整个Multi-Head Attention,主要有一下几个关键点需要理解:
在Multi-Head Attention中,最关键的部分就是Self-Attention部分了,这也是整个模型的核心配方,我们将其展开,如下图所示。
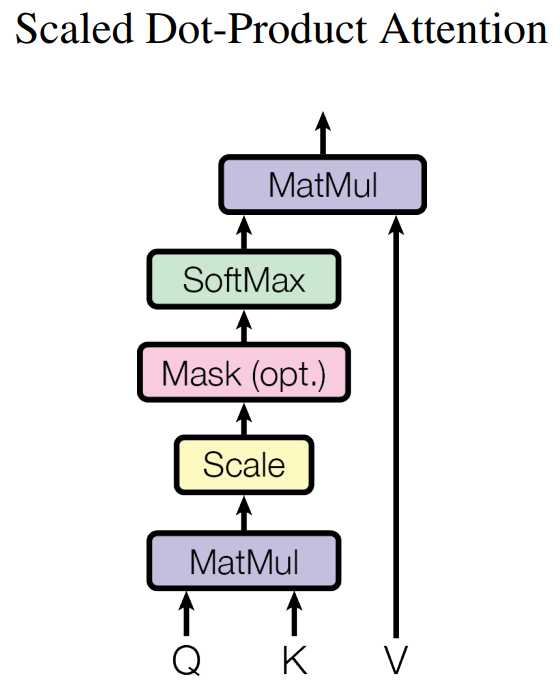
我们之前已经提到过,Self-Attention的输入仅仅是矩阵\(X\)的三个线性映射。那么Self-Attention内部的运算具有什么样的含义呢?我们从单个词编码的过程慢慢理解:
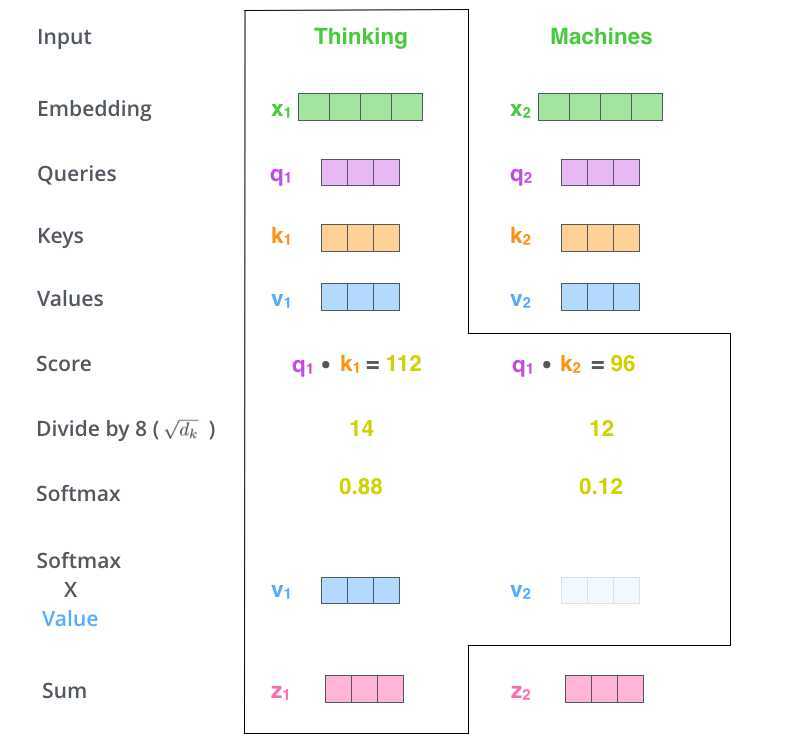
其实仔细思考一下就可以发现,Self-Attention与CNN是十分相似的。CNN通过简单的卷积运算提取特征,虽然有Dilated Convolution以及增加深度等方式来增大感受野,但是其本质上是一个n-gram模型。而在Self-Attention中,\(W^Q\), \(W^K\), \(W^V\)不也能看作三个卷积核吗,但是其通过一种更加巧妙的方式将卷积运算的结果进行整合,实现了直观上所谓的”注意力“,从而使得每一个词的编码结果均是句子中所有词的共同作用结果,其本质上是一个超大的词袋模型(包括句子中所有的词)。显然,上述过程可以用以下的矩阵形式进行并行计算:
\[Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\]
其中,Q, V, K分别表示输入句子的Queries, Keys, Values矩阵,矩阵的每一行为每一个词对应的向量Query, Key, Value向量,\(d_k\)表示向量长度。因此,Transformer同样也具有十分高效的并行计算能力。
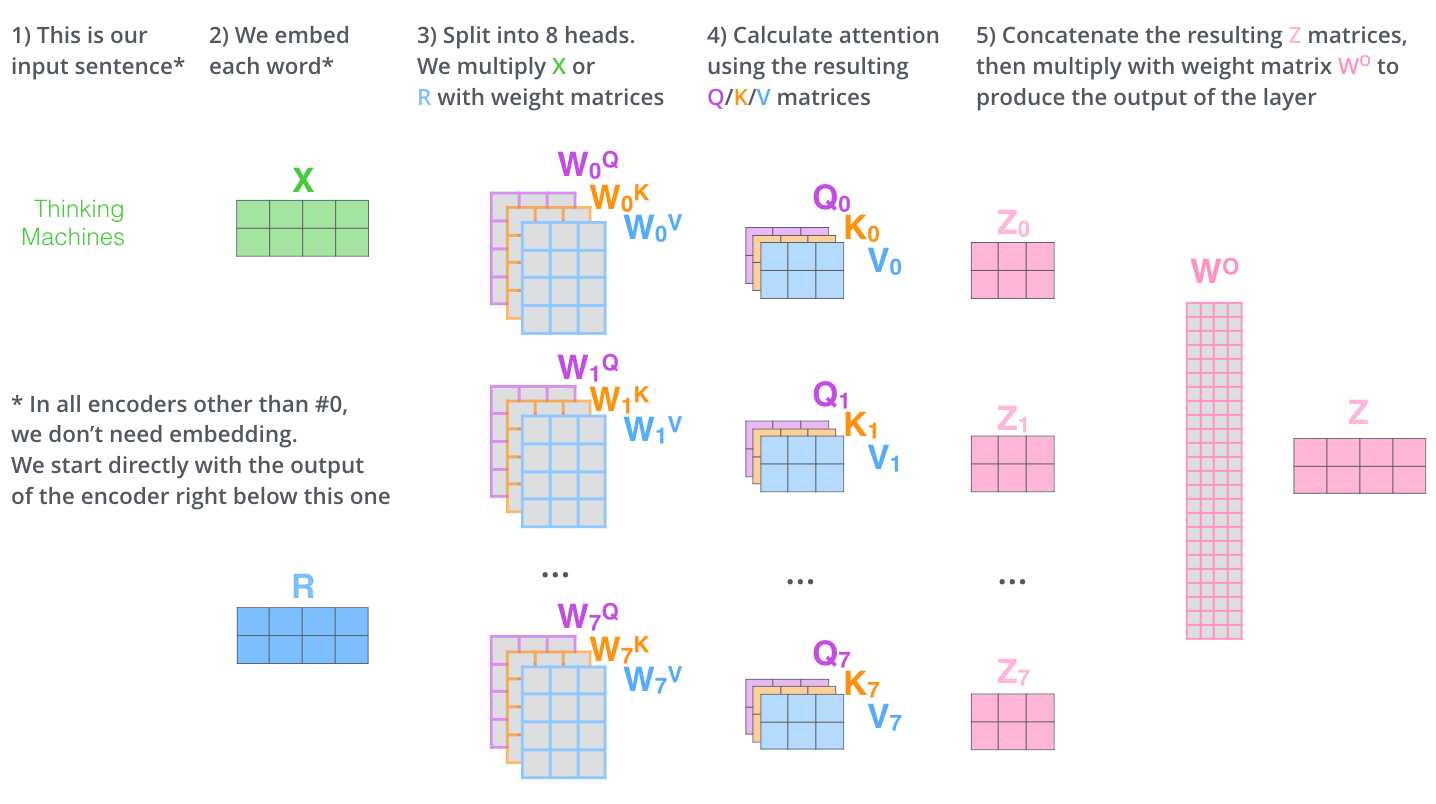
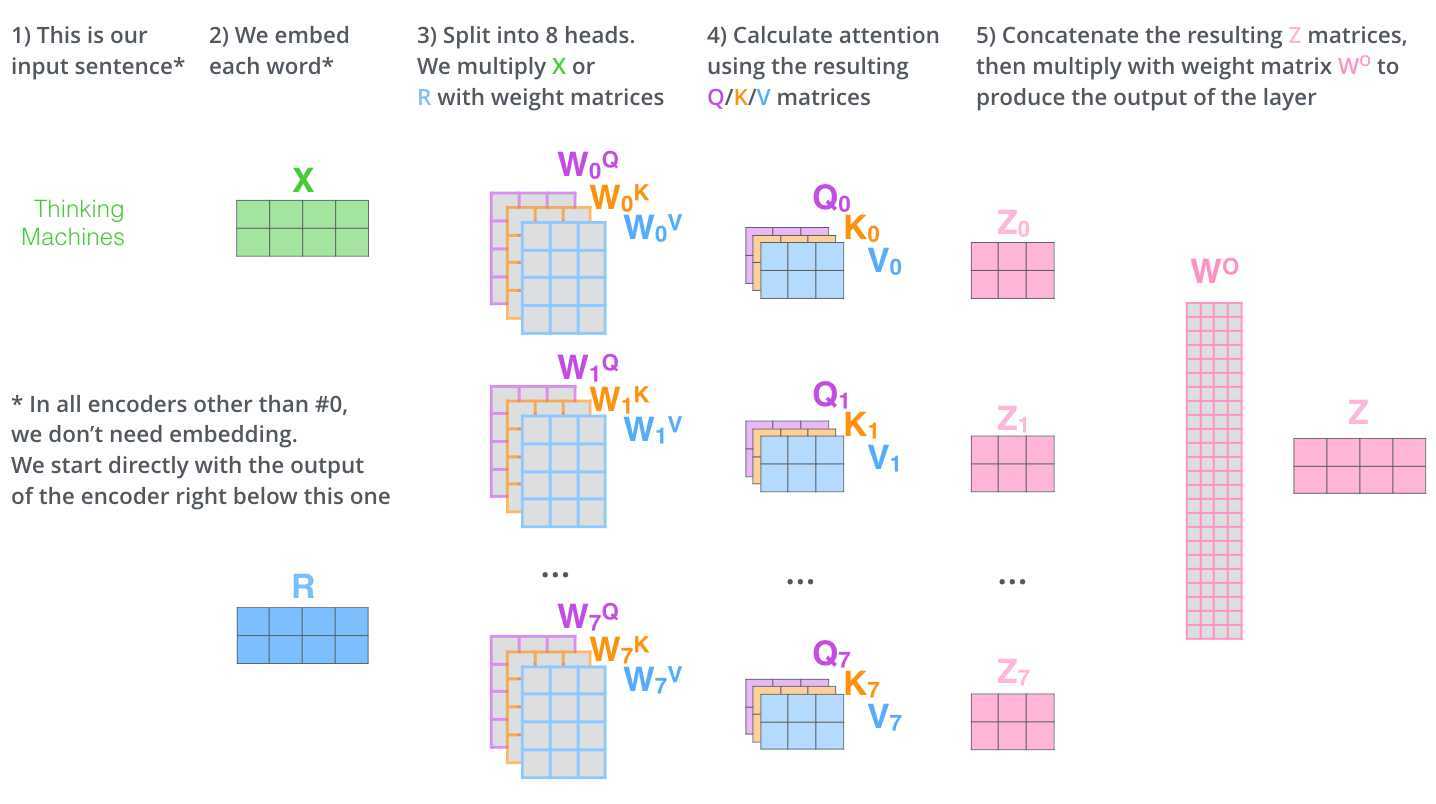
我们再回到Multi-Head Attention,我们将独立维护的8个Self-Attention的输出进行简单的拼接,通过一个先行映射层,就得到了单个多头注意力的输出。其整个过程可以总结为下面这个示意图:
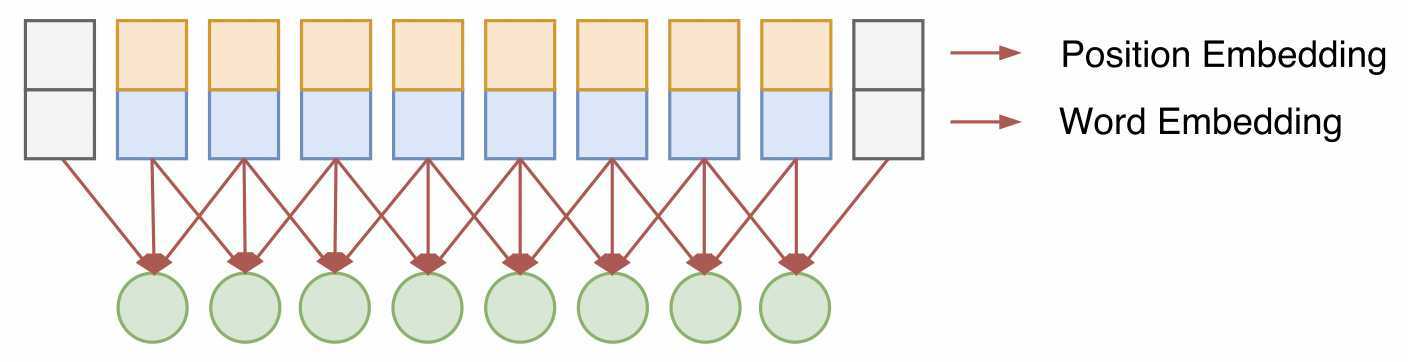
我们之前提到过,由于RNN的时序性结构,所以天然就具备位置编码信息。CNN本身其实也能提取一定位置信息,但多层叠加之后,位置信息将减弱,位置编码可以看作是一种辅助手段。Transformer的每一个词的编码过程使得其基本不具备任何的位置信息(将词序打乱之后并不会改变Self-Attention的计算结果),因此位置向量在这里是必须的,使其能够更好的表达词与词之间的距离。构造位置编码的公式如下所示:
\[\begin{cases} PE_{2i}(p)=sin(p/10000^{2i/d_{pos}}) \PE_{2i+1}(p)=cos(p/10000^{2i/d_{pos}}) \end{cases}\]
如果词嵌入的长度\(d_{pos}\),则我们需要构造一个长度同样为\(d_{pos}\)的位置编码向量\(PE\)。其中\(p\)表示词的位置,\(PE_i(p)\)表示第p个词位置向量中的第i个元素的值,然后将词向量与位置向量直接相加。该位置编码不仅仅包含了绝对位置信息,由\(sin(\alpha + \beta) = sin \alpha cos \beta + cos \alpha sin \beta\)以及\(cos(\alpha + \beta) = cos \alpha cos \beta - sin \alpha sin \beta\),这意味着我们可以\(p+k\)的位置向量可表示为位置\(p\)位置向量的线性变换,使得相对位置信息也得到了表达。Transformer论文中提到过他们用该方式得到的位置编码向量与训练得到的位置编码向量效果是十分接近的。
我们之前说到Self-Attention与CNN的相似性。这里的残差运算同样是借鉴了CNN中的思想,其原理基本是一样的,我就不赘述了。在残差连接之后,还需要进行层归一化操作,其具体过程与Layer Normalization一致。
到这里,整个Transformer的结构基本讲述完毕了。关于其相与RNN和CNN的性能比较,张俊林老师的文章里有详细的数据说明,我仅附上简单的总结:
由于平常科研任务也比较重,代码暂时没有时间上传,等发布序列标注以及文本分类等文章的时候代码会同步上传到Github,RNN/CNN/Transformer的代码也会包含在其中。
https://zhuanlan.zhihu.com/p/54743941
http://www.ai-start.com/dl2017/html/lesson5-week1.html#header-n194
https://zhuanlan.zhihu.com/p/46327831
https://zhuanlan.zhihu.com/p/55386469
https://kexue.fm/archives/5409
https://zhuanlan.zhihu.com/p/54356280
http://jalammar.github.io/illustrated-transformer/
https://kexue.fm/archives/4765
标签:趋势 机器 math 维护 层叠 orm 辅助 还需要 依赖
原文地址:https://www.cnblogs.com/sandwichnlp/p/11612596.html