标签:lun mem exec 暂停 重复 iii 实时计算 http test
指访问某个站点或点击某个网页的不同IP地址的人数。在同一天内,UV只记录第一次进入网站的具有独立IP的访问者,在同一天内再次访问该网站则不计数。UV提供了一定时间内不同观众数量的统计指标,而没有反应出网站的全面活动。
页面浏览量或点击量,是衡量一个网站或网页用户访问量。具体的说,PV值就是所有访问者在24小时(0点到24点)内看了某个网站多少个页面或某个网页多少次。PV是指页面刷新的次数,每一次页面刷新,就算做一次PV流量。
顾名思义,就是获取前10或前N的数据。
这里主要使用hive或者MapReduce计算
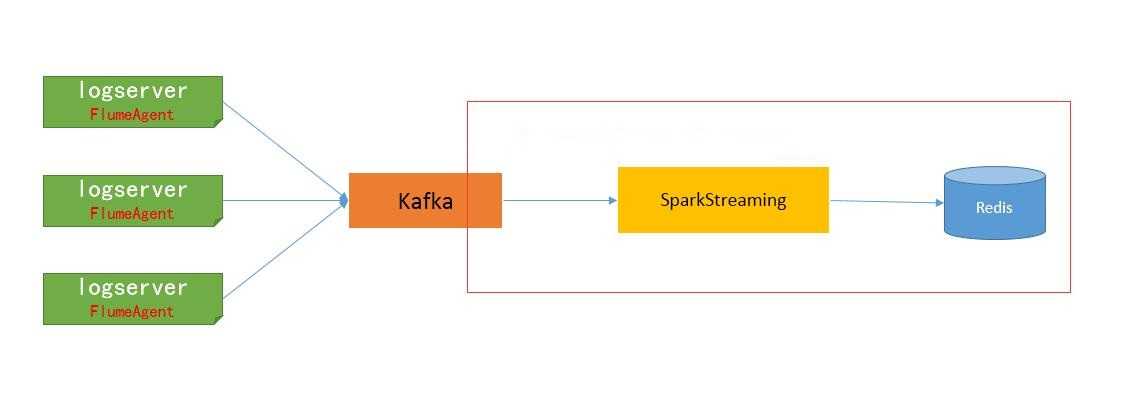
在实时流式计算中,最重要的是在任何情况下,消息不重复、不丢失,即Exactly-once。本文以Kafka->Spark Streaming->Redis为例,一方面说明一下如何做到Exactly-once,另一方面说明一下如何计算实时去重指标的。
日志格式为:
2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=DEIBAH&siteid=3
2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=GLLIEG&siteid=3
2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=HIJMEC&siteid=8
2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=HMGBDE&siteid=3
2018-02-22T00:00:00+08:00|~|200|~|/test?pcid=HIJFLA&siteid=4
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=JCEBBC&siteid=9
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=KJLAKG&siteid=8
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=FHEIKI&siteid=3
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=IGIDLB&siteid=3
2018-02-22T00:00:01+08:00|~|200|~|/test?pcid=IIIJCD&siteid=5
日志是由测试程序模拟产生的,字段之间由|~|分隔。pcid为计算机pc的id,siteid为网站id
分天、分小时PV、UV;
分天、分小时、分网站(siteid)PV、UV;
在Spark Streaming中消费Kafka数据,保证Exactly-once的核心有三点:
①使用Direct方式连接Kafka;
②自己保存和维护Offset;
③更新Offset和计算在同一事务中完成;
后面的Spark Streaming程序,主要有以下步骤:
①启动后,先从Redis中获取上次保存的Offset,Redis中的key为“topic_partition”,即每个分区维护一个Offset;
②使用获取到的Offset,创建DirectStream;
③在处理每批次的消息时,利用Redis的事务机制,确保在Redis中指标的计算和Offset的更新维护,在同一事务中完成。只有这两者同步,才能真正保证消息的Exactly-once。
./spark-submit --class com.lxw1234.spark.TestSparkStreaming --master local[2] --conf spark.streaming.kafka.maxRatePerPartition=20000 --jars /data1/home/dmp/lxw/realtime/commons-pool2-2.3.jar,/data1/home/dmp/lxw/realtime/jedis-2.9.0.jar,/data1/home/dmp/lxw/realtime/kafka-clients-0.11.0.1.jar,/data1/home/dmp/lxw/realtime/spark-streaming-kafka-0-10_2.11-2.2.1.jar /data1/home/dmp/lxw/realtime/testsparkstreaming.jar --executor-memory 4G --num-executors 1
在启动Spark Streaming程序时候,有个参数最好指定:
spark.streaming.kafka.maxRatePartition=20000(每秒钟从topic的每个partition最多消费的消息条数)
如果程序第一次运行,或者因为某种原因暂停了很久重新启动时候,会积累很多消息,如果这些消息同时被消费,很有可能会因为内存不够而挂掉,因此,需要根据实际的数据量大小,以及批次的间隔时间来设置该参数,以限定批次的消息量。
如果该参数设置20000,而批次间隔时间未10秒,那么每个批次最多从Kafka中消费20万消息。
① 分小时、分网站PV
普通K-V结构,计算时候使用incr命令递增,
Key为 “site_pv_网站ID_小时”,
如:site_pv_9_2018-02-21-00、site_pv_10_2018-02-12-01
② 分小时PV、分天PV
普通K-V结构,计算时候使用incr命令递增,
Key为 “pv_小时”,如:pv_2018-02-21-14、pv_2018-02-22-03
该数据模型用于计算按小时及按天总PV。
③ 分小时、分网站UV
Set结构,计算时候使用sadd命令添加,
Key为 “site_uv_网站ID_小时”,如:site_uv_8_2018-02-21-12、site_uv_6_2019-09-12-09
该数据模型用户计算按小时和网站的总UV(获取时候使用SCARD命令获取Set元素个数)
④ 分小时UV、分天UV
Set结构,计算时候使用sadd命令添加,
Key为 “uv_小时”,如:uv_2018-02-21-08、uv_2018-02-20-09
该数据模型用户计算按小时及按天的总UV(获取时候使用SCARD命令获取Set元素个数)
注意:这些Key对应的时间,均有实际消息中的第一个字段(时间)而定。
如果Spark Streaming程序因为停电、网络等意外情况终止而需要恢复,则直接重启即可;
【参考资料】
http://www.cj318.cn/?p=4
https://blog.csdn.net/liam08/article/details/80155006
http://www.ikeguang.com/2018/08/03/statistic-hive-daily-week-month/
https://dongkelun.com/2018/06/25/KafkaUV/
https://blog.csdn.net/wwwzydcom/article/details/89506227
http://lxw1234.com/archives/2018/02/901.htm
标签:lun mem exec 暂停 重复 iii 实时计算 http test
原文地址:https://www.cnblogs.com/swordfall/p/11161314.html