标签:style blog http io color ar 使用 sp strong
本栏目来源于对Coursera 在线课程 NLP(by Michael Collins)的理解。课程链接为:https://class.coursera.org/nlangp-001
1. 语言模型定义:
Model Representation:
例如:假设c(x1x2...xn)是x1x2...xn在语料中出现的频次,N是语料句子总数,定义 p(x1,x2,...,xn)=c(x1x2...xn)/N 但是该模型效果很差由于其无法预测语料中未出现的新单词。
2. 马尔科夫模型(Markov Model)
2.1 定长序列的马尔科夫模型
假设单词序列x1x2...xn为定长的n,对于联合概率P(X1=x1,X2=x2,...Xn=xn),可见x1x2...xn有|V|n种组合。
![]()
因此序列x1x2...xn出现的概率为:
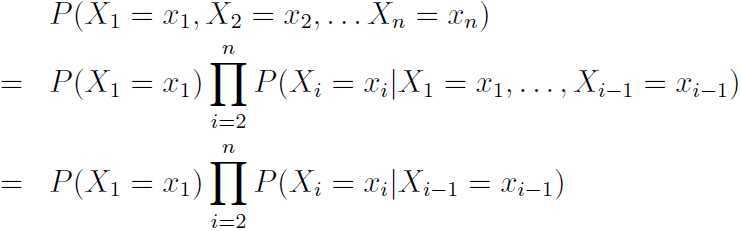
![]()
因此序列x1x2...xn出现的概率为:
![]()
PS:定义x0=x-1=*,即句子序列开始符。
2.1 变长序列的马尔科夫模型
假设单词序列x1x2...xn为可变长度的句子序列,即n为随机变量,此时假设xn为STOP符唯一的表示句子的结尾。继续使用前面的假设,对于二阶马尔科夫过程:
![]() 其中xn=STOP
其中xn=STOP
计算流程为:
3. Trigram语言模型
假设P(Xi=xi | Xi-2=xi-2,Xi-1=xi-1) = q(xi | xi-2,xi-1)
其中q(w | u,v)对任意(u,v,w)是模型的参数,w属于集合{V,STOP},u,v属于集合{V,*},x0 = x-1 =*,模型形式如下:
![]()
其中q(w|u,v)≥0 且![]()
例如:句子序列 the dog barks STOP
p(the dog barks STOP)=q(the|*,*)×q(dog|*,the)×q(barks|the,dog)×q(STOP|dog,barks)
4. 极大似然估计(Maximum-Likelihood Estimates)
定义c(u,v,w)为trigram(u,v,w)在训练语料中出现的频次,例如c(the,dog,barks)即 “the dog barks”序列在语料中出现的次数,同理c(u,v)为bigram(u,v)在语料中出现的频次,对任意u,v,w,定义:
![]()
例如:q(the,dog,barks)估计为:![]()
由于词数量庞大,该方法的问题有:
5. 语言模型评估:复杂度(Perplexity)
假设测试集为x(1),x(2),...x(n).其中x(i)为序列,x1(i)x2(i)...xni(i),ni为第i个测试句子的长度并以STOP作为结束符。一种模型的评价标准为计算整个测试集句子出现的概率,即:
![]()
PS:概率值越大,模型对新词的预测效果越好。
![]()
平均log概率为:
![]()
模型复杂度定义为 2-l ,其中 ![]()
PS:复杂度越小,模型对于预测新数据的效果越好。
例如:对于语言模型 q(w|u,v)=1/N,这时该模型的复杂度为N,可见是很差的模型。
6 Trigram模型的平滑估计
借助bigram和unigram的结果来平滑trigram模型。可以使用linear interpolation(线性插值)和discounting methods。
6.1 Linear Interpolation
定义trigram,bigram和unigram的极大似然估计为:
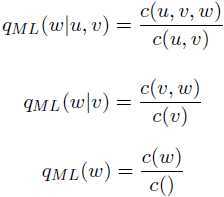
其中c(w)是词w在训练语料中出现的次数,c()是训练语料的总词数。trigram,bigram和unigram有各自的优缺点。unigram不会出现算式分子或分母为0的情况,但是却忽略了句子上下文的关系;相反,trigram充分利用了文本关系但很多算式结果为0.
Linear Interpolation应用如下定义来平滑模型:
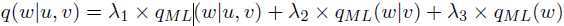
其中λ1≥0,λ2≥0,λ3≥0是模型的另外参数,且λ1+λ2+λ3=1。为trigram,bigram和unigram的权重参数。
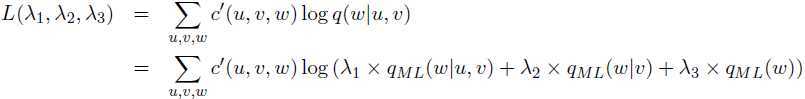
目标函数:![]()
在实际应用中,当c(u,v)很大时,可以增大λ1(由于大的c(u,v)说明trigram更加有效);当c(u,v)=0时,令λ1=0(由于此时qML(w|u,v)没有定义);同理若c(u,v),c(v)都为0,我们就需要λ1=λ2=0(由于trigram,bigram都无定义).
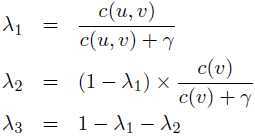
其中γ>0,该方法相对粗糙,可能并非最优,但是很简单。
6.2 Discounting Methods
定义discounted counts: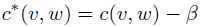 其中任意bigram c(v,w)>0,β在0和1之间;
其中任意bigram c(v,w)>0,β在0和1之间;
因此定义:![]()
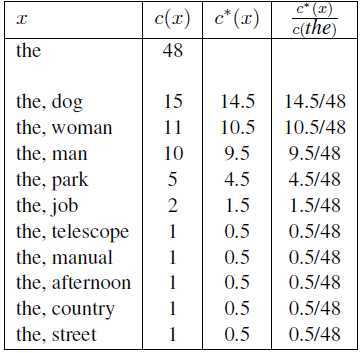
例如:对如下数据,词"the"在语料中共出现了48次,下表列出了所有的bigram。另外我们利用discounted count c*(x)=c(x)-β。且β=0.5 最后计算c*(x)/c(the).该定义造成了一些概率丢失,定义如下:
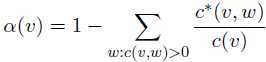
本例中,![]() ,
,![]()
完整定义如下: A(v)={w:c(v,w)>0}且B(v)={w:c(v,w)=0}
本例中,A(the)={dog,woman,man,park,job,telescope,manual,afternoon,country,street},B(the)是此表中其余集合。
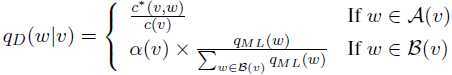
因此,若c(v,w)>0,返回c*(v,w)/c(v);否则,将α(v)成比例地分给unigram来评估qML(w)。
A(u,v)={w:c(u,v,w)>0}且B(u,v)={w:c(u,v,w)=0}
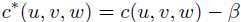
故trigram模型为:
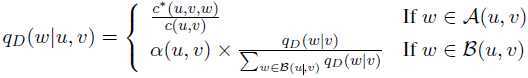
其中:![]()
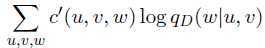
通常我们为β设置可能的数值集合(例如{0.1,0.2,0.3,...,0.9})分别计算其log似然概率,从中选出令log似然概率最大的β即可。
本文为原创博客,若转载请注明出处。
@%T2C5(Q`Y6.png)
Language Modeling---NLP学习笔记(原创)
标签:style blog http io color ar 使用 sp strong
原文地址:http://www.cnblogs.com/tec-vegetables/p/4053795.html