标签:mamicode ext 向量 ted zed ase http 阅读 encode
同样的单词有不同的意思,比如下面的几个句子,同样有 “bank” ,却有着不同的意思。但是用训练出来的 Word2Vec 得到 “bank” 的向量会是一样的。向量一样说明 “word” 的意思是一样的,事实上并不是如此。这是 Word2Vec 的缺陷。
下面的句子中,同样是“bank”,确是不同的 token,只是有同样的 type
 我们期望每一个 word token 都有一个 embedding。每个 word token 的 embedding 依赖于它的上下文。这种方法叫做 Contextualized Word Embedding。
我们期望每一个 word token 都有一个 embedding。每个 word token 的 embedding 依赖于它的上下文。这种方法叫做 Contextualized Word Embedding。
EMLO 是 Embeddings from Language Model 的缩写,它是一个 RNN-based 的模型,只需要有大量句子就可以训练。
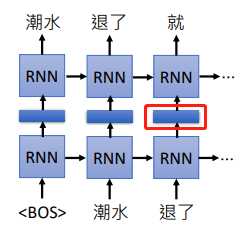
我们可以把训练的 RNN 隐藏层的权重拿出来,把词汇经过隐藏层后输出的向量当做这个单词的 embedding,因为 RNN 是考虑上下文的,所以同一个单词在不同的上下文中它会得到不同的向量。上面是一个正向里的 RNN,如果觉得考虑到的信息不够,可以训练双向 RNN ,同样将隐藏层的输出作为 embedding。
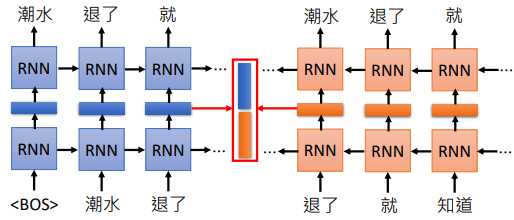
如果我们的 RNN 有很多层,我们要拿那一隐藏层的输出作为 embedding?
 在 ELMO 中,它取出每一层得到的向量,经过运算得到我们每一个单词的 embedding
在 ELMO 中,它取出每一层得到的向量,经过运算得到我们每一个单词的 embedding
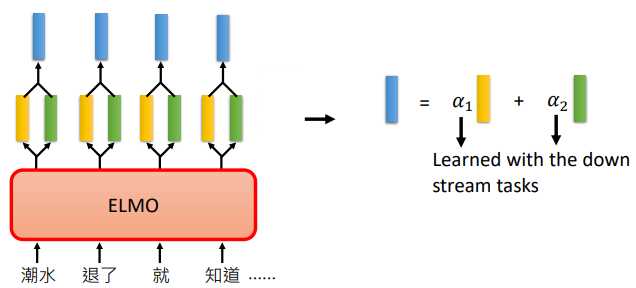
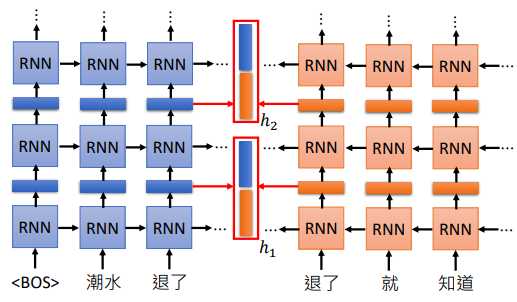
比如上图,假设我们有2层,所以每个单词都会得到 2 个向量,最简单的方法就是把两个向量加起来作为这个单词的embedding。
EMLO中会把两个向量取出来,然后乘以不同的权重 $\alpha $,再将得到的我们得到的 embedding 做下游任务。
$\alpha $ 也是模型学习得到的,它会根据我们的下游任务一起训练得到,所以不同的任务用到的 $\alpha $ 是不一样的
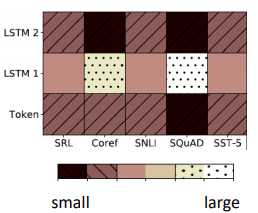
比如我们的 embedding 可以有3个来源,如上图所示。分别是
颜色的深浅代表了权重的大小,可以看到不同的任务(SRL、Coref 等)有着不同的权重。
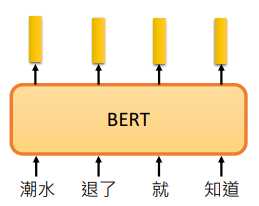
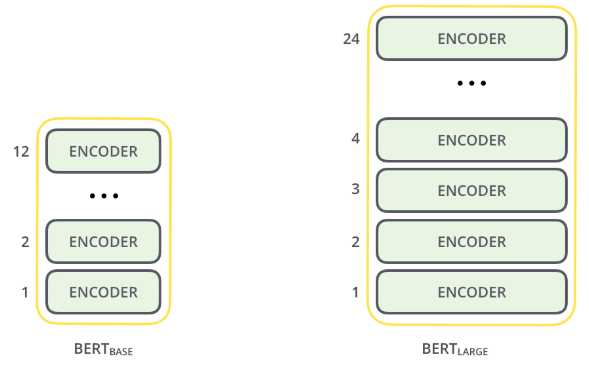
BERT 是 Bidirectional Encoder Representations from Transformers 的缩写,BERT 是 Transformer 中的 Encoder。它由许多个 Encoder 堆叠而成
在 BERT 里面,我们的文本是不需要标签的,只有收集到一堆句子就可以训练了。
BERT 是 Encoder,所以可以看成输入一个句子,输出 embedding,每个 embedding 对应一个 word
上图的例子我们是以 “词” 为单位,有时候我们以 “字” 为单位会更好。比如中文的 “词” 是很多的,但是常用的 “字” 是有限的。
在 BERT 中,有两种训练方法,一种是 Masked LM。另一种是 Next Sentence Prediction。但一般同时使用,会取得更好的效果。
在 Masked LM 中,我们会把输入的句子中随机将15%的词汇置换为一个特殊的 token ,叫做 [MASK]
BERT 的任务就是猜出这些被置换掉的词汇的什么。
就像是一个填词游戏,挖去一句话中的某个单词,让你自己填上合适的单词
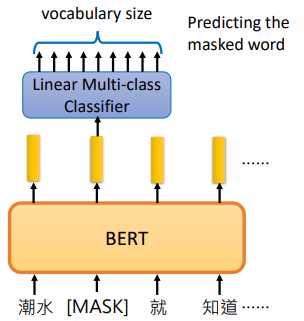
经过 BERT 后我们得到一个 embedding,再把置换为 [MASK] 的那个位置输出的 embedding 通过一个线性分类器,预测这个单词是什么
因为这个分类器是 Linear 的,所以它的能力非常非常弱,所以 BERT 要输出一个非常好的 embedding,才能预测出被置换掉的单词是什么
如果两个不同的词可以填在同一个句子,他们会有相似的embedding,因为他们语义相近
在 Next Sentence Prediction 中,我们给 BERT 两个句子,让 BERT 预测这两个句子是不是接在一起的
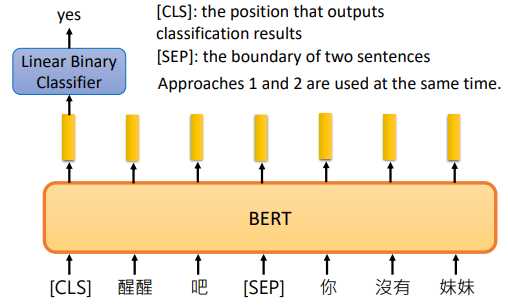
[SEP]:特殊的toekn,代表两个句子的交界处
[CLS]:特殊的token,代表要做分类
我们再把 [CLS] 输出的向量通过一个线性分类器,让分类器判断这两个句子应不应该接在一起。
BERT 是 Transformer 的 Encoder,它用到了 self-attention 机制,可以读到句子的全部信息,所以 [CLS] 可以放在开头
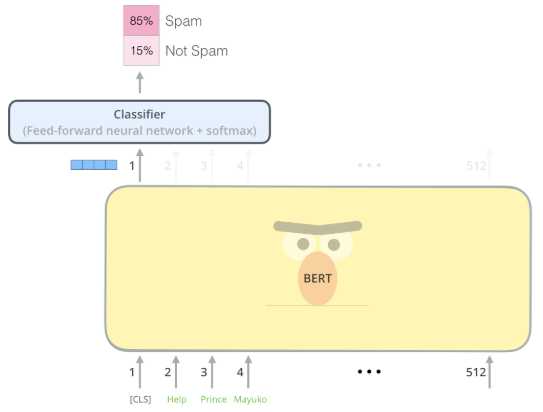
我们也可以直接把这个向量输入一个分类器中,判断文本的类别,比如下面判断垃圾邮件的实例
ERNIE 是 Enhance Representation through Knowledge Integration 的缩写
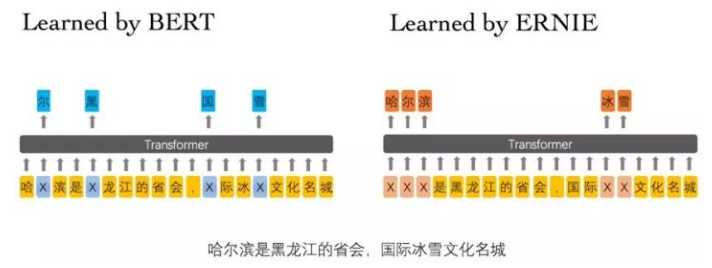
ERNIE是专门为中文准备的,BERT的输入以中文的字为单位,随机盖掉一些字后其实是很容易被猜出来的,如上图所示。所以盖掉一个词汇比较合适。
GPT 是 Generative Pre-Training 的缩写,它的参数量特别大,如下图所示,它的参数量是 BERT 的4.5倍左右
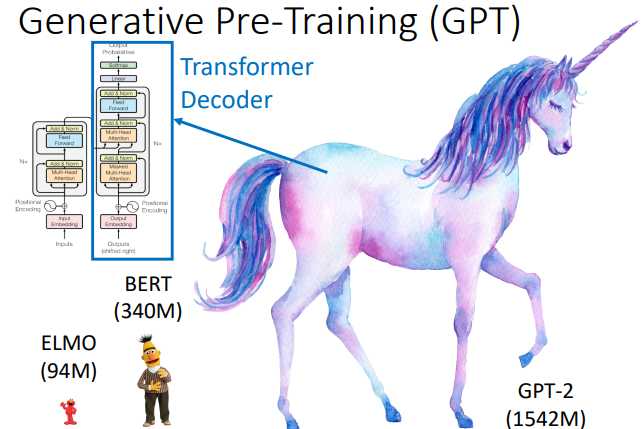
BERT 是 Transformer 的 Encoder,GPT则是 Transformer 的 Decoder。GPT 输入一些词汇,预测接下来的词汇。其计算过程如下图所示。
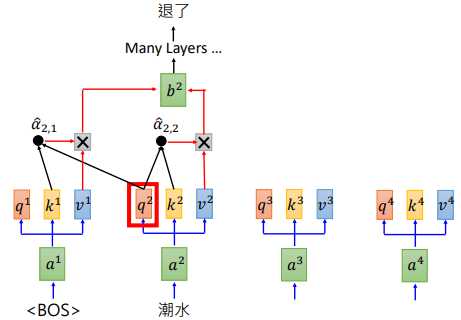
我们输入单词 “潮水”,经过许多层的 self-attention 后得到输出 “退了”。再把 “退了” 作为输入,预测下一个输出。
GPT可以做阅读理解、句子或段落生成和翻译等NLP任务
参考资料:
http://jalammar.github.io/illustrated-bert/
李宏毅深度学习
标签:mamicode ext 向量 ted zed ase http 阅读 encode
原文地址:https://www.cnblogs.com/dogecheng/p/11615750.html