标签:executor tail back node detail 它的 sql 联系 资源管理器
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark有如下优势:
目标:
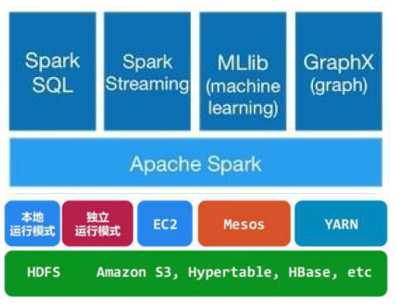
架构及生态:
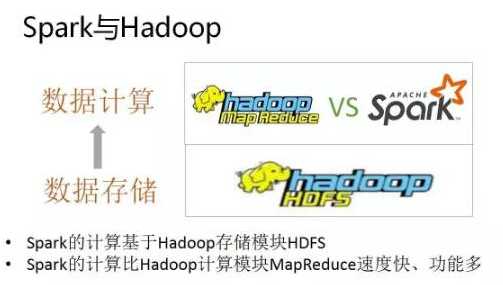
Spark与hadoop:
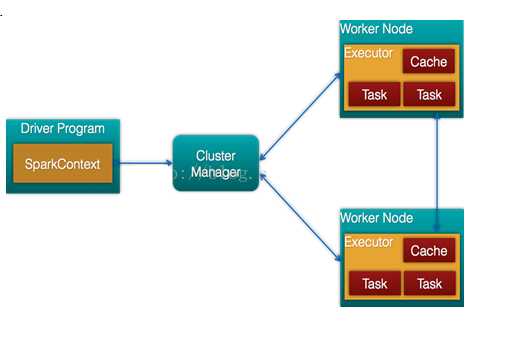
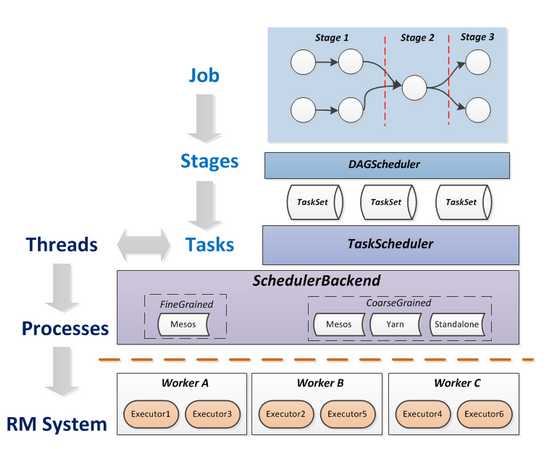
运行流程及特点:
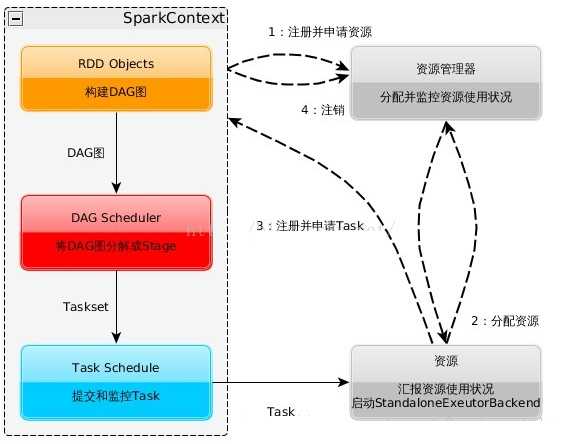
Spark运行特点:
常用术语:
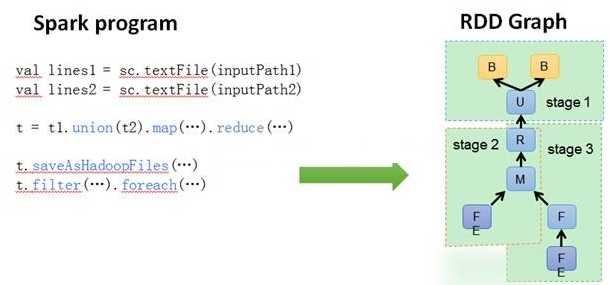
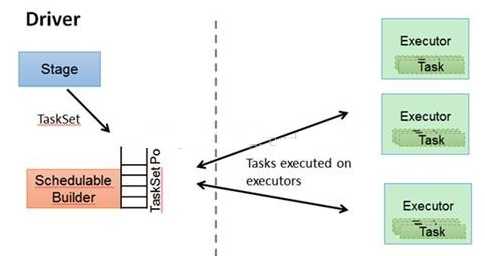
Spark运行模式:
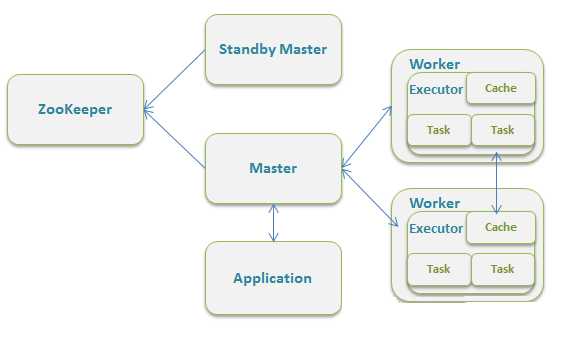
standalone: 独立集群运行模式
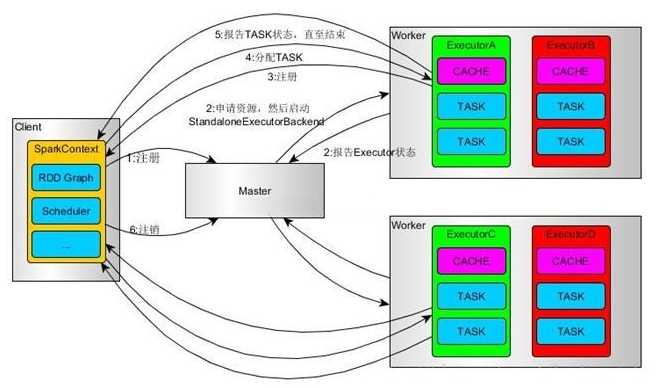
yarn: (参考:http://blog.csdn.net/gamer_gyt/article/details/51833681)
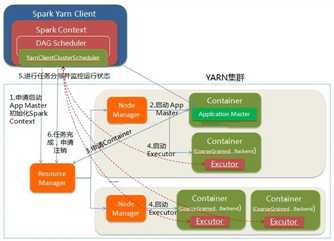
Spark Cluster模式:
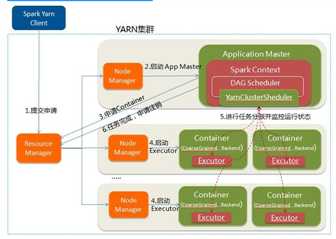
Spark Client 和 Spark Cluster的区别:
思考: 我们在使用Spark提交job时使用的哪种模式?
RDD运行流程:
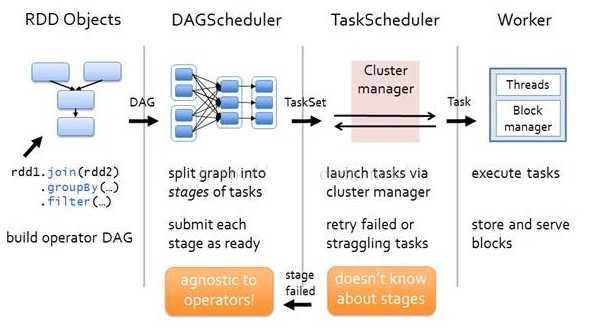
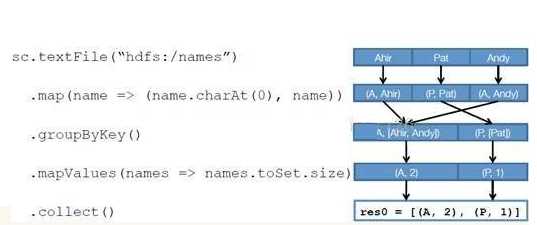
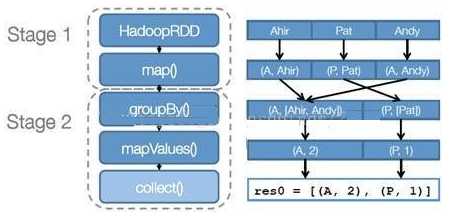
转载自:https://www.cnblogs.com/tgzhu/p/5818374.html
标签:executor tail back node detail 它的 sql 联系 资源管理器
原文地址:https://www.cnblogs.com/momoyan/p/11616497.html