在上一篇文章中,我们了解了词向量的相关内容。对于英文语料来说,直接根据空格或者标点即可对词记性划分。而对于中文语料,分词的方法就十分复杂了。之前在概述里提到过,在中文自然语言处理领域,不同的分词方法将使得同一个句子有不同的含义,如:
“乒乓球拍/卖了” 和 “乒乓球/拍卖/了”
“南京市/长江/大桥” 和 “南京/市长/江大桥”
笔者认为,分词算法主要有以下几个问题:
首先,我们需要知道,在做自然语言处理的时候,为什么需要分词?什么时候需要分词?更深入一点的问题就是,对于深度学习这样一个端到端的模型,为什么不直接将最基础“字”输入模型,而要分词之后再输入模型呢?
一方面,从直觉上来看,对于词,我们的做法是用一个向量将其在高维空间中进行表征,相当每一个语义有一个固定的表示,我们可以用其来计算他们之间的距离,或是余弦相似度,从而表示词与词之间的相似度。而对于单个汉字来说,通常是没有十分明确的语义的,这使得用向量来表征单个字是十分困难的。
另一方面,大部分的机器学习算法都有一个假设:特征之间是相互独立的。显然,在字与字之间,这个假设是很难成立的,如
“自/然/语/言/处/理”
每个字之间是有比较强的相关性的,而经过分词之后,如
“自然/语言/处理”
“自然语言/处理”
显然,词与词之间的相关性明显就弱得多了,这使得特征更接近我们的假设。
但今年来越来越多的研究表明,分词并不是什么时候效果都比单字的效果要好,某些情况下单字模型反而能够得到更好的模型表现。这主要有以下几个原因:
那么分词到底是否是有必要的呢?笔者认为这需要根据不同的任务来说。如果在下游任务数据量足够大的情况下,通常直接将单字输入模型,这样模型参数空间较小,不容易过拟合,易于训练。但是对于大部分场景来说,语料通常较少,这种情况下,我们可以在通用语料中训练合适的词向量,再在新任务中固定词向量来训练,提升将是非常大的。
分词的主要方法有两种:
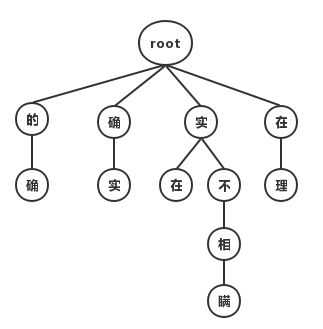
对于查表法,第一步都是根据给定的词表,将一句话中所有可能的词都匹配出来,将其构成一个有向无环图(DAG),在没有先验知识的前提下,每条边的权重都是1。这样,我们分词的过程其实就成为了一个求DAG最短路径的过程。对于匹配词表,如果匹配每一个字时都遍历整个词表,是十分耗时的。通常的做法是构造一个前缀树(Trie),Trie树由词的公共前缀构成节点,大大降低了存储空间,同时提升了查找效率,对于上述例句构造的Trie树如下图所示,详细的算法原理大家可以自行百度。
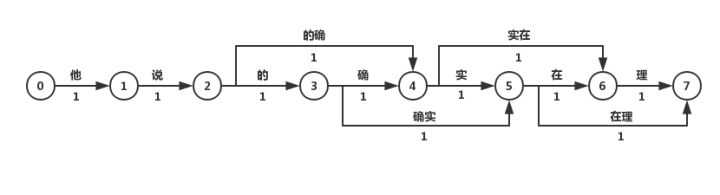
最长匹配算法是一种贪心算法,包括正向/反向最大匹配算法,指从左到右/从右到左匹配句子中字,直到匹配到最长的词语为止。这种分词方法是最简单的,虽然其速度快,但是精度不高。比如之前给的例子,正向最长匹配算法的分词结果就是“他/说/的/的确/实在/理”。
Dijkstra算法是较为常用的最短路径方法,其算法原理在于以起始点为中心向外层层拓展(广度优先搜索思想),直到拓展到终点为止。N-最短路径算法每次均保留N条最短路径,最后求得最优解时回溯得到最短路径。如上面的例子,可以分为如下的步骤:
则可能的分词结果为“他/说/的确/实在/理”和“他/说/的/确实/在理”,可见效果还是优于最大匹配算法的。
由于实际的语料中,不同字之间的转移概率并不是相同的,因此,我们可以通过构建统计语言模型来构建新的有向无环图。对于统计语言模型还不了解的同学可以回去看我上一篇博客。根据我们的条件概率公式。
\[P(S)=P(w_1, w_2, ..., w_T)=\prod_{t=1}^Tp(w_t|w_1, w_2, ..., w_{t-1})\]
我们用简单的bigram模型对上面的问题进行简单的建模,可以得到如下的DAG:
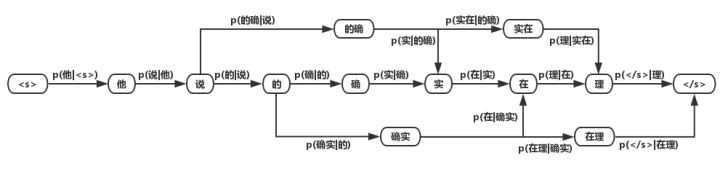
每一条边的条件概率需要从额外的语料库中进行统计得到。这样一来,对新的DAG求最短路径,即可得到分词结果。
关于序列标注法,其实属于解决一类大问题的通用思想,其用于解决一系列对字符进行分类的问题。这一部分将在下一节进行统一介绍。
参考链接
https://zhuanlan.zhihu.com/p/65865071
https://kexue.fm/archives/3863
https://www.zhihu.com/question/42022652/answer/564538459
https://zhuanlan.zhihu.com/p/66155616
https://zhuanlan.zhihu.com/p/50444885
原文地址:https://www.cnblogs.com/sandwichnlp/p/11612503.html