标签:clu over 如何 RoCE php flow com learning minus
https://blog.csdn.net/qq_41552508/article/details/100556943附上学习连接
以防万一还是搬出来吧
一、适用问题
莫队算法是一种离线算法,用分块去优化暴力,不包含修改的话,复杂度为 O(nn−−√+mn−−√) O(n\sqrt n+m\sqrt n)O(n
n
?
+m
n
?
),n nn 为序列长度,m mm 为操作总数。
二、算法实现
莫队本质上就是用分块去优化暴力的离线算法,将总复杂度降到 O(nn−−√) O(n\sqrt n)O(n
n
?
) 的位置。说白了,就是分块+暴力。
我们先讲暴力的部分。比如一个长度为 n nn 的序列,m mm 次查询,每次查询询问区间 [l,r] [l,r][l,r] 之间的众数。对于这个问题,暴力求的话就是直接用桶记录每个数出现的次数,然后遍历区间 [l,r] [l,r][l,r],直接统计答案即可。这个暴力过程和莫队暴力过程没有任何区别,然后问题就变成了如何用分块来优化这个暴力呢?
在分块的部分,该算法将整个序列按照 n−−√ \sqrt n
n
?
大小进行分块,共分成 n−−√ \sqrt n
n
?
块,然后对于所有的询问,先按照左端点所在的块编号进行排序,如果块编号相同,再按照右端点排序。询问排序完之后,就直接暴力求解即可。代码的话看一下下面习题就可以掌握了。
最后就是时间复杂度的问题了。如何证明这个算法的时间复杂度呢?我们对每一个块分开进行考虑,假设有 bi b_ib
i
?
次操作在第 i ii 个块中,则在这个块中,右端点一定递增,因此右端点最多移动 n nn 次,而左端点每次最多移动 n−−√ \sqrt n
n
?
,一共最多移动 bi∗n−−√ b_i*\sqrt nb
i
?
∗
n
?
次,每次端点移动的时间复杂度为 O(1) O(1)O(1),因此移动的总次数为 ∑n√i=1(bi∗n−−√+n)=m∗n−−√+n∗n−−√ \sum\limits_{i=1}^{\sqrt n}(b_i*\sqrt n+n)=m*\sqrt n+n*\sqrt n
i=1
∑
n
?
?
(b
i
?
∗
n
?
+n)=m∗
n
?
+n∗
n
?
,因此总复杂度为 O(nn−−√+mn−−√) O(n\sqrt n+m\sqrt n)O(n
n
?
+m
n
?
)。
三、普通莫队习题
1. [2009国家集训队] 小Z的袜子
题意: n nn 双颜色不同袜子,m mm 次询问,每次询问给出 [L,R] [L,R][L,R] 区间,询问在 [L,R] [L,R][L,R] 区间中随机抽出两双颜色相同的袜子的概率,输出最简分数形式 (A/B) (A/B)(A/B)。
?我们所记录的是x双同色袜子的组合方案数所以我们除以他的区间内袜子的c(n,2)就是答案了
分析到这里,就可以发现这是一道普通莫队的裸题,我们添加与删除时只需加上或减去当前与该点颜色相同的袜子数,这样同时可以避免重复计算。
代码:
#include <bits/stdc++.h>
#define rep(i,a,b) for(int i = a; i <= b; i++)
typedef long long ll;
const int N = 2*1e5+100;
using namespace std;
int a[N],pos[N],n,m,L,R;
ll ans[N][2],flag[N],Ans;
struct Node{
int l,r,id;
bool operator < (Node xx) const{
if(pos[l] == pos[xx.l]) return r < xx.r;
else return pos[l] < pos[xx.l];
}
}Q[N];
ll gcd(ll a,ll b) {return b == 0 ? a:gcd(b,a%b);}
void add(int x){
Ans += flag[a[x]];
flag[a[x]]++;
}
void del(int x){
flag[a[x]]--;
Ans -= flag[a[x]];
}
int main()
{
L = 1, R = 0;
scanf("%d%d",&n,&m);
int sz = sqrt(n);
rep(i,1,n){
scanf("%d",&a[i]);
pos[i] = i/sz;
}
rep(i,1,m){
scanf("%d%d",&Q[i].l,&Q[i].r);
Q[i].id = i;
}
sort(Q+1,Q+1+m);
rep(i,1,m){
while(L < Q[i].l) del(L),L++;
while(L > Q[i].l) L--, add(L);
while(R < Q[i].r) R++, add(R);
while(R > Q[i].r) del(R), R--;
ll len = Q[i].r-Q[i].l+1;
ll tp = len*(len-1ll)/(ll)2;
ll g = gcd(Ans,tp);
ans[Q[i].id][0] = Ans/g;
ans[Q[i].id][1] = tp/g;
}
rep(i,1,m) printf("%lld/%lld\n",ans[i][0],ans[i][1]);
return 0;
}
2. 花神的嘲讽计划Ⅰ
题意: 初始序列长度为 n nn,m mm 组询问,每次询问给出一个 x xx、y yy,以及长度为 k kk 的连续序列。询问在区间 [x,y] [x,y][x,y] 中是否存在一段连续的长度为 k kk 的,与询问中给出的序列相同的一段序列。存在输出 No NoNo,不存在输出 Yes YesYes。(1≤n,m≤106) (1\leq n,m\leq 10^6)(1≤n,m≤10
6
)
思路: 这题可以观察到每次询问的连续序列长度都是固定为 k kk,因此不难想到用 hash hashhash 来解决这个问题。我们将每个位置后面连续的一段 k kk 哈希起来,然后每个位置就有了一个对应的 hash hashhash 值。我们将这些 hash hashhash 值离散化之后,用桶来记录区间端点移动时对答案的贡献。
代码:
#include <bits/stdc++.h>
#define rep(i,a,b) for(int i = a; i <= b; i++)
typedef long long ll;
const int N = 2*1e6+100;
const ll mod = 1e11+7;
using namespace std;
int n,m,k,L,R,flag[N],tot,ans[N],pos[N],pp[N];
ll a[N],b[N],ha[N];
struct Node{
int l,r,id;
ll w;
bool operator < (Node xx) const {
if(pos[l] != pos[xx.l]) return pos[l] < pos[xx.l];
else return r < xx.r;
}
}q[N];
int find(ll x){
return lower_bound(b+1,b+1+tot,x)-b;
}
ll Hash(int pos){
ll tp = 0;
ll base = 1;
rep(i,pos,pos+k-1){
tp = (tp+a[i]*base)%mod;
if(tp < 0) tp = (tp+mod)%mod;
base = (base*(ll)133)%mod;
if(base < 0) base = (base+mod)%mod;
}
return tp;
}
void add(int x) {flag[pp[x]]++;}
void del(int x) {flag[pp[x]]--;}
int main()
{
scanf("%d%d%d",&n,&m,&k);
rep(i,1,n) scanf("%lld",&a[i]);
rep(i,1,m){
int xx,yy; scanf("%d%d",&xx,&yy);
q[i].l = xx, q[i].r = yy, q[i].id = i;
q[i].r = q[i].r-k+1;
ll tp = 0;
ll base = 1;
rep(j,1,k){
ll hp; scanf("%lld",&hp);
tp = (tp+hp*base)%mod;
if(tp < 0) tp = (tp+mod)%mod;
base = (base*(ll)133)%mod;
if(base < 0) base = (base+mod)%mod;
}
q[i].w = tp;
b[++tot] = tp;
}
rep(i,1,n-k+1){
ll tp = Hash(i);
ha[i] = tp;
b[++tot] = tp;
}
sort(b+1,b+1+tot);
tot = unique(b+1,b+1+tot)-b-1;
rep(i,1,n-k+1){
pp[i] = find(ha[i]);
}
int sz = sqrt(n);
rep(i,1,n) pos[i] = i/sz;
sort(q+1,q+1+m);
L = 1, R = 0;
rep(i,1,m){
while(L < q[i].l) del(L), L++;
while(L > q[i].l) L--, add(L);
while(R < q[i].r) R++, add(R);
while(R > q[i].r) del(R), R--;
int pos = find(q[i].w);
if(flag[pos]) ans[q[i].id] = 1;
else ans[q[i].id] = 0;
}
rep(i,1,m){
if(ans[i]) printf("No\n");
else printf("Yes\n");
}
return 0;
}
3. XOR and Favorite Number
思路: 既然是某一区间的异或和,不难想到先求一个异或前缀和,然后对于一个 j jj 来说,就是询问区间 [l,r] 中有多少个 i i 满足 sum[i−1] ^ sum[j]=k。
问题拆解到这一步,剩下的问题就比较明了了,直接上莫队,然后用桶维护每一个数的异或前缀和即可。
代码:
#include <bits/stdc++.h>
#define rep(i,a,b) for(int i = a; i <= b; i++)
typedef long long ll;
const int N = 2*1e6+100;
using namespace std;
int a[N],pos[N],n,m,k,L,R;
ll ans[N],flag[N],Ans;
struct Node{
int l,r,id;
bool operator < (Node xx) const{
if(pos[l] == pos[xx.l]) return r < xx.r;
else return pos[l] < pos[xx.l];
}
}Q[N];
void add(int x){
Ans += flag[a[x]^k];
flag[a[x]]++;
}
void del(int x){
flag[a[x]]--;
Ans -= flag[a[x]^k];
}
int main()
{
L = 1, R = 0;
scanf("%d%d%d",&n,&m,&k);
int sz = sqrt(n);
rep(i,1,n){
scanf("%d",&a[i]);
a[i] = a[i]^a[i-1];
pos[i] = i/sz;
}
rep(i,1,m){
scanf("%d%d",&Q[i].l,&Q[i].r);
Q[i].id = i;
}
sort(Q+1,Q+1+m);
flag[0] = 1;
rep(i,1,m){
while(L<Q[i].l) del(L-1), L++;
while(L>Q[i].l) L--, add(L-1);
while(R<Q[i].r) R++, add(R);
while(R>Q[i].r) del(R), R--;
ans[Q[i].id] = Ans;
}
rep(i,1,m) printf("%lld\n",ans[i]);
return 0;
}
4.
问区间里有多少对i,j满足i<j,同时a[i]-a[j]的绝对值小于等于k;
由于 n nn 和 m mm 的范围比较小,可以考虑使用莫队分块算法,在加入和删除的地方使用树状数组统计答案即可。
代码:
#include <bits/stdc++.h>
#define mem(a,b) memset(a,b,sizeof a);
#define rep(i,a,b) for(int i = a; i <= b; i++)
#define per(i,a,b) for(int i = a; i >= b; i--)
#define __ ios::sync_with_stdio(0);cin.tie(0);cout.tie(0)
typedef long long ll;
typedef double db;
const int N = 27000+100;
const db EPS = 1e-9;
using namespace std;
void dbg() {cout << "\n";}
template<typename T, typename... A> void dbg(T a, A... x) {cout << a << ‘ ‘; dbg(x...);}
#define logs(x...) {cout << #x << " -> "; dbg(x);}
int n,m,k,a[N],b[3*N],tot,L,R,pos[N],now[N][3];
struct Node{
int l,r,id;
bool operator < (Node xx) const {
if(pos[l] == pos[xx.l]) return r < xx.r;
else return pos[l] < pos[xx.l];
}
}q[N];
ll c[3*N],ans[N],Ans;
inline int lowbit(int x) {return x&(~x+1);}
inline void update(int x,ll v) {for(;x<=tot;x+=lowbit(x)) c[x]+=v;}
inline ll ask(int x){
ll tp = 0;
while(x) tp += c[x], x -= lowbit(x);
return tp;
}
int find(int x){
return lower_bound(b+1,b+1+tot,x)-b;
}
void add(int x){
int p1 = now[x][1], p2 = now[x][2];
Ans += ask(p1)-ask(p2);
update(now[x][0],1);
}
void del(int x){
update(now[x][0],-1);
int p1 = now[x][1], p2 = now[x][2];
Ans -= ask(p1)-ask(p2);
}
int main()
{
L = 1, R = 0;
scanf("%d%d%d",&n,&m,&k);
int sz = sqrt(n);
rep(i,1,n){
scanf("%d",&a[i]);
b[++tot] = a[i]; b[++tot] = a[i]+k; b[++tot] = a[i]-k-1;
pos[i] = i/sz;
}
sort(b+1,b+1+tot);
tot = unique(b+1,b+1+tot)-b-1;
rep(i,1,n){
now[i][0] = find(a[i]);
now[i][1] = find(a[i]+k);
now[i][2] = find(a[i]-k-1);
}
rep(i,1,m){
scanf("%d%d",&q[i].l,&q[i].r);
q[i].id = i;
}
sort(q+1,q+1+m);
rep(i,1,m){
while(L < q[i].l){
del(L);
L++;
}
while(L > q[i].l){
L--;
add(L);
}
while(R < q[i].r){
R++;
add(R);
}
while(R > q[i].r){
del(R);
R--;
}
ans[q[i].id] = Ans;
}
rep(i,1,m) printf("%lld\n",ans[i]);
return 0;
}
5莫队求组合数前缀和
Harvest of Apples
求C(n,0)+C(n,1)+C(n,2)+.....+C(n,m);
设S(n,m)=C(n,0)+C(n,1)+C(n,2)+.....+C(n,m);
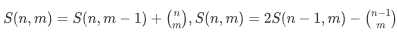
第一个式子易得,第二个式子:杨辉三角的c n,m=c(n-1,m)+c(n-1,m-1),利用这个我们来推出s(n,m)就有上面那样公式
那么就是这一行等于上一行的都用了2次,只有第最后一个用了一次
所以减去c(n-1,m)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
#include<iostream>#include<stdio.h>#include<cmath>#include<algorithm>using namespace std;const int mod=1e9+7;#define ll long longconst int maxn=1e5+7;ll jiecheng[maxn],inv[maxn];ll ans[maxn];int block;ll qsm(ll a,ll b){ ll ans=1; while(b){ if(b&1) ans=ans*a%mod; a=a*a%mod; b>>=1; } return ans;}void init(){ jiecheng[1] = 1; for(int i = 2; i < maxn; i++) jiecheng[i] = jiecheng[i-1] * i % mod; for(int i = 1; i < maxn; i++) inv[i] = qsm(jiecheng[i], mod-2);}struct node{ int l,r; int i;}modui[maxn];bool cmp(node a,node b){ if(a.l/block==b.l/block) return a.r<b.r; return a.l<b.l;}ll C(ll n,ll m){ if(m == 0 || m == n) return 1; ll ans=1; ans=(jiecheng[n]*inv[m])%mod*inv[n-m]; ans=ans%mod; return ans;}int main(){ init(); block = sqrt(maxn); int t; scanf("%d",&t); for(int i=0;i<t;i++) { scanf("%d%d",&modui[i].l,&modui[i].r); modui[i].i=i; } sort(modui,modui+t,cmp); int l=1,r=0; int sum=1; for(int i = 0; i < t; i++) { while(l < modui[i].l) sum = (2 * sum - C(l++, r) + mod) % mod; while(l > modui[i].l) sum = ((sum + C(--l, r))*inv[2]) % mod; while(r < modui[i].r) sum = (sum + C(l, ++r)) % mod; while(r > modui[i].r) sum = (sum - C(l, r--) + mod) % mod; ans[modui[i].i] = sum; } for(int i=0;i<t;i++) { printf("%lld\n",ans[i]); } return 0;} |
~~~待修改莫队
1. Machine Learning
思路: 这个问题唯一的操作难点在于 mex mexmex 函数的求取,其实我们可以像求取 SG SGSG 函数的 mex mexmex 一样,直接暴力求取即可。然后其余部分就是常规的带修改莫队的操作了。
#include <cstdio>
#include <iostream>
#include <cstring>
#include <cmath>
#include <algorithm>
#define __ ios::sync_with_stdio(0);cin.tie(0);cout.tie(0)
#define rep(i,a,b) for(int i = a; i <= b; i++)
#define LOG1(x1,x2) cout << x1 << ": " << x2 << endl;
#define LOG2(x1,x2,y1,y2) cout << x1 << ": " << x2 << " , " << y1 << ": " << y2 << endl;
#define LOG3(x1,x2,y1,y2,z1,z2) cout << x1 << ": " << x2 << " , " << y1 << ": " << y2 << " , " << z1 << ": " << z2 << endl;
typedef long long ll;
typedef double db;
const int N = 2*1e5+100;
const int M = 1e5+100;
const db EPS = 1e-9;
using namespace std;
int n,qq,a[N],b[N],tot,Qnum,Cnum,pos[N],ans[N],L,R,T,flag[N],vis[N];
struct Query{
int l,r,id,t;
bool operator < (Query xx) const {
if(pos[l] != pos[xx.l]) return pos[l] < pos[xx.l];
else if(pos[r] != pos[xx.r]) return pos[r] < pos[xx.r];
else return t < xx.t;
}
}q[M];
struct Change{
int pos,val;
}C[M];
int find(int x){
return lower_bound(b+1,b+1+tot,x)-b;
}
void add(int x){
if(flag[a[x]]!=0) vis[flag[a[x]]]--;
flag[a[x]]++; vis[flag[a[x]]]++;
}
void del(int x){
vis[flag[a[x]]]--; flag[a[x]]--;
if(flag[a[x]] != 0) vis[flag[a[x]]]++;
}
void Work(int x,int i){
if(C[x].pos >= q[i].l && C[x].pos <= q[i].r){
vis[flag[a[C[x].pos]]]--; flag[a[C[x].pos]]--;
if(flag[a[C[x].pos]] != 0) vis[flag[a[C[x].pos]]]++;
if(flag[C[x].val] != 0) vis[flag[C[x].val]]--;
flag[C[x].val]++; vis[flag[C[x].val]]++;
}
swap(a[C[x].pos],C[x].val);
}
int solve(){
rep(i,0,n)
if(!vis[i]) return i;
}
int main()
{
scanf("%d%d",&n,&qq);
rep(i,1,n){
scanf("%d",&a[i]);
b[++tot] = a[i];
}
rep(i,1,qq){
int op,l,r; scanf("%d%d%d",&op,&l,&r);
if(op == 1) Qnum++, q[Qnum] = {l,r,Qnum,Cnum};
else C[++Cnum] = {l,r}, b[++tot] = r;
}
sort(b+1,b+1+tot);
tot = unique(b+1,b+1+tot)-b-1;
int sz = pow(n,0.66666666666666);
rep(i,1,n) pos[i] = i/sz;
sort(q+1,q+1+Qnum);
L = 1, R = 0, T = 0;
vis[0] = 1;
rep(i,1,n) a[i] = find(a[i]);
rep(i,1,Cnum) C[i].val = find(C[i].val);
rep(i,1,Qnum){
while(L < q[i].l) del(L++);
while(L > q[i].l) add(--L);
while(R < q[i].r) add(++R);
while(R > q[i].r) del(R--);
while(T < q[i].t) Work(++T,i);
while(T > q[i].t) Work(T--,i);
ans[q[i].id] = solve();
}
rep(i,1,Qnum) printf("%d\n",ans[i]);
return 0;
}
#include <bits/stdc++.h>#define rep(i,a,b) for(int i = a; i <= b; i++)typedef long long ll;const int N = 2*1e5+100;using namespace std;
int a[N],pos[N],n,m,L,R;ll ans[N][2],flag[N],Ans;struct Node{int l,r,id;bool operator < (Node xx) const{if(pos[l] == pos[xx.l]) return r < xx.r;else return pos[l] < pos[xx.l];}}Q[N];
ll gcd(ll a,ll b) {return b == 0 ? a:gcd(b,a%b);}
void add(int x){Ans += flag[a[x]];flag[a[x]]++;}
void del(int x){flag[a[x]]--;Ans -= flag[a[x]];}
int main(){L = 1, R = 0;scanf("%d%d",&n,&m);int sz = sqrt(n);rep(i,1,n){scanf("%d",&a[i]);pos[i] = i/sz;}rep(i,1,m){scanf("%d%d",&Q[i].l,&Q[i].r);Q[i].id = i;}sort(Q+1,Q+1+m);rep(i,1,m){while(L < Q[i].l) del(L),L++;
while(L > Q[i].l) L--, add(L);while(R < Q[i].r) R++, add(R);while(R > Q[i].r) del(R), R--;
ll len = Q[i].r-Q[i].l+1;ll tp = len*(len-1ll)/(ll)2;ll g = gcd(Ans,tp);ans[Q[i].id][0] = Ans/g;ans[Q[i].id][1] = tp/g;}rep(i,1,m) printf("%lld/%lld\n",ans[i][0],ans[i][1]);return 0;}————————————————版权声明:本文为CSDN博主「Gene_INNOCENT」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/qq_41552508/article/details/100556943
标签:clu over 如何 RoCE php flow com learning minus
原文地址:https://www.cnblogs.com/hgangang/p/11618835.html