标签:数据包 定义 linux中 last 标准 derby 执行器 结果 als
Hive:由Facebook开源,用于解决海量(结构化日志)的数据统计。
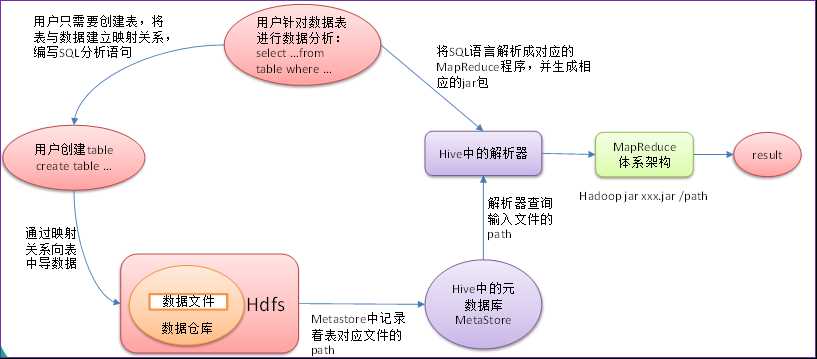
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是:将Hive SQL转化成MapReduce程序
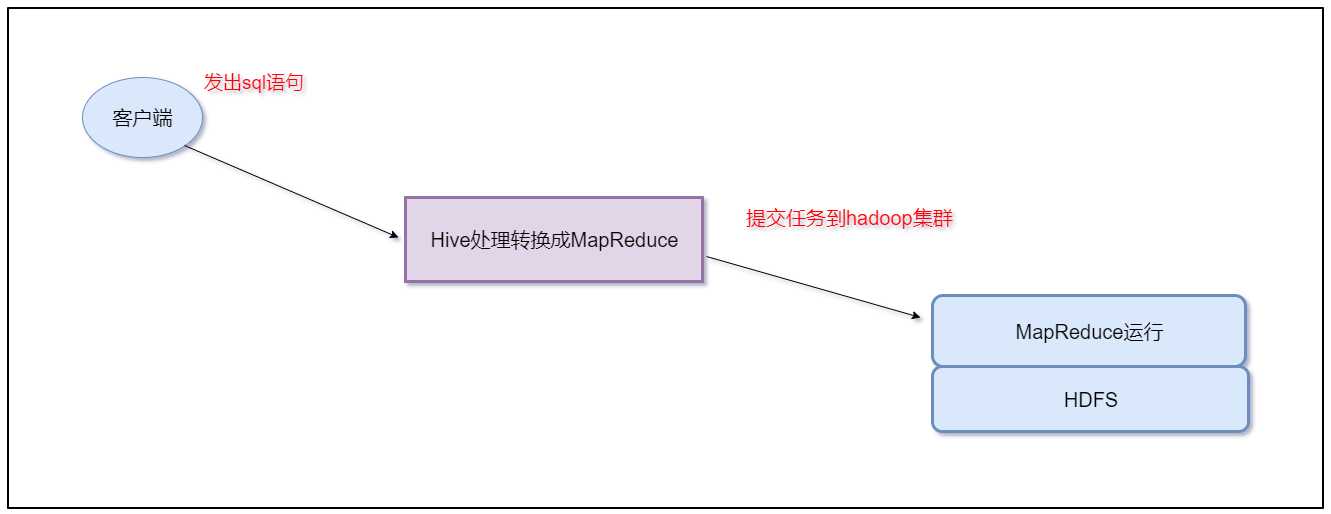
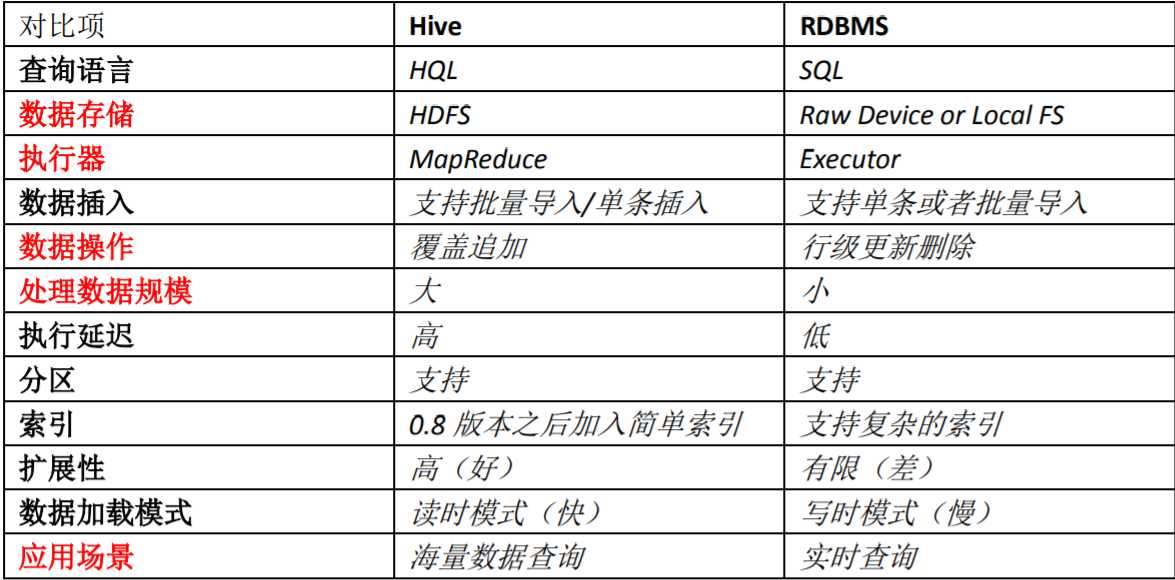

Hive 具有 SQL 数据库的外表,但应用场景完全不同。
Hive 只适合用来做海量离线数据统计分析,也就是数据仓库。
优点
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
避免了去写MapReduce,减少开发人员的学习成本。
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点
Hive 不支持记录级别的增删改操作
Hive 的查询延时很严重
Hive 不支持事务
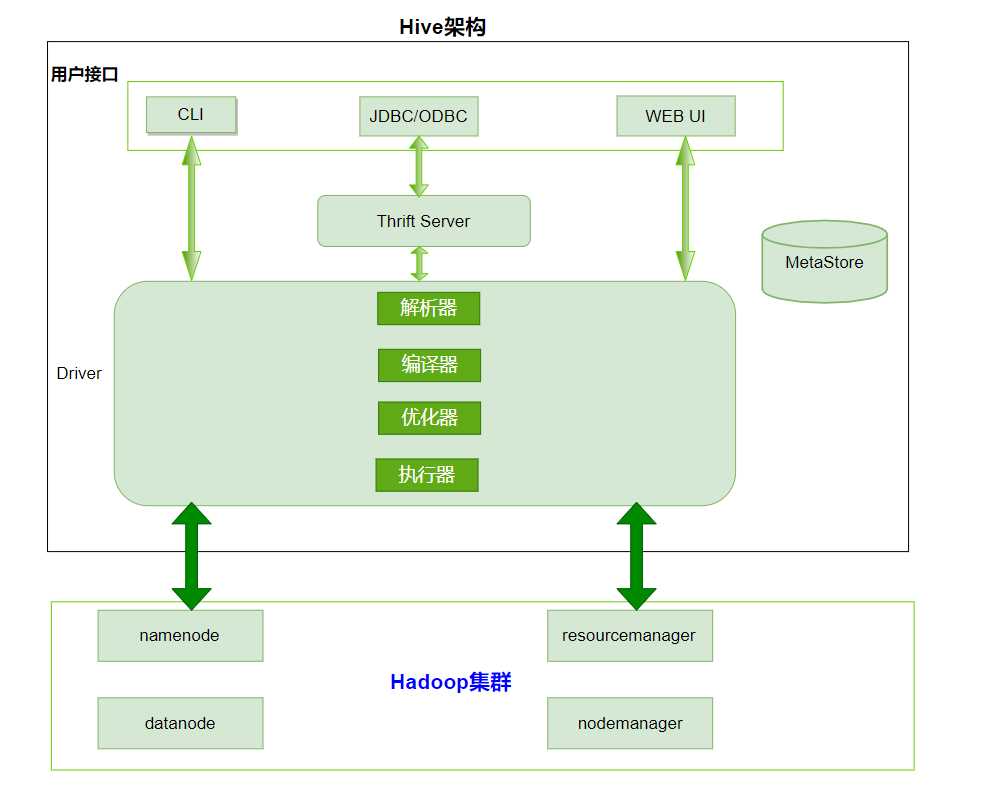

1、用户接口:Client
CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
2、元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,==推荐使用MySQL存储Metastore==
3、Hadoop集群
使用HDFS进行存储,使用MapReduce进行计算。
4、Driver:驱动器
解析器(SQL Parser)
将SQL字符串转换成抽象语法树AST
对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
编译器(Physical Plan):将AST编译生成逻辑执行计划。
优化器(Query Optimizer):对逻辑执行计划进行优化。
执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说默认就是mapreduce任务
? 注意hive就是一个构建数据仓库的工具,只需要在一台服务器上安装就可以了,不需要在多台服务器上安装。
1、提前先安装好mysql服务和hadoop集群
2、下载hive的安装包
http://mirror.bit.edu.cn/apache/hive/hive-1.2.2/apache-hive-1.2.2-bin.tar.gz
apache-hive-1.2.2-bin.tar.gz
3、规划安装目录
/opt/bigdata
4、上传安装包到服务器中
5、解压安装包到指定的规划目录
tar -zxvf apache-hive-1.2.2-bin.tar.gz -C /opt/bigdata
6、重命名解压目录
mv apache-hive-1.2.2-bin hive
7、修改配置文件
进入到Hive的安装目录下的conf文件夹中
vim hive-env.sh(mv hive-env.sh.template hive-env.sh)
#配置HADOOP_HOME路径
export HADOOP_HOME=/opt/bigdata/hadoop
#配置HIVE_CONF_DIR路径
export HIVE_CONF_DIR=/opt/bigdata/hive/conf
vim hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> <description>password to use against metastore database</description> </property> </configuration>
需要将mysql的驱动包上传到hive的lib目录下
例如 mysql-connector-java-5.1.38.jar
先启动hadoop集群和mysql服务
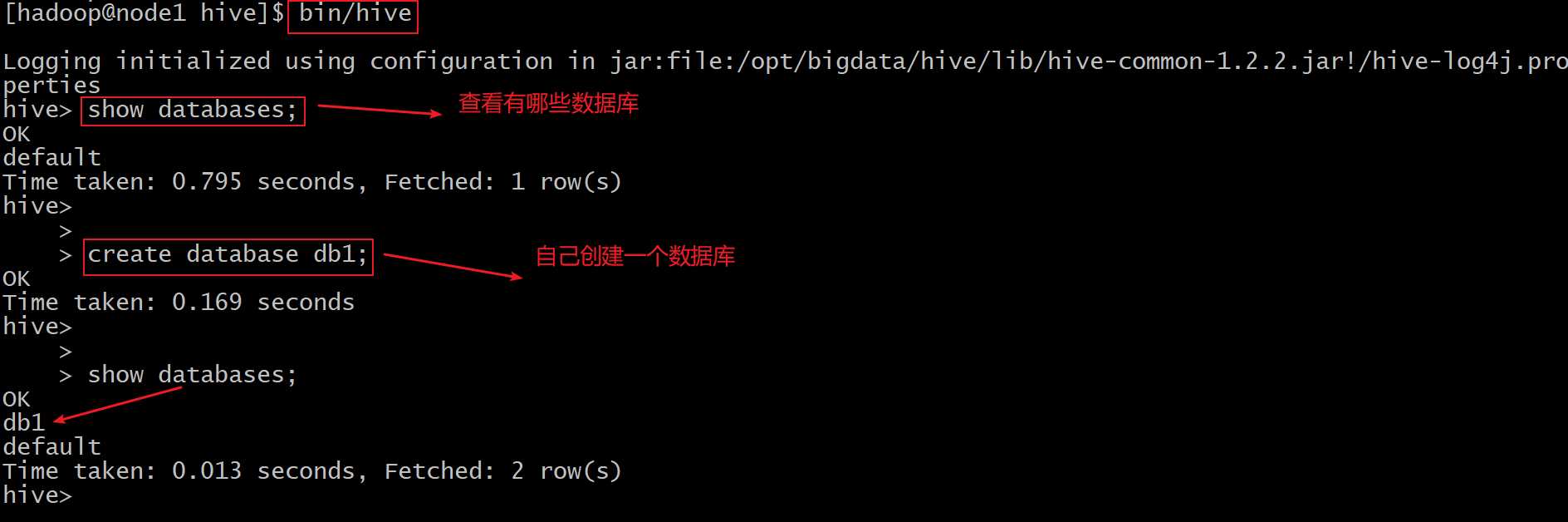
cd /opt/bigdata/hive
bin/hive

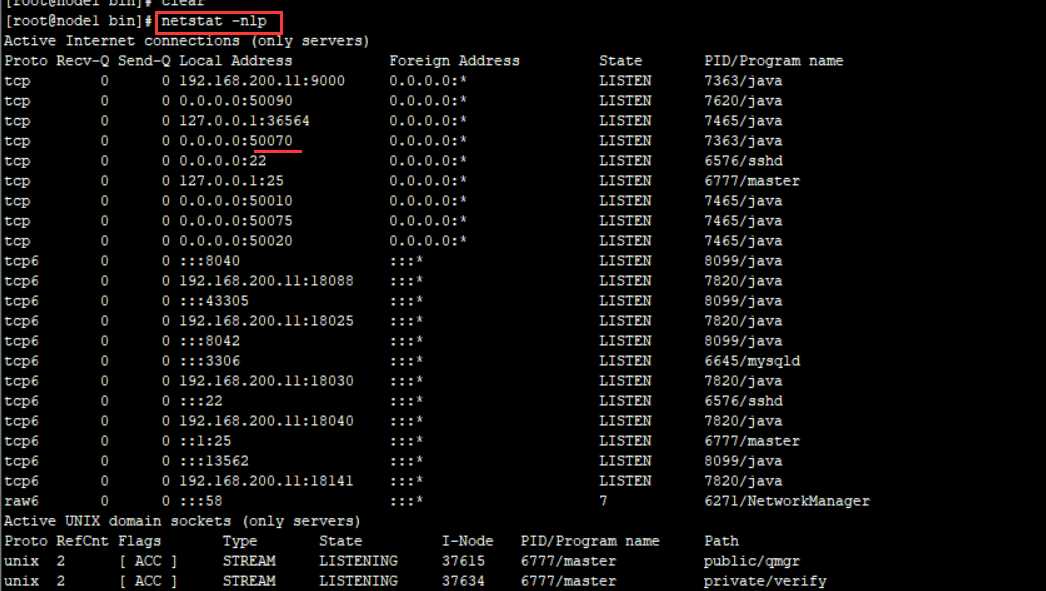
如何查询后台线程?
netstat -nlp

启动hiveserver2服务
前台启动
弊端:控制台一直打印日志,且不能关掉控制台,关掉即服务挂掉。

bin/hive --service hiveserver2

后台启动
特点:控制台可以关闭,且在进程中运行,执行jps,可以看到hive的进程。

nohup bin/hive --service hiveserver2 &

beeline连接hiveserver2
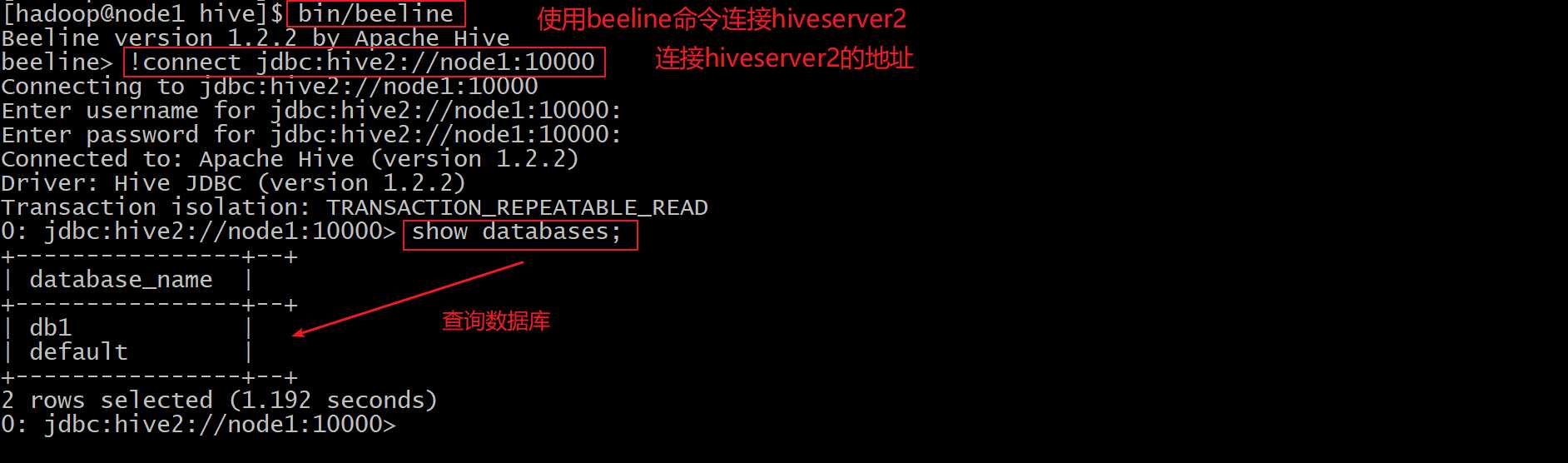
bin/beeline
beeline> !connect jdbc:hive2://node1:10000

hive -e sql语句
使用 –e 参数来直接执行hql的语句
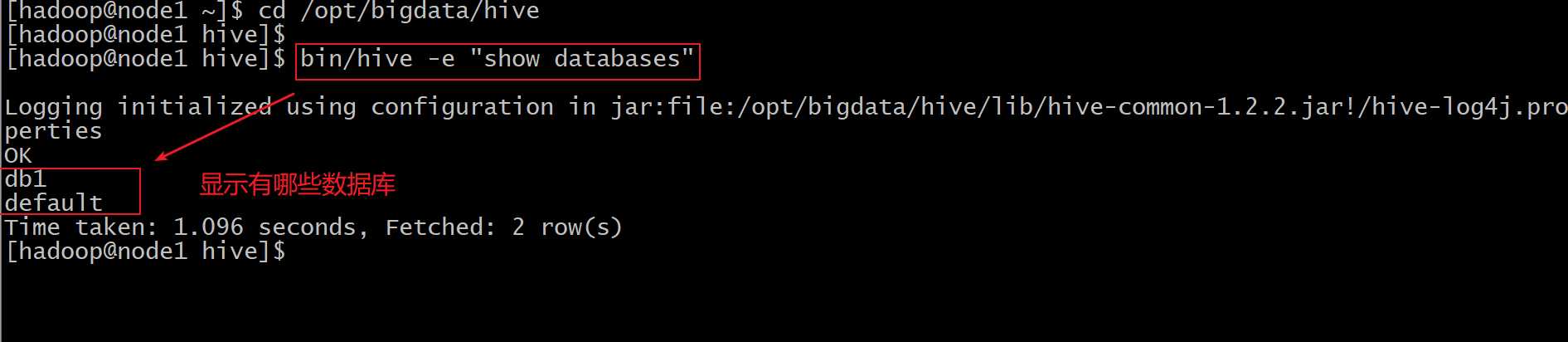
cd /opt/bigdata/hive
bin/hive -e "show databases"

hive -f sql文件
使用 –f 参数执行包含hql语句的文件


| 类型名称 | 描述 | 举例 |
|---|---|---|
| boolean | true/false | true |
| tinyint | 1字节的有符号整数 | 1 |
| smallint | 2字节的有符号整数 | 1 |
| ==int== | 4字节的有符号整数 | 1 |
| ==bigint== | 8字节的有符号整数 | 1 |
| float | 4字节单精度浮点数 | 1.0 |
| ==double== | 8字节单精度浮点数 | 1.0 |
| ==string== | 字符串(不设长度) | “abc” |
| varchar | 字符串(1-65355长度,超长截断) | “abc” |
| timestamp | 时间戳 | 1563157873 |
| date | 日期 | 20190715 |
| 类型名称 | 描述 | 举例 |
|---|---|---|
| array | 一组有序的字段,字段类型必须相同 array(元素1,元素2) | Array(1,2,3) |
| map | 一组无序的键值对 map(k1,v1,k2,v2) | Map(‘a’,1,‘b‘,2) |
| struct | 一组命名的字段,字段类型可以不同 struct(元素1,元素2) | Struct(‘a‘,1,2,0) |
array字段的元素访问方式:
下标获取元素,下标从0开始
获取第一个元素
array[0]
map字段的元素访问方式
通过键获取值
获取a这个key对应的value
map[‘a‘]
struct字段的元素获取方式
定义一个字段c的类型为struct{a int;b string}
获取a和b的值
使用c.a 和c.b 获取其中的元素值
这里可以把这种类型看成是一个对象
create table complex( col1 array<int>, col2 map<string,int>, col3 struct<a:string,b:int,c:double> )
系统自动实现类型转换,不需要用户干预
如tinyint可以转换成int,int可以转换成bigint。
所有整数类型、float 和 string类型都可以隐式地转换成double。
tinyint、smallint、int都可以转换为float。
boolean类型不可以转换为任何其它的类型。
可以使用cast函数操作显示进行数据类型转换
cast (‘1‘ as int)将把字符串‘1‘ 转换成整数1;
如果强制类型转换失败,如执行cast(‘x‘ as int),表达式返回空值 NULL。
hive > create database db_hive; 或者 hive > create database if not exists db_hive;
数据库在HDFS上的默认存储路径是/user/hive/warehouse/*.db

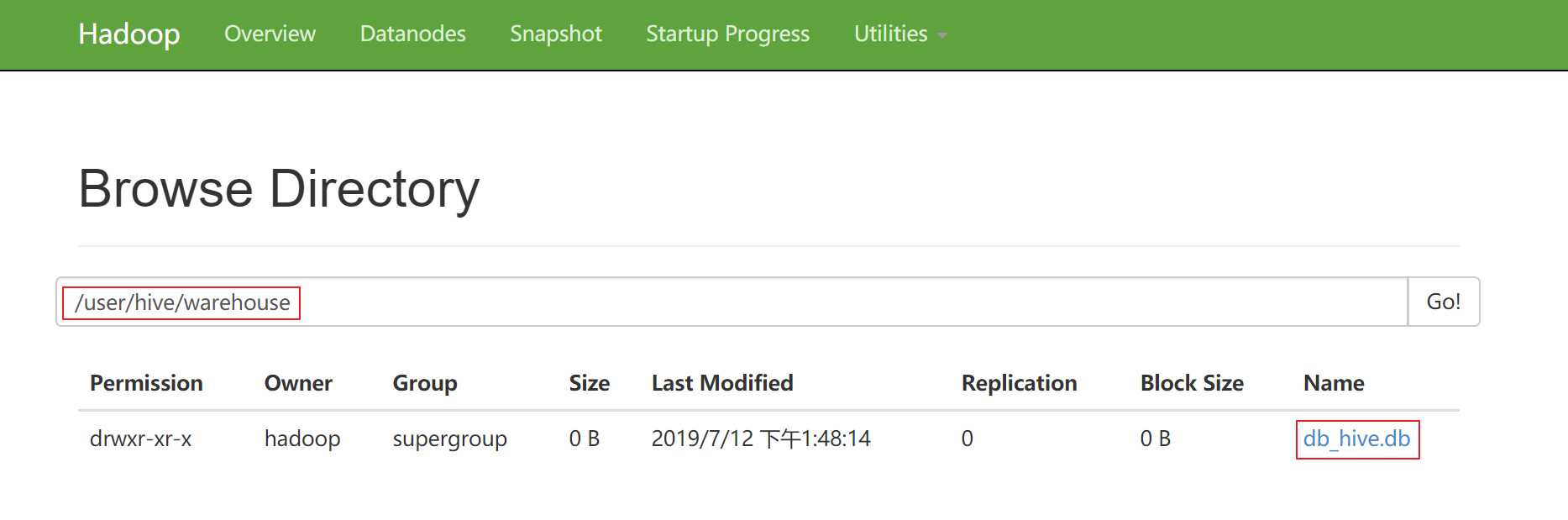
hive> show databases;
hive> show databases like ‘db_hive*‘;
hive> desc database db_hive;
hive> desc database extended db_hive;
hive > use db_hive;
#删除为空的数据库 hive> drop database db_hive; #如果删除的数据库不存在,最好采用if exists 判断数据库是否存在 hive> drop database if exists db_hive; #如果数据库中有表存在,这里需要使用cascade强制删除数据库 hive> drop database if exists db_hive cascade;
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] 分区 [CLUSTERED BY (col_name, col_name, ...) 分桶 [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] row format delimited fields terminated by “分隔符” [STORED AS file_format] [LOCATION hdfs_path]
create table
创建一个指定名字的表
EXTERNAL
创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),指定表的数据保存在哪里
COMMENT
为表和列添加注释
PARTITIONED BY
创建分区表
CLUSTERED BY
创建分桶表
SORTED BY
按照字段排序(一般不常用)
ROW FORMAT
指定每一行中字段的分隔符
row format delimited fields terminated by ‘\t’
STORED AS
指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本,默认方式)、RCFILE(列式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
LOCATION
指定表在HDFS上的存储位置。
1、直接建表
使用标准的建表语句
create table if not exists student( id int, name string ) row format delimited fields terminated by ‘\t‘ stored as textfile;
2、查询建表法
通过AS 查询语句完成建表:将子查询的结果存在新表里,有数据
create table if not exists student1 as select id, name from student;
3、like建表法
根据已经存在的表结构创建表
create table if not exists student2 like student;
4、查询表的类型
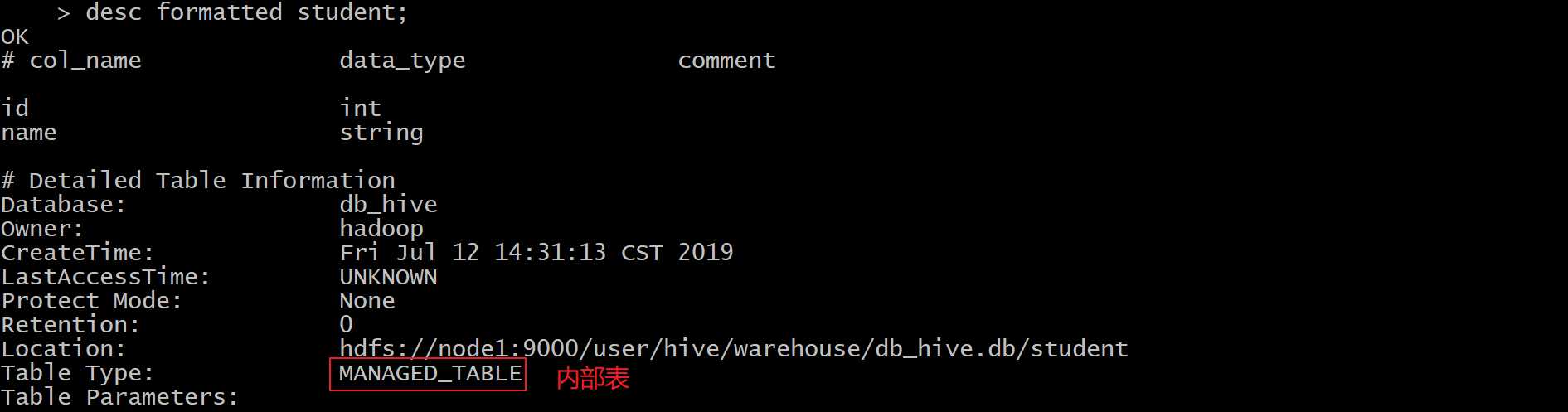
hive > desc formatted student;

加载数据:
load data local inpath 本地路径 into table 表名;
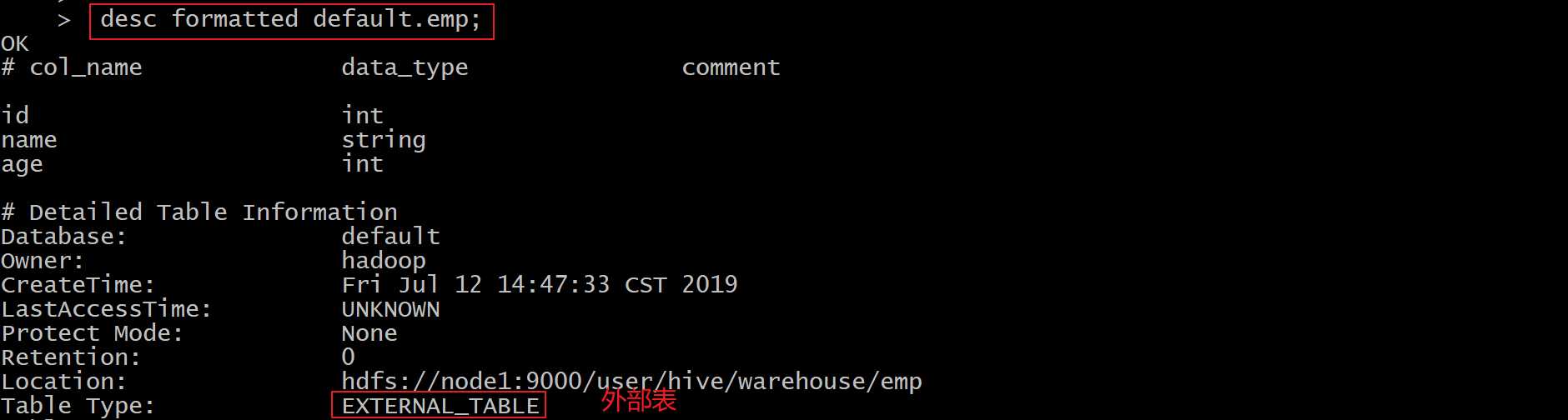
create external table if not exists emp( id int, name string, age int ) row format delimited fields terminated by ‘\t‘ location ‘/hive/bigdata‘;
创建外部表的时候需要加上external关键字
location字段可以指定,也可以不指定
指定就是数据存放的具体目录
不指定就是使用默认目录 /user/hive/warehouse

1、内部表转换为外部表
#把student内部表改为外部表 alter table student set tblproperties(‘EXTERNAL‘=‘TRUE‘);
2、外部表转换为内部表
#把student管理表改为外部表 alter table student set tblproperties(‘EXTERNAL‘=‘FALSE‘);
1、建表语法的区别
外部表在创建的时候需要加上external关键字
2、删除表之后的区别
内部表删除后,表的元数据和真实数据都被删除了
外部表删除后,仅仅只是把该表的元数据删除了,真实数据还在,后期还是可以恢复出来(这里指定了,location ‘/hive/bigdata‘,文件存在linux中)
注意:外部表可以用于重要业务,以防表被误删,导致数据丢失。
hive cli命令窗口查看本地文件系统
与操作本地文件系统类似,这里需要使用 ! (感叹号),并且最后需要加上 ;(分号)
例如
!ls /;
hive cli命令窗口查看HDFS文件系统
与查看HDFS文件系统类似
dfs -ls / ;
hive的底层执行引擎有3种
mapreduce(默认)
tez(支持DAG作业的计算框架)
spark(基于内存的分布式计算框架)
标签:数据包 定义 linux中 last 标准 derby 执行器 结果 als
原文地址:https://www.cnblogs.com/lojun/p/11375537.html