标签:训练 均值 image 空间 初始化 博客 gbdt 不同的 nbsp
MART概念,即 GBDT:
决策树 cart 的回归应用(连续值,区别于分类),以及拟合负梯度(实际上就是残差)的组合
第t轮的第i个样本的损失函数的负梯度为:
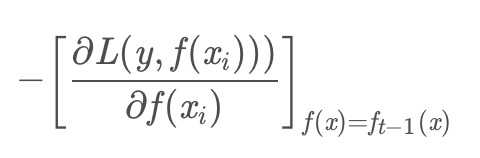
选用不同的损失函数会得到不同的负梯度,GBDT求解过程中使用平方损失作为损失函数:
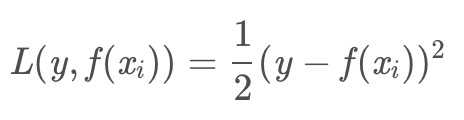
求解得到负梯度:
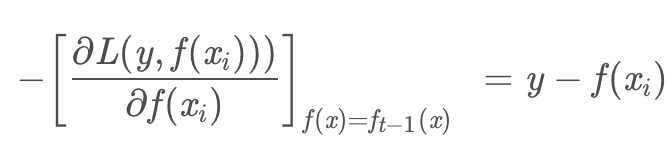
可以发现,负梯度其实就是残差,回归问题就是拟合残差。
1. 初始化弱学习器:初始 label 求平均值
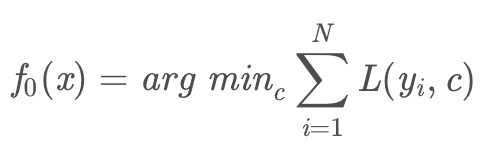
2. 对m=1,2,...,M(M棵树),进行如下步骤:
(a). 对于每个样本 1...N,计算残差(真实值与上一轮学习器的差值):
![]()
(b). 将上步得到的残差作为样本新的真实值,和对应的特征值一起作为训练数据,按照节点的最小化方差和规则使用特征进行分裂得到一颗回归树
(c). 得到回归树后求取每个叶子节点的拟合值:对叶子区域j=1,2,..J计算最佳拟合值(J:叶子节点个数)
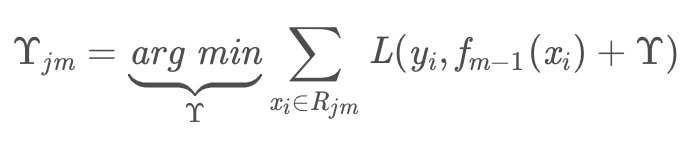
理解该过程非常重要:实际上是对每个叶子节点区域的 label 分别求平均值(每个叶子区域可能存在多个样本,每个样本的 label:![]() ;只有一个样本数据时则等于自己的 label)
;只有一个样本数据时则等于自己的 label)
(d). 更新强学习器:上一棵树得到的学习器 + lr * 对应区域残差拟合值 (每个样本对应不同的区域,对应不同的学习器)
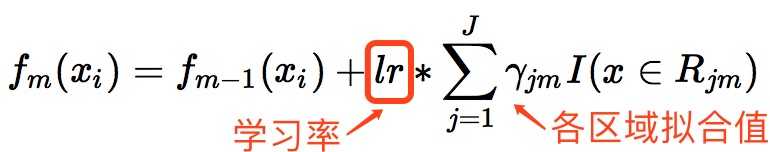
3. 得到最终的学习器:预测样本每棵树中所属叶子区域拟合值之和 gamma,预测样本最终预测值:初始学习器 + learn_rate * gamma
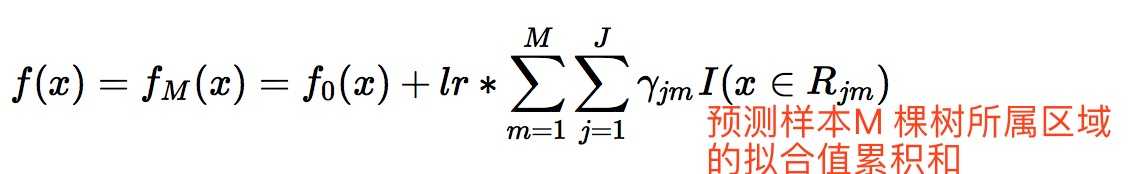
https://www.douban.com/note/670632222/
详细博客:https://blog.csdn.net/zpalyq110/article/details/79527653
标签:训练 均值 image 空间 初始化 博客 gbdt 不同的 nbsp
原文地址:https://www.cnblogs.com/fqr52/p/11614131.html