标签:初始 多个 最大 strong 趋势分析 isp 统一 维度 targe
对于数据挖掘,数据准备阶段主要就是进行特征工程。
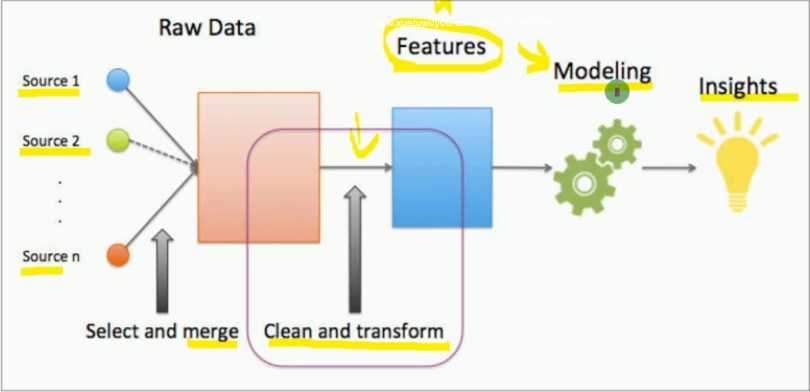
数据和特征决定了模型预测的上限,而算法只是逼近了这个上限。
好的特征要少而精,这会使模型更简单、更精准。
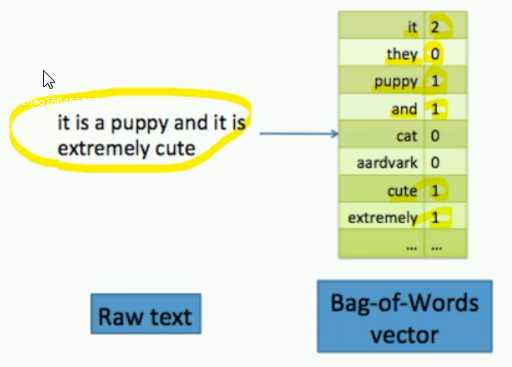
文本数据的特征提取
词袋向量的方式:统计频率
图像数据的特征提取
像素点RGB

用户行为特征提取
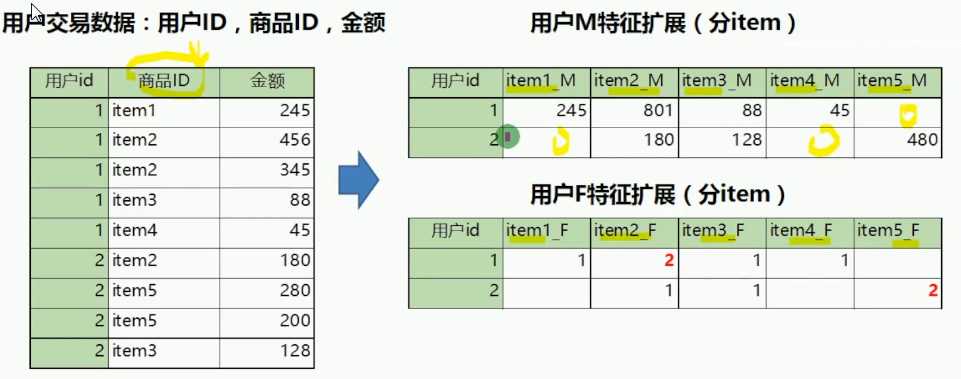
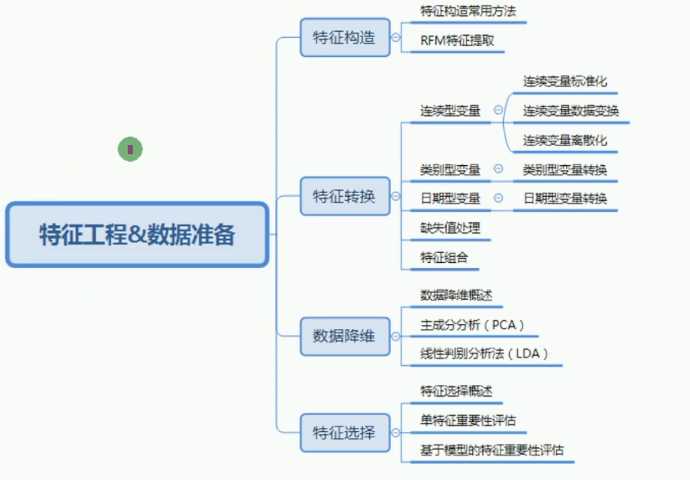
特征提取总结:
这个特征对预测目标是否有用
如果有用,这个特征的重要程度如何
这个特征的信息是否在其他特征重体现过
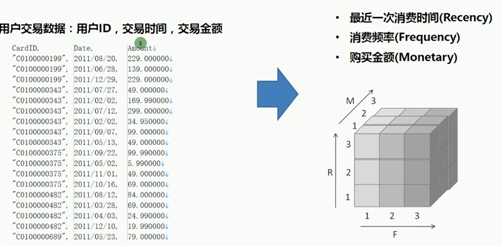
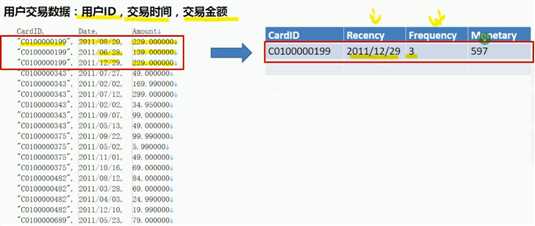
在客户关系(CRM)领域,三个刻画用户的神奇指标:
RFM分析方法有一种叫五等分法
把RFM切成5个人数等分区间,然后形成RFM的组合立方体
125个格子
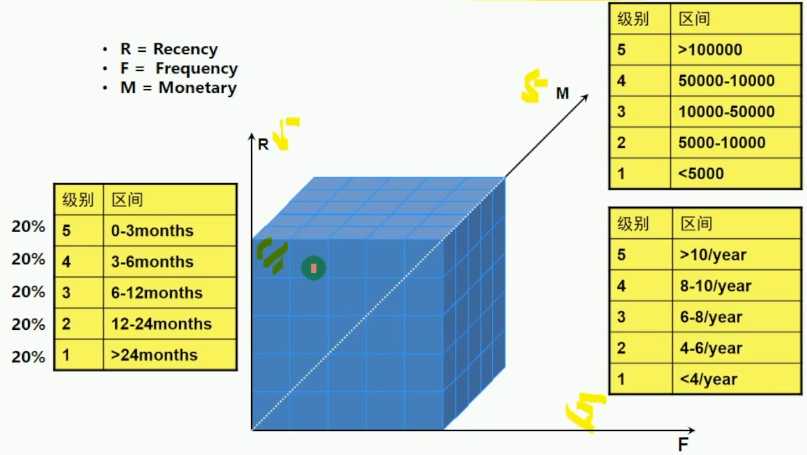
R越小越好,FM越大越好
R是越小,等级越大,于是RMF统一为等级越大越好
因此用户的等级范围是111-555
RFM应用价值:用户细分
111-555共125个群体,比较多,可以做一些合并
根据不同的RFM值组合情况,可以把用户分成不同群体,以便制定差异化策略
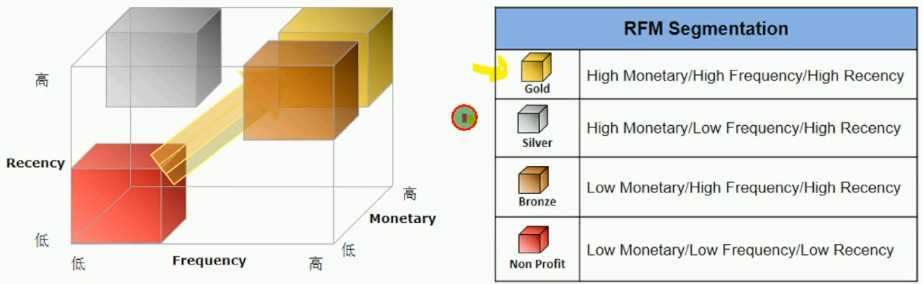
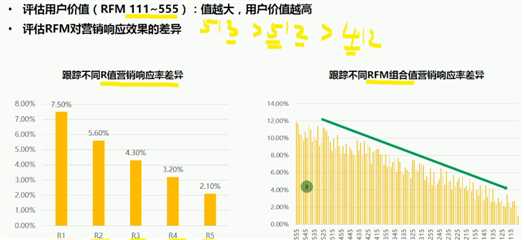
RFM应用价值:用户价值及营销响应评估
使不同规格尺度的数据转换到同一规格尺度
目的:
常用无量纲化方法--标准化
效果:把原始的连续变量转换为均值为0,标准差为1的变量
${x}‘=\frac{x-\bar{x}}{\delta }$
常用无量纲化方法--区间缩放法
效果:把原始的连续变量转换为范围在a-b之间的变量,常见的a=0,b=1
${x}‘=\frac{x-\min(x)}{\max(x)-\min(x) }$
数据变换:通过函数变换改变原数据的分布
目的:
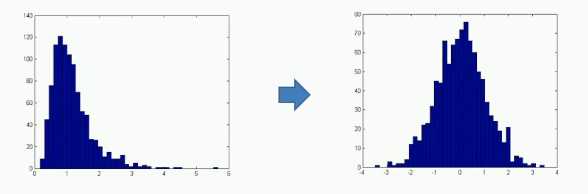
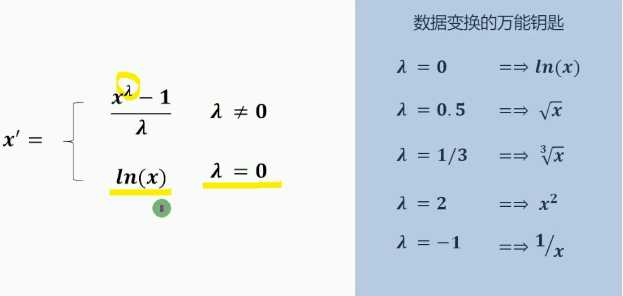
常用的数据变换方法
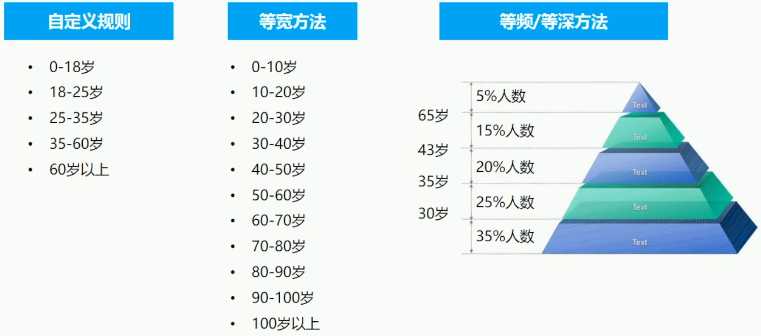
把连续型的数值切割为少数的一些区间,例如年龄值切割为5个年龄段
目的:
离散化方法:
非监督离散化方法
有监督的离散化:决策树
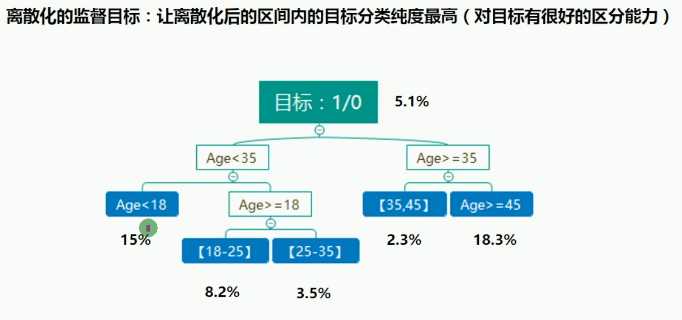
一种特殊的离散化:二值化
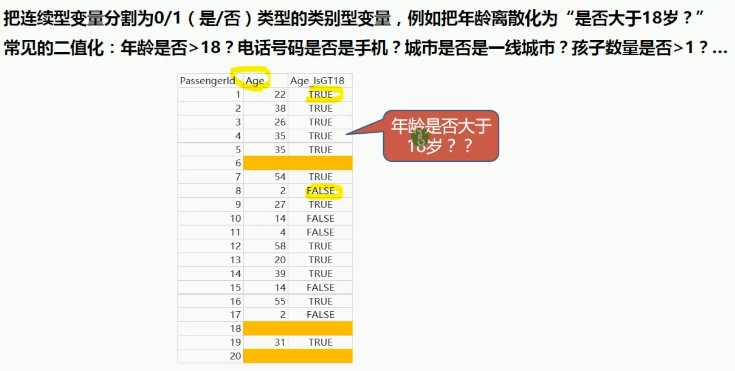
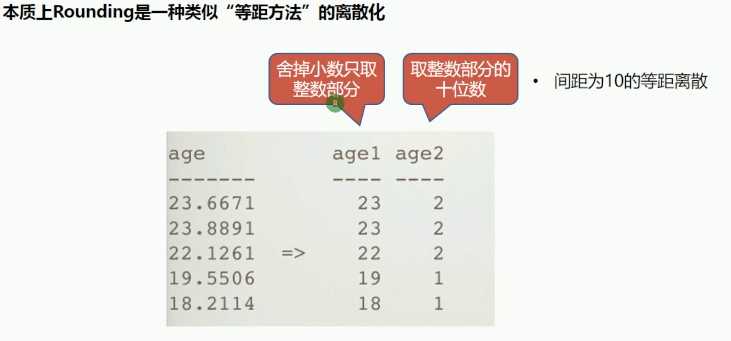
一种特殊的离散化:Rounding(取整)
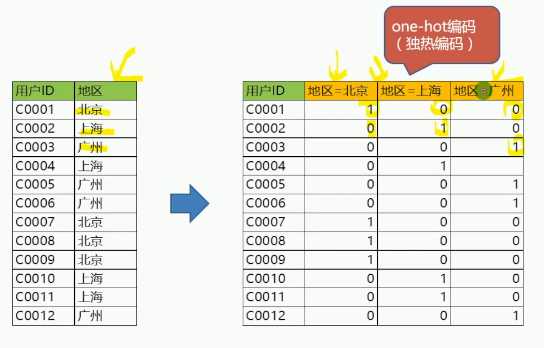
把类别型变量编码成数值型的变量
目的:
one-hot编码
Counting Encoding
用类别的频数来编码,也可以对频数去量纲化(秩序,归一化等)

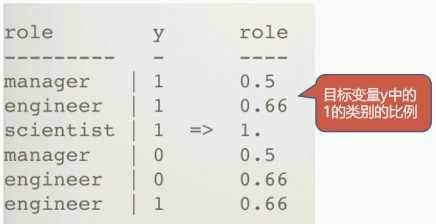
Target Encoding
用目标变量(二分类)中的某一类的比例来编码
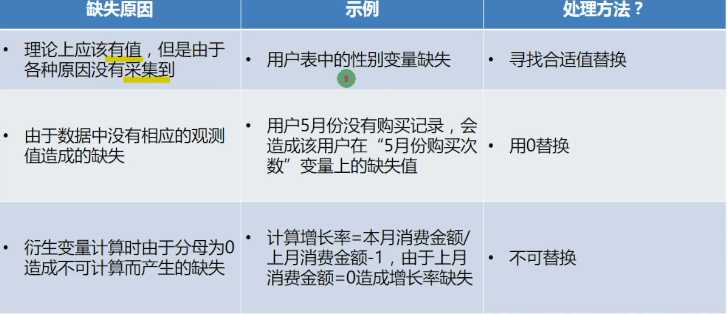
缺失值原因
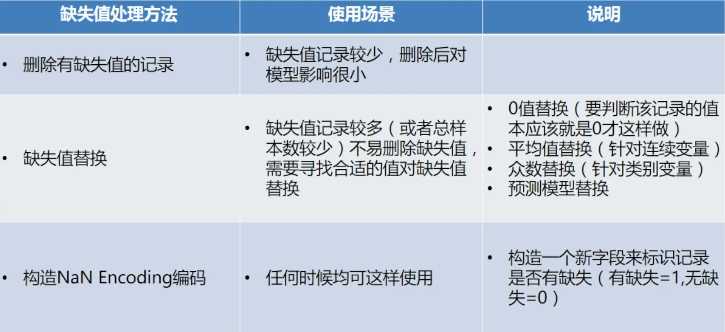
处理方法
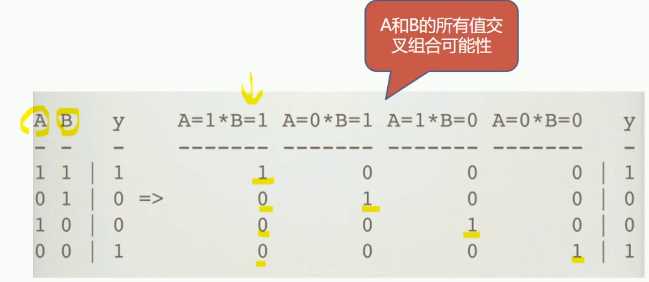
目的:通过特征组合构造出更多/更好的特征,提示模型精度

组合让特征更加精细,反映了原始多个特征之间的交互关系。
特征组合的方法

示例
在尽量少减少信息量的前提下,采用某种映射方法(函数),把原来的高维(变量多)数据映射为低维数据(变量少)
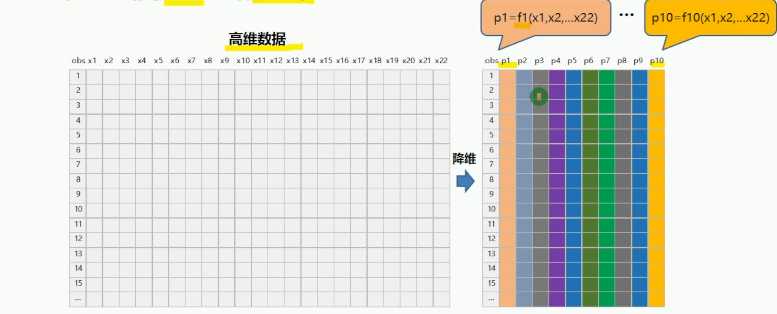
降维原因:
维数灾难
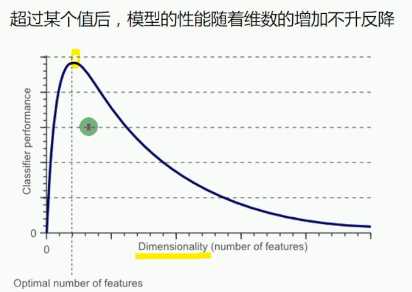
维数灾难原因
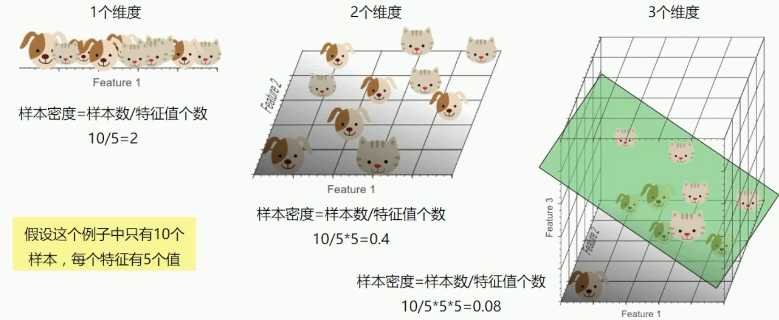
当特征值(空间)个数趋向无限大时,样本密度非常稀疏,训练样本被分错的可能性趋向于零
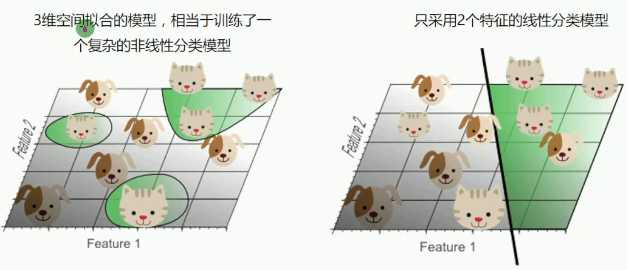
降维后发生什么?
线性模型可能精确度会下降,但是也会避免出现过拟合现象
避免维度灾难的一个方法是增加样本量
样本密度:样本数/特征值个数;当增加维度时,保持样本密度不变的方法就是增加样本量
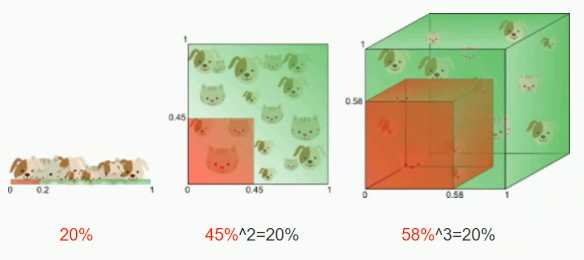
常用降维方法

主成分分析
通过某种线性投影,将高维数据映射到低维空间中表示,并期望在所投影的维度上数据方差最大。使用较少的数据维度,尽量保留住较多的数据信息。
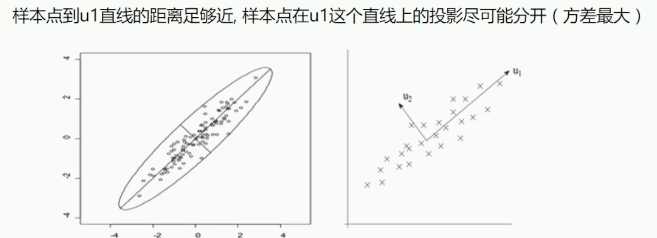
PCA操作流程
线性判别分析法
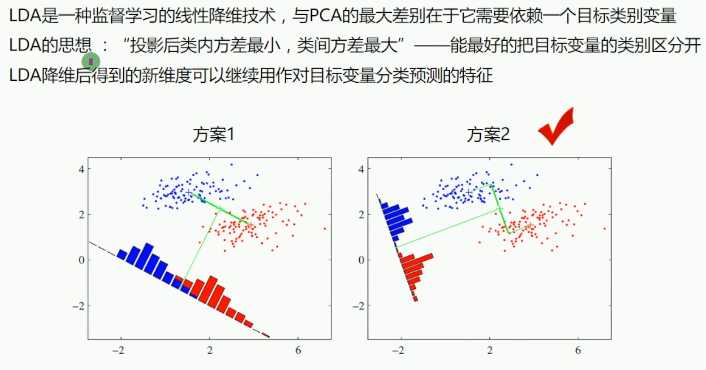
PCA与LDA
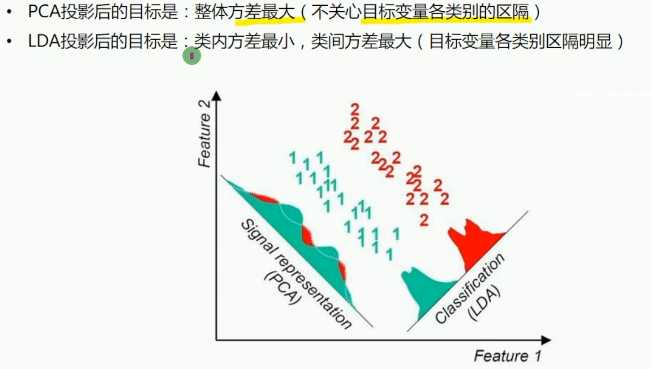
实验结果
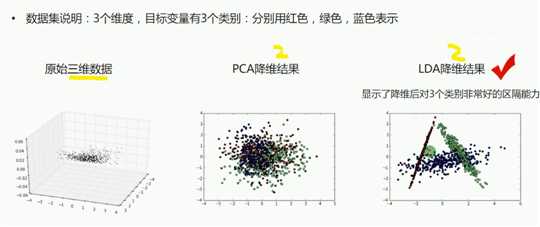
总结:
优先使用LDA来降维
可以使用PCA做小幅度的降维去噪声,然后再使用LDA降维
优先使用PCA来降维
特征选择与降维

特征选择原因:
特征选择的方法

单特征重要性评估
过滤方法
苹果onNet_month与Flag(目标)指标的相关性
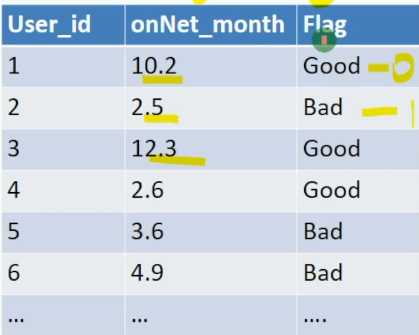
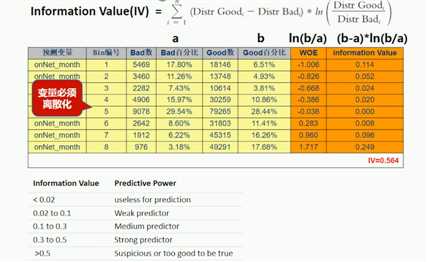
信息值(IV)
变量重要性可视化:趋势分析
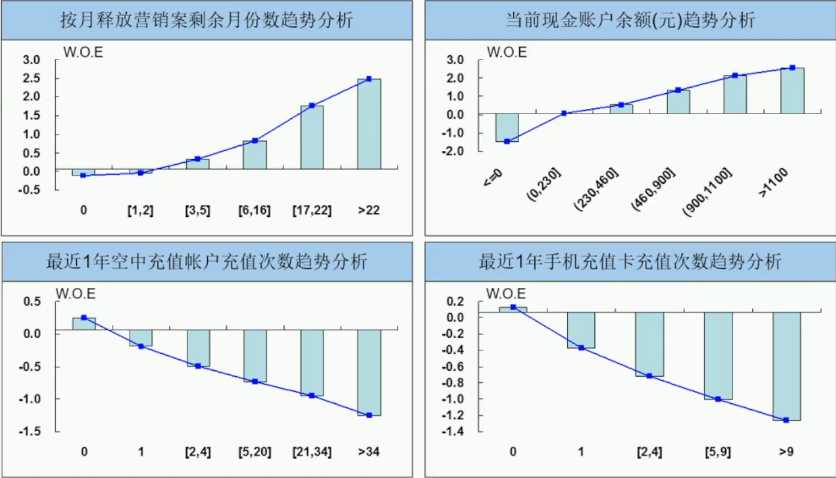
更多指标

标签:初始 多个 最大 strong 趋势分析 isp 统一 维度 targe
原文地址:https://www.cnblogs.com/aidata/p/11620888.html