标签:file 运行 info 程序 snapshot jdbc width sla 核数
cloudera官网spark:
https://docs.cloudera.com/documentation/enterprise/6/6.2/topics/spark.html
spark官网:
https://spark.apache.org/documentation.html
CDH安装spark:
https://my.oschina.net/gywbest/blog/3054588
spark开发:
https://docs.cloudera.com/documentation/enterprise/6/6.2/topics/spark_applications_developing.html
spark部署使用
https://www.cnblogs.com/qingyunzong/p/8888080.html GG
问题:
pattition和shuffle的区别
在CDH中开启spark:
添加服务:
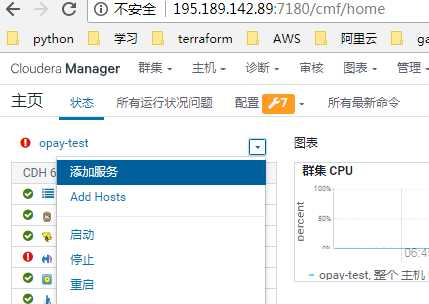
选spark---继续
角色分配,保持默认的点继续
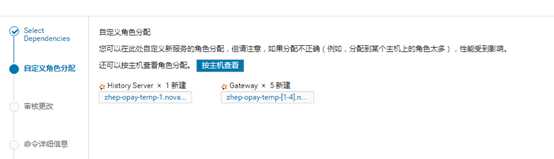
因为没有启用TLS/SSL,点继续:
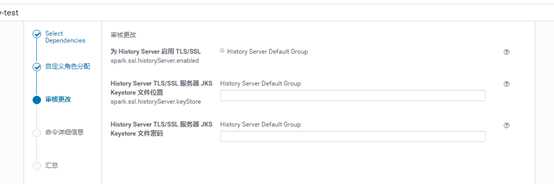
自动执行安装:
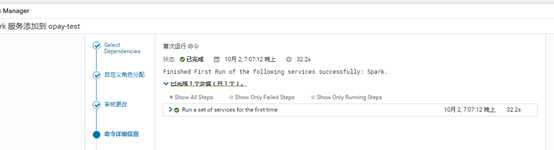
完成,点重启过时服务部署客户端:
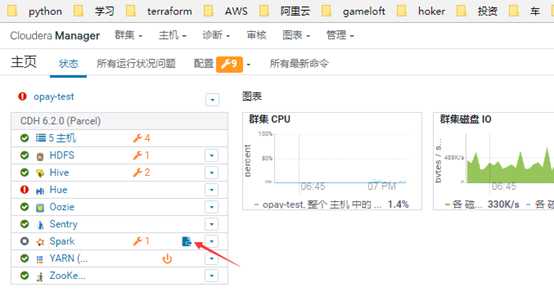
登陆任意节点,输入/usr/bin/spark-shell
jps可以看到:
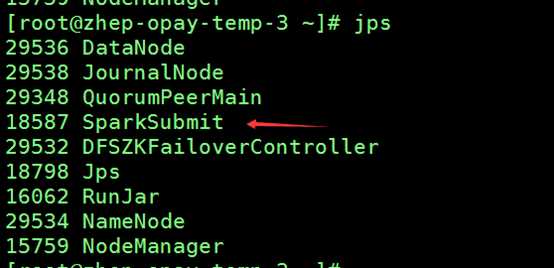
A Hive Gateway role is recommended but was not found on these hosts: zhep-opay-temp-[1-4].novalocal; zhep-opay-temp-big-data-1.novalocal. This will prevent Spark applications from reading Hive tables.
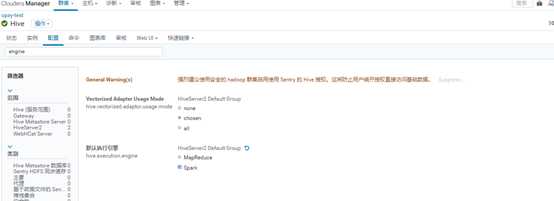
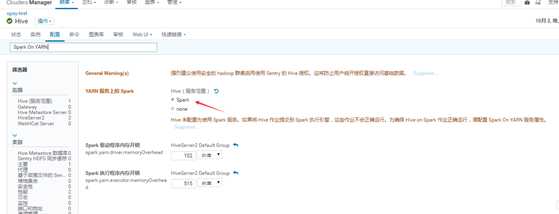
#执行数据量不大的任务,可在CDH中配置hive用spark引擎跑.按下面修改后,用beeline跑sql就调用的是spark,速度会快些.
之后跑数据量大的还是改回mapreduce,
自己搭建的spark:
In a CDH deployment, SPARK_HOME defaults to /usr/lib/spark in package installations and /opt/cloudera/parcels/CDH/lib/spark in parcel installations. In a Cloudera Manager deployment, the shells are also available from /usr/bin.
即CDH中要用spark-shell目录在,
/opt/cloudera/parcels/CDH/lib/
或: /usr/bin
#要在有hdfs权限的帐号下,su - hdfs:
SPARK_HOME/bin/spark-shell
SPARK_HOME/bin/pyspark
scala运行wordcount:
spark-submit --class com.cloudera.sparkwordcount.SparkWordCount \
--master本地--deploy-mode客户端--executor-memory 1g \
--name wordcount --conf“ spark.app.id = wordcount” \
sparkwordcount-1.0-SNAPSHOT-jar-with-dependencies.jar \
hdfs:// namenode_host:8020 / 路径/至 /inputfile.txt 2
pyspark运行wordcount:
spark-submit --master yarn --deploy-mode client --executor-memory 1g \
--name wordcount --conf“ spark.app.id = wordcount” wordcount.py \
hdfs:// namenode_host:8020 / 路径/至 /inputfile.txt 2
sparksql:
https://docs.cloudera.com/documentation/enterprise/6/6.2/topics/spark_sparksql.html
spark-shell
scala> sqlContext.sql("CREATE TABLE sample_07 (code string,description string,total_emp int,salary int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘ STORED AS TextFile")
scala> sqlContext.sql("CREATE TABLE sample_08 (code string,description string,total_emp int,salary int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘ STORED AS TextFile")
[0: jdbc:hive2://hostname.com:> show tables;
+------------+--+
| tab_name |
+------------+--+
| sample_07 |
| sample_08 |
+------------+--+
安装:
https://spark.apache.org/docs/2.4.4/
wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
tar -xzvf spark-2.4.4-bin-hadoop2.7.tgz -C /opt/module/
vim /etc/profile
export SPARK_HOME=/opt/module/spark-2.4.4-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
rename ‘.template‘ ‘‘ /opt/module/spark-2.4.4-bin-hadoop2.7/conf/*.template ; ll /opt/module/spark-2.4.4-bin-hadoop2.7/conf
cd /opt/module/spark-2.4.4-bin-hadoop2.7/conf
vim spark-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.el7_6.x86_64
export HADOOP_HOME=/hongfeng/software/hadoop-3.1.2
export HADOOP_CONF_DIR=/hongfeng/software/hadoop-3.1.2/etc/hadoop
vim spark-defaults.conf
spark.master spark://oride-dr-algo2:7077
spark.driver.memory 3g
vim slaves
oride-dr-algo3
oride-dr-algo4
oride-dr-algo2
把/etc/profile和/opt/module/spark-2.4.4-bin-hadoop2.7发送到其它节点3,4
启动:
/opt/module/spark-2.4.4-bin-hadoop2.7/sbin/start-all.sh
停止
/opt/module/spark-2.4.4-bin-hadoop2.7/sbin/stop-all.sh
#这表示已经启动
[root@zhep-opay-temp-1 ~]# /opt/module/spark-2.4.4-bin-hadoop2.7/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-2.4.4-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-zhep-opay-temp-1.novalocal.out
195.189.142.83: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-2.4.4-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-zhep-opay-temp-2.novalocal.out
195.189.142.86: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-2.4.4-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-zhep-opay-temp-3.novalocal.out
195.189.142.89: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-2.4.4-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-zhep-opay-temp-1.novalocal.out
[root@zhep-opay-temp-1 ~]# jps
#用jps查看,主节点出现一个master进程,从节点是worker进程
#8080可以看到spark的webui
http://195.189.142.89:8080/
#standalone模式提交作业:
spark-submit --class org.apache.spark.examples.JavaSparkPi \
> --master spark://oride-dr-algo2:7077 \
> /opt/module/spark-2.4.4-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.4.4.jar
#yarn模式
官网:https://spark.apache.org/docs/2.4.4/running-on-yarn.html
https://www.cnblogs.com/qingyunzong/p/8888080.html
#client模式
spark-shell --master yarn --deploy-mode client
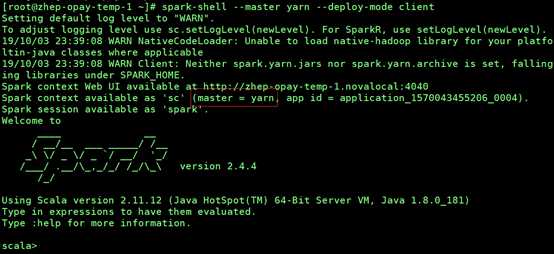
#yarn-cluster模式提交spark
执行Spark自带的示例程序PI
spark-submit --class org.apache.spark.examples.SparkPi \
> --master yarn \
> --deploy-mode cluster \ #用yarn cluster模式
> --driver-memory 500m \ #指定使用内存
> --executor-memory 500m \
> --executor-cores 1 \ #指定使用cpu核数
> /home/hadoop/apps/spark/examples/jars/spark-examples_2.11-2.3.0.jar \
> 10
#可以用这个做测试:
spark-submit --class org.apache.spark.examples.JavaSparkPi \
> --master yarn-cluster \
> /opt/module/spark-2.4.4-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.4.4.jar
yarn模式在yarn可看到刚才运行的作业:
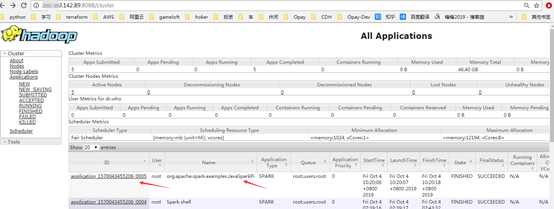
用yarn模式的日志不像standalone模式,查看8080端口就可以了,需要整合:
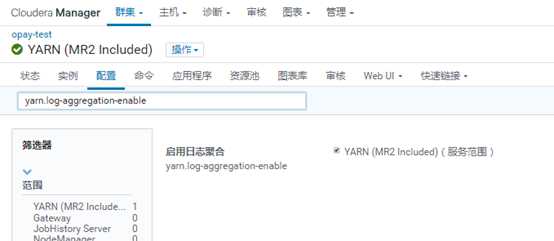
在CDH中:(默认已经是开启)
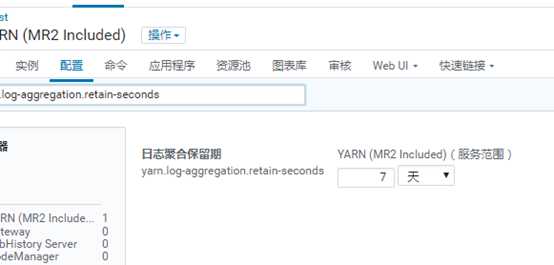
日志保留时间:
#如是单独搭建的hadoop:
见spark pdf
标签:file 运行 info 程序 snapshot jdbc width sla 核数
原文地址:https://www.cnblogs.com/hongfeng2019/p/11621629.html