标签:根据 core 安装 super soft vmw stop center --
一、 安装VMware虚拟机
二、 创建第一个Linux虚拟机节点,本机使用的centOS7.6 64位版本
三、 创建2个克隆节点
四、 3节点都关闭防火墙
命令:systemctl stop firewalld
关闭后查看防火墙状态确认是否关闭成功:systemctl status firewalld
五、 关闭 selinux
vi etc/selinux/config
SELINUX=disabled
六、 配置网络设置
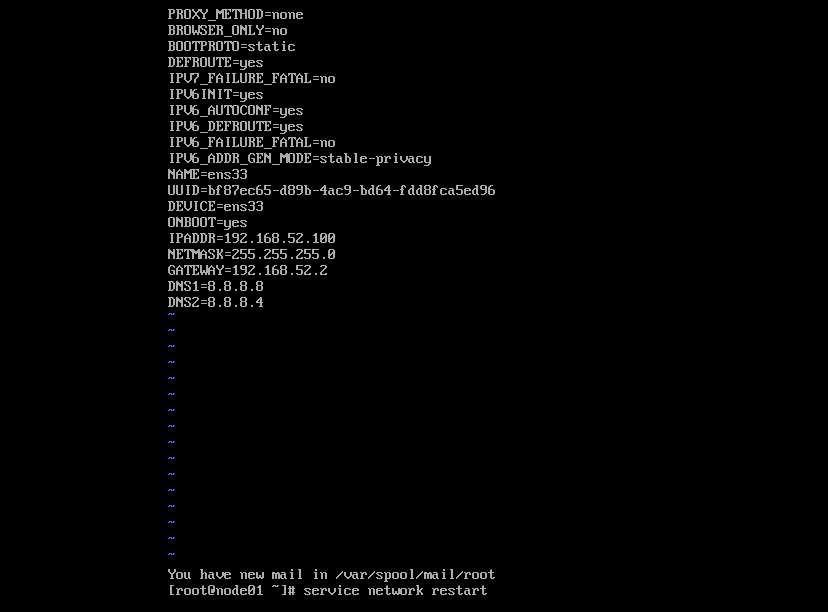
vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.XX.XX
NETMASK=255.255.255.0
GATEWAY=192.168.XX.2
DNS1=8.8.8.8
配置完毕,需重启网络服务
service network restart
七、三台虚拟机更改主机名
hostnamectl set-hostname node01
hostnamectl set-hostname node02
hostnamectl set-hostname node03
并更改hosts文件配置主机名与ip地址的映射关系
vi etc/hosts
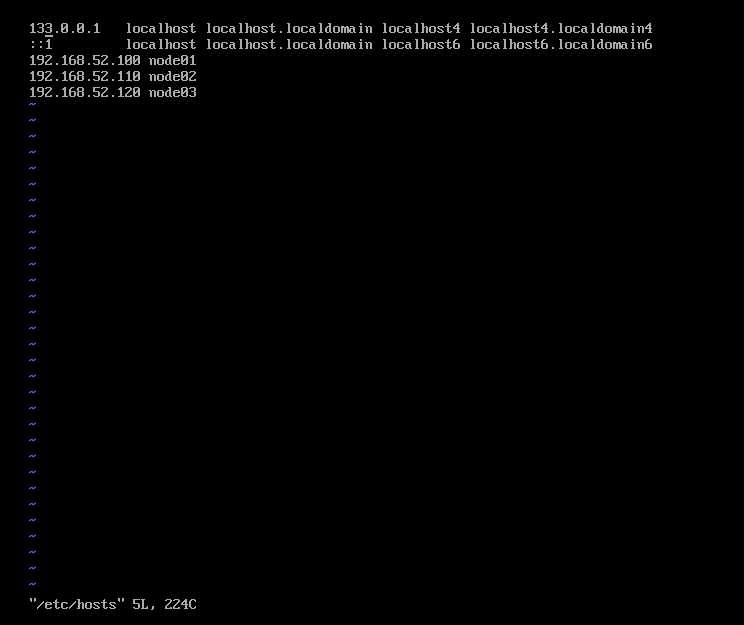
重启虚拟机后生效
八、三台机器配置时间同步,这里选择aliyun的ntp服务器
yum -y install ntpdate
crontab -e
*/1 * * * * /usr/sbin/ntpdate time1.aliyun.com
九、添加hadoop专用用户,并赋予sudo权限
useradd hadoop
passwd XXXXXX
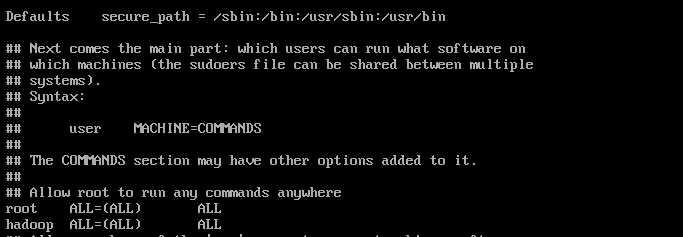
visudo
配置文件中添加
Hadoop ALL=(ALL) ALL
九、为hadoop应用创建专用目录
mkdir -p /hadoop/soft
mkdir -p /hadoop/install
将文件夹所有者更改为hadoop用户
chown -R hadoop:hadoop /hadoop
十、三台机器安装jdk
切换到hadoop用户,解压并安装jdk,此处使用1.8版本
cd /hadoop/soft/
配置hadoop用户的环境变量
cd /home/hadoop
vi .bash_profile
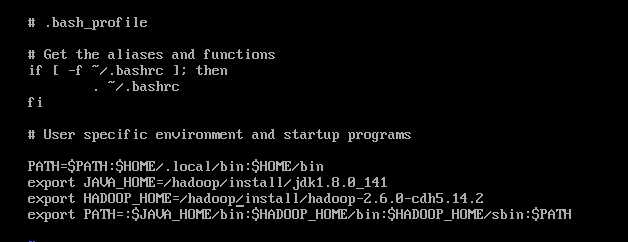
配置完成后,重新加载配置文件:source .bash_profile
验证配置:java -version
十一、配置hadoop用户免密登录
三台机器执行命令
ssh-keygen -t rsa
生成公钥与私钥
将公钥拷贝到节点1
ssh-copy-id node01
再从node01将公钥文件复制到其他两个节点
cd /home/hadoop/.ssh/
scp authorized_keys node02:$PWD
scp authorized_keys node03:$PWD
验证配置
三台虚拟机分别执行ssh命令连接到其他到其他机器,如连接失败,可删除hadoop用户目录下的.ssh文件夹重复该步骤。
十二、
解压安装hadoop,本机使用的是CDH发行版的hadoop
配置环境变量,此处仍然配置在hadoop用户下
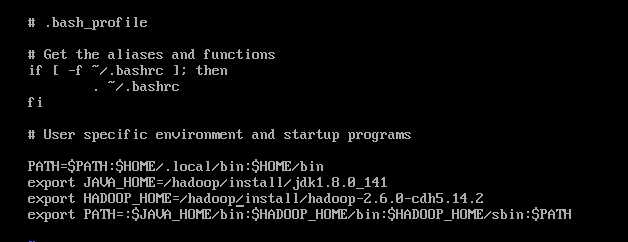
配置完成后,重新加载环境变量:source .bash_profile
验证配置:java -version
hadoop version
如能正常输出版本信息,即验证配置成功
十三、
以下为hadoop的配置文件配置,建议使用远程连接工具登录虚拟机进行编辑
1、配置hadoop-env.sh文件
cd /hadoop/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
vi hadoop-env.sh
此文件内只需导入jdk的安装目录
export JAVA_HOME=/hadoop/install/jdk1.8.0_141
2、配置core-site.xml
cd /hadoop/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
<description>检查点被删除后的分钟数。 如果为零,垃圾桶功能将被禁用。
该选项可以在服务器和客户端上配置。 如果垃圾箱被禁用服务器端,则检查客户端配置。
如果在服务器端启用垃圾箱,则会使用服务器上配置的值,并忽略客户端配置值。</description>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>0</value>
<description>垃圾检查点之间的分钟数。 应该小于或等于fs.trash.interval。
如果为零,则将该值设置为fs.trash.interval的值。 每次检查指针运行时,
它都会从当前创建一个新的检查点,并删除比fs.trash.interval更早创建的检查点。</description>
</property>
</configuration>
3、配置hdfs-site.xml
<configuration>
<!-- NameNode存储元数据信息的路径,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<!-- 集群动态上下线
<property>
<name>dfs.hosts</name>
<value>/hadoop/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/accept_host</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/hadoop/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/deny_host</value>
</property>
-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/datanodeDatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
4、配置mapred-site.xml
vi mapred-site.xml
<!--指定运行mapreduce的环境是yarn -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
</configuration>
5、配置yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node01:19888/jobhistory/logs</value>
</property>
<!--多长时间聚合删除一次日志 此处-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>2592000</value><!--30 day-->
</property>
<!--时间在几秒钟内保留用户日志。只适用于如果日志聚合是禁用的-->
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>604800</value><!--7 day-->
</property>
<!--指定文件压缩类型用于压缩汇总日志-->
<property>
<name>yarn.nodemanager.log-aggregation.compression-type</name>
<value>gz</value>
</property>
<!-- nodemanager本地文件存储目录-->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/yarn/local</value>
</property>
<!-- resourceManager 保存最大的任务完成个数 -->
<property>
<name>yarn.resourcemanager.max-completed-applications</name>
<value>1000</value>
</property>
</configuration>
6、创建文件存放目录
[root@node01 ~]# mkdir -p /hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/tempDatas
[root@node01 ~]# mkdir -p /hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas
[root@node01 ~]# mkdir -p /hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/datanodeDatas
[root@node01 ~]# mkdir -p /hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits
[root@node01 ~]# mkdir -p /hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/snn/name
[root@node01 ~]# mkdir -p /hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/snn/edits
十四、格式化hadoop(此步骤是在hadoop集群启动前,在namenode(主节点)执行)
hdfs namenode -format
以下为部分日志,供参考
19/08/23 04:32:34 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = hadoop
STARTUP_MSG: host = node01.kaikeba.com/192.168.52.100
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.6.0-cdh5.14.2
STARTUP_MSG: classpath = /hadoop/install/hadoop-2.6.0-19/08/23 04:32:35 INFO common.Storage: Storage directory /hadoop/install/hadoop-2.6.0-
#显示格式化成功。。。
cdh5.14.2/hadoopDatas/namenodeDatas has been successfully formatted.
19/08/23 04:32:35 INFO common.Storage: Storage directory /hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits has been successfully formatted.
19/08/23 04:32:35 INFO namenode.FSImageFormatProtobuf: Saving image file /hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas/current/fsimage.ckpt_0000000000000000000 using no compression
19/08/23 04:32:35 INFO namenode.FSImageFormatProtobuf: Image file /hadoop/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas/current/fsimage.ckpt_0000000000000000000 of size 323 bytes saved in 0 seconds.
19/08/23 04:32:35 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
19/08/23 04:32:35 INFO util.ExitUtil: Exiting with status 0
19/08/23 04:32:35 INFO namenode.NameNode: SHUTDOWN_MSG:
#此处省略部分日志
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node01.kaikeba.com/192.168.52.100
************************************************************/
十五、启动集群
start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
19/08/23 05:18:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [node01]
node01: starting namenode, logging to /hadoop/install/hadoop-2.6.0-cdh5.14.2/logs/hadoop-hadoop-namenode-node01.kaikeba.com.out
node01: starting datanode, logging to /hadoop/install/hadoop-2.6.0-cdh5.14.2/logs/hadoop-hadoop-datanode-node01.kaikeba.com.out
node03: starting datanode, logging to /hadoop/install/hadoop-2.6.0-cdh5.14.2/logs/hadoop-hadoop-datanode-node03.kaikeba.com.out
node02: starting datanode, logging to /hadoop/install/hadoop-2.6.0-cdh5.14.2/logs/hadoop-hadoop-datanode-node02.kaikeba.com.out
Starting secondary namenodes [node01]
node01: starting secondarynamenode, logging to /hadoop/install/hadoop-2.6.0-cdh5.14.2/logs/hadoop-hadoop-secondarynamenode-node01.kaikeba.com.out
19/08/23 05:18:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
starting yarn daemons
starting resourcemanager, logging to /hadoop/install/hadoop-2.6.0-cdh5.14.2/logs/yarn-hadoop-resourcemanager-node01.kaikeba.com.out
node03: starting nodemanager, logging to /hadoop/install/hadoop-2.6.0-cdh5.14.2/logs/yarn-hadoop-nodemanager-node03.kaikeba.com.out
node02: starting nodemanager, logging to /hadoop/install/hadoop-2.6.0-cdh5.14.2/logs/yarn-hadoop-nodemanager-node02.kaikeba.com.out
node01: starting nodemanager, logging to /hadoop/install/hadoop-2.6.0-cdh5.14.2/logs/yarn-hadoop-nodemanager-node01.kaikeba.com.out
[hadoop@node01 ~]$
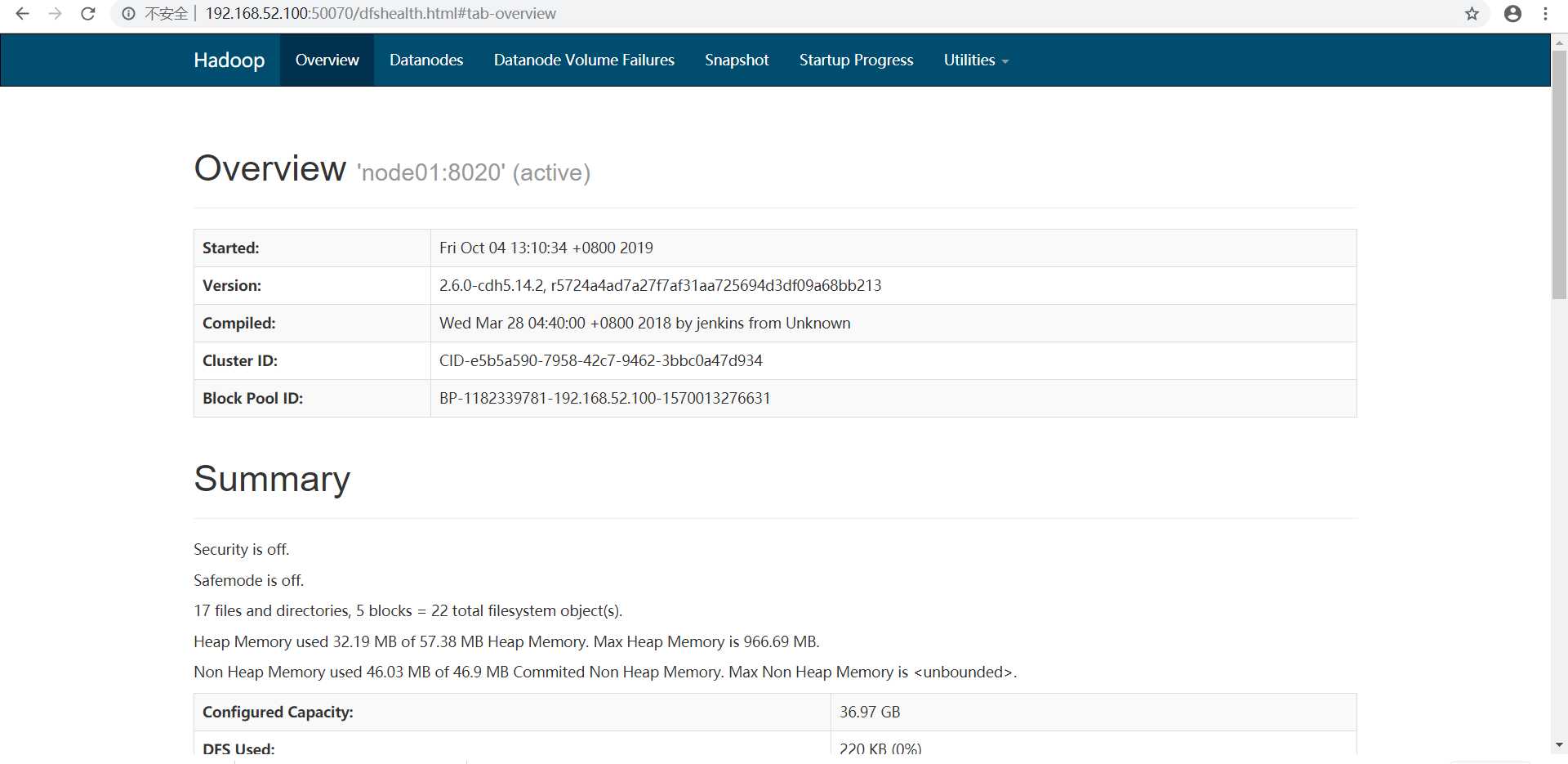
在浏览器地址栏输入http://192.168.52.100:50070/dfshealth.html#tab-overview查看namenode的web界面
十六、运行mapreduce程序
1、 使用 hdfs dfs -ls / 命令浏览hdfs文件系统
hdfs dfs -ls
由于集群刚搭建,此时没有目录显示
2、 创建测试目录
hdfs dfs -mkdir /test
再浏览目录,可以看到新创建的目录
hdfs dfs -ls /test
19/08/23 05:22:25 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2019-08-23 05:21 /test/
3、 使用touch命令在linux本地创建一个words文件
touch words
vi words
sadfasdfasdfas2rzxcvzr3r23
sadfasdfhszcxvhh8
4、 将创建的本地words文件上传到hdfs的test目录上
hdfs dfs -put words /test
查看文件是否上传成功
hdfs dfs -ls -r /test
执行命令,统计/test/words文件中的单词个数,并输出到test/output文件中,output文件不能是已经存在的,否则会报错
hadoop jar /hadoop/install/hadoop-2.6.0-cdh5.14.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.14.2.jar wordcount /test/words /test/output
十七、关闭集群
stop-all.sh
标签:根据 core 安装 super soft vmw stop center --
原文地址:https://www.cnblogs.com/zf-mylover/p/11622020.html