标签:自己的 load() col discover selected == 连通 自动 脚本
Redis的集群方案大致有三种:1)redis cluster集群方案;2)master/slave主从方案;3)哨兵模式来进行主从替换以及故障恢复。
一、sentinel哨兵模式介绍
Sentinel(哨兵)是用于监控redis集群中Master状态的工具,是Redis 的高可用性解决方案,sentinel哨兵模式已经被集成在redis2.4之后的版本中。sentinel是redis高可用的解决方案,sentinel系统可以监视一个或者多个redis master服务,以及这些master服务的所有从服务;当某个master服务下线时,自动将该master下的某个从服务升级为master服务替代已下线的master服务继续处理请求。
sentinel可以让redis实现主从复制,当一个集群中的master失效之后,sentinel可以选举出一个新的master用于自动接替master的工作,集群中的其他redis服务器自动指向新的master同步数据。一般建议sentinel采取奇数台,防止某一台sentinel无法连接到master导致误切换。其结构如下:
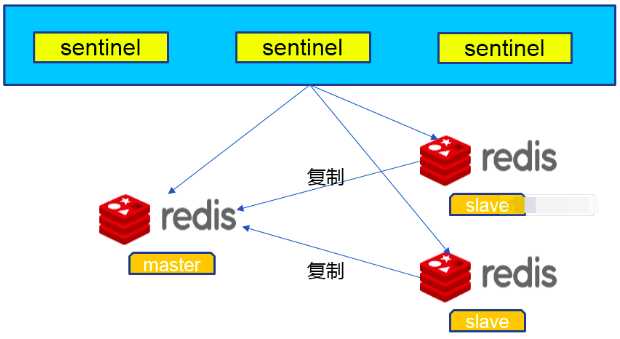
Redis-Sentinel是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。Sentinel由一个或多个Sentinel 实例 组成的Sentinel 系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器。
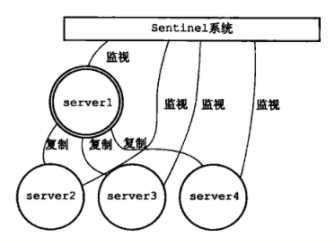
例如下图所示:
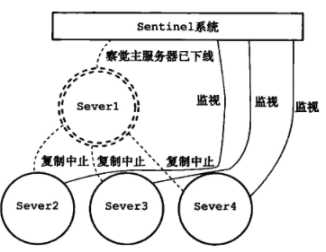
在Server1 掉线后:
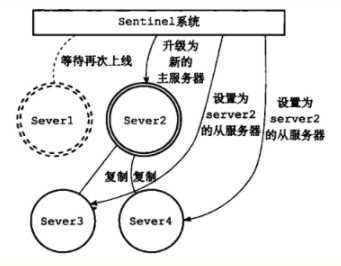
升级Server2 为新的主服务器:
Sentinel版本
Sentinel当前最新的稳定版本称为Sentinel 2(与之前的Sentinel 1区分开来)。随着redis2.8的安装包一起发行。安装完Redis2.8后,可以在redis2.8/src/里面找到Redis-sentinel的启动程序。
强烈建议:如果你使用的是redis2.6(sentinel版本为sentinel 1),你最好应该使用redis2.8版本的sentinel 2,因为sentinel 1有很多的Bug,已经被官方弃用,所以强烈建议使用redis2.8以及sentinel 2。
Sentinel状态持久化
snetinel的状态会被持久化地写入sentinel的配置文件中。每次当收到一个新的配置时,或者新创建一个配置时,配置会被持久化到硬盘中,并带上配置的版本戳。这意味着,可以安全的停止和重启sentinel进程。
Sentinel作用:
1)Master状态检测
2)如果Master异常,则会进行Master-Slave切换,将其中一个Slave作为Master,将之前的Master作为Slave。
3)Master-Slave切换后,master_redis.conf、slave_redis.conf和sentinel.conf的内容都会发生改变,即master_redis.conf中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换。
Sentinel工作方式(每个Sentinel实例都执行的定时任务)
1)每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个PING命令。
2)如果一个实例(instance)距离最后一次有效回复PING命令的时间超过 own-after-milliseconds 选项所指定的值,则这个实例会被Sentinel标记为主观下线。
3)如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
4)当有足够数量的Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态,则Master会被标记为客观下线。
5)在一般情况下,每个Sentinel 会以每10秒一次的频率向它已知的所有Master,Slave发送 INFO 命令。
6)当Master被Sentinel标记为客观下线时,Sentinel 向下线的 Master 的所有Slave发送 INFO命令的频率会从10秒一次改为每秒一次。
7)若没有足够数量的Sentinel同意Master已经下线,Master的客观下线状态就会被移除。 若 Master重新向Sentinel 的PING命令返回有效回复,Master的主观下线状态就会被移除。
三个定时任务
sentinel在内部有3个定时任务
1)每10秒每个sentinel会对master和slave执行info命令,这个任务达到两个目的:
a)发现slave节点
b)确认主从关系
2)每2秒每个sentinel通过master节点的channel交换信息(pub/sub)。master节点上有一个发布订阅的频道(__sentinel__:hello)。sentinel节点通过__sentinel__:hello频道进行信息交换(对节点的"看法"和自身的信息),达成共识。
3)每1秒每个sentinel对其他sentinel和redis节点执行ping操作(相互监控),这个其实是一个心跳检测,是失败判定的依据。
主观下线
所谓主观下线(Subjectively Down, 简称 SDOWN)指的是单个Sentinel实例对服务器做出的下线判断,即单个sentinel认为某个服务下线(有可能是接收不到订阅,之间的网络不通等等原因)。
主观下线就是说如果服务器在down-after-milliseconds给定的毫秒数之内, 没有返回 Sentinel 发送的 PING 命令的回复, 或者返回一个错误, 那么 Sentinel 将这个服务器标记为主观下线(SDOWN )。
sentinel会以每秒一次的频率向所有与其建立了命令连接的实例(master,从服务,其他sentinel)发ping命令,通过判断ping回复是有效回复,还是无效回复来判断实例时候在线(对该sentinel来说是“主观在线”)。
sentinel配置文件中的down-after-milliseconds设置了判断主观下线的时间长度,如果实例在down-after-milliseconds毫秒内,返回的都是无效回复,那么sentinel回认为该实例已(主观)下线,修改其flags状态为SRI_S_DOWN。如果多个sentinel监视一个服务,有可能存在多个sentinel的down-after-milliseconds配置不同,这个在实际生产中要注意。
客观下线
客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断,然后开启failover。
客观下线就是说只有在足够数量的 Sentinel 都将一个服务器标记为主观下线之后, 服务器才会被标记为客观下线(ODOWN)。
只有当master被认定为客观下线时,才会发生故障迁移。
当sentinel监视的某个服务主观下线后,sentinel会询问其它监视该服务的sentinel,看它们是否也认为该服务主观下线,接收到足够数量(这个值可以配置)的sentinel判断为主观下线,既任务该服务客观下线,并对其做故障转移操作。
sentinel通过发送 SENTINEL is-master-down-by-addr ip port current_epoch runid,(ip:主观下线的服务id,port:主观下线的服务端口,current_epoch:sentinel的纪元,runid:*表示检测服务下线状态,如果是sentinel 运行id,表示用来选举领头sentinel)来询问其它sentinel是否同意服务下线。
一个sentinel接收另一个sentinel发来的is-master-down-by-addr后,提取参数,根据ip和端口,检测该服务时候在该sentinel主观下线,并且回复is-master-down-by-addr,回复包含三个参数:down_state(1表示已下线,0表示未下线),leader_runid(领头sentinal id),leader_epoch(领头sentinel纪元)。
sentinel接收到回复后,根据配置设置的下线最小数量,达到这个值,既认为该服务客观下线。
客观下线条件只适用于主服务器: 对于任何其他类型的 Redis 实例, Sentinel 在将它们判断为下线前不需要进行协商, 所以从服务器或者其他 Sentinel 永远不会达到客观下线条件。只要一个 Sentinel 发现某个主服务器进入了客观下线状态, 这个 Sentinel 就可能会被其他 Sentinel 推选出, 并对失效的主服务器执行自动故障迁移操作。
在redis-sentinel的conf文件里有这么两个配置:
1)sentinel monitor <masterName> <ip> <port> <quorum>
四个参数含义:
masterName这个是对某个master+slave组合的一个区分标识(一套sentinel是可以监听多套master+slave这样的组合的)。
ip 和 port 就是master节点的 ip 和 端口号。
quorum这个参数是进行客观下线的一个依据,意思是至少有 quorum 个sentinel主观的认为这个master有故障,才会对这个master进行下线以及故障转移。因为有的时候,某个sentinel节点可能因为自身网络原因,导致无法连接master,而此时master并没有出现故障,所以这就需要多个sentinel都一致认为该master有问题,才可以进行下一步操作,这就保证了公平性和高可用。
2)sentinel down-after-milliseconds <masterName> <timeout>
这个配置其实就是进行主观下线的一个依据,masterName这个参数不用说了,timeout是一个毫秒值,表示:如果这台sentinel超过timeout这个时间都无法连通master包括slave(slave不需要客观下线,因为不需要故障转移)的话,就会主观认为该master已经下线(实际下线需要客观下线的判断通过才会下线)
那么,多个sentinel之间是如何达到共识的呢?
这就是依赖于前面说的第二个定时任务,某个sentinel先将master节点进行一个主观下线,然后会将这个判定通过sentinel is-master-down-by-addr这个命令问对应的节点是否也同样认为该addr的master节点要做客观下线。最后当达成这一共识的sentinel个数达到前面说的quorum设置的这个值时,就会对该master节点下线进行故障转移。quorum的值一般设置为sentinel个数的二分之一加1,例如3个sentinel就设置2。
主观下线(SDOWN)和客观下线(ODOWN)的更多细节
sentinel对于不可用有两种不同的看法,一个叫主观不可用(SDOWN),另外一个叫客观不可用(ODOWN)。SDOWN是sentinel自己主观上检测到的关于master的状态,ODOWN需要一定数量的sentinel达成一致意见才能认为一个master客观上已经宕掉,各个sentinel之间通过命令SENTINEL is_master_down_by_addr来获得其它sentinel对master的检测结果。
从sentinel的角度来看,如果发送了PING心跳后,在一定时间内没有收到合法的回复,就达到了SDOWN的条件。这个时间在配置中通过is-master-down-after-milliseconds参数配置。
当sentinel发送PING后,以下回复之一都被认为是合法的:
PING replied with +PONG.
PING replied with -LOADING error.
PING replied with -MASTERDOWN error.
其它任何回复(或者根本没有回复)都是不合法的。
从SDOWN切换到ODOWN不需要任何一致性算法,只需要一个gossip协议:如果一个sentinel收到了足够多的sentinel发来消息告诉它某个master已经down掉了,SDOWN状态就会变成ODOWN状态。如果之后master可用了,这个状态就会相应地被清理掉。
正如之前已经解释过了,真正进行failover需要一个授权的过程,但是所有的failover都开始于一个ODOWN状态。
ODOWN状态只适用于master,对于不是master的redis节点sentinel之间不需要任何协商,slaves和sentinel不会有ODOWN状态。
配置版本号
为什么要先获得大多数sentinel的认可时才能真正去执行failover呢?
当一个sentinel被授权后,它将会获得宕掉的master的一份最新配置版本号,当failover执行结束以后,这个版本号将会被用于最新的配置。因为大多数sentinel都已经知道该版本号已经被要执行failover的sentinel拿走了,所以其他的sentinel都不能再去使用这个版本号。这意味着,每次failover都会附带有一个独一无二的版本号。我们将会看到这样做的重要性。而且,sentinel集群都遵守一个规则:如果sentinel A推荐sentinel B去执行failover,B会等待一段时间后,自行再次去对同一个master执行failover,这个等待的时间是通过failover-timeout配置项去配置的。从这个规则可以看出,sentinel集群中的sentinel不会再同一时刻并发去failover同一个master,第一个进行failover的sentinel如果失败了,另外一个将会在一定时间内进行重新进行failover,以此类推。
redis sentinel保证了活跃性:如果大多数sentinel能够互相通信,最终将会有一个被授权去进行failover.
redis sentinel也保证了安全性:每个试图去failover同一个master的sentinel都会得到一个独一无二的版本号。
配置传播
一旦一个sentinel成功地对一个master进行了failover,它将会把关于master的最新配置通过广播形式通知其它sentinel,其它的sentinel则更新对应master的配置。
一个faiover要想被成功实行,sentinel必须能够向选为master的slave发送SLAVEOF NO ONE命令,然后能够通过INFO命令看到新master的配置信息。
当将一个slave选举为master并发送SLAVEOF NO ONE后,即使其它的slave还没针对新master重新配置自己,failover也被认为是成功了的,然后所有sentinels将会发布新的配置信息。
新配在集群中相互传播的方式,就是为什么我们需要当一个sentinel进行failover时必须被授权一个版本号的原因。
每个sentinel使用##发布/订阅##的方式持续地传播master的配置版本信息,配置传播的##发布/订阅##管道是:__sentinel__:hello。
因为每一个配置都有一个版本号,所以以版本号最大的那个为标准。
举个例子:
假设有一个名为mymaster的地址为192.168.10.202:6379。一开始,集群中所有的sentinel都知道这个地址,于是为mymaster的配置打上版本号1。一段时候后mymaster死了,有一个sentinel被授权用版本号2对其进行failover。如果failover成功了,假设地址改为了192.168.10.202:9000,此时配置的版本号为2,进行failover的sentinel会将新配置广播给其他的sentinel,由于其他sentinel维护的版本号为1,发现新配置的版本号为2时,版本号变大了,说明配置更新了,于是就会采用最新的版本号为2的配置。
这意味着sentinel集群保证了第二种活跃性:一个能够互相通信的sentinel集群最终会采用版本号最高且相同的配置。
sentinel的"仲裁会"
前面我们谈到,当一个master被sentinel集群监控时,需要为它指定一个参数,这个参数指定了当需要判决master为不可用,并且进行failover时,所需要的sentinel数量,可以称这个参数为票数
不过,当failover主备切换真正被触发后,failover并不会马上进行,还需要sentinel中的大多数sentinel授权后才可以进行failover。
当ODOWN时,failover被触发。failover一旦被触发,尝试去进行failover的sentinel会去获得“大多数”sentinel的授权(如果票数比大多数还要大的时候,则询问更多的sentinel)
这个区别看起来很微妙,但是很容易理解和使用。例如,集群中有5个sentinel,票数被设置为2,当2个sentinel认为一个master已经不可用了以后,将会触发failover,但是,进行failover的那个sentinel必须先获得至少3个sentinel的授权才可以实行failover。
如果票数被设置为5,要达到ODOWN状态,必须所有5个sentinel都主观认为master为不可用,要进行failover,那么得获得所有5个sentinel的授权。
选举领头sentinel(即领导者选举)
一个redis服务被判断为客观下线时,多个监视该服务的sentinel协商,选举一个领头sentinel,对该redis服务进行故障转移操作。选举领头sentinel遵循以下规则:
1)所有的sentinel都有公平被选举成领头的资格。
2)所有的sentinel都有且只有一次将某个sentinel选举成领头的机会(在一轮选举中),一旦选举某个sentinel为领头,不能更改。
3)sentinel设置领头sentinel是先到先得,一旦当前sentinel设置了领头sentinel,以后要求设置sentinel为领头请求都会被拒绝。
4)每个发现服务客观下线的sentinel,都会要求其他sentinel将自己设置成领头。
5)当一个sentinel(源sentinel)向另一个sentinel(目sentinel)发送is-master-down-by-addr ip port current_epoch runid命令的时候,runid参数不是*,而是sentinel运行id,就表示源sentinel要求目标sentinel选举其为领头。
6)源sentinel会检查目标sentinel对其要求设置成领头的回复,如果回复的leader_runid和leader_epoch为源sentinel,表示目标sentinel同意将源sentinel设置成领头。
7)如果某个sentinel被半数以上的sentinel设置成领头,那么该sentinel既为领头。
8)如果在限定时间内,没有选举出领头sentinel,暂定一段时间,再选举。
为什么要选领导者?
简单来说,就是因为只能有一个sentinel节点去完成故障转移。
sentinel is-master-down-by-addr这个命令有两个作用,一是确认下线判定,二是进行领导者选举。
选举过程:
1)每个做主观下线的sentinel节点向其他sentinel节点发送上面那条命令,要求将它设置为领导者。
2)收到命令的sentinel节点如果还没有同意过其他的sentinel发送的命令(还未投过票),那么就会同意,否则拒绝。
3)如果该sentinel节点发现自己的票数已经过半且达到了quorum的值,就会成为领导者
4)如果这个过程出现多个sentinel成为领导者,则会等待一段时间重新选举。
Redis Sentinel的主从切换方案
Redis 2.8版开始正式提供名为Sentinel的主从切换方案,通俗的来讲,Sentinel可以用来管理多个Redis服务器实例,可以实现一个功能上实现HA的集群,Sentinel主要负责三个方面的任务:
1)监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
2)提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
3)自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
Redis Sentinel 是一个分布式系统, 可以在一个架构中运行多个 Sentinel 进程(progress), 这些进程使用流言协议(gossip protocols)来接收关于主服务器是否下线的信息, 并使用投票协议(agreement protocols)来决定是否执行自动故障迁移, 以及选择哪个从服务器作为新的主服务器。
一个简单的主从结构加sentinel集群的架构图如下:
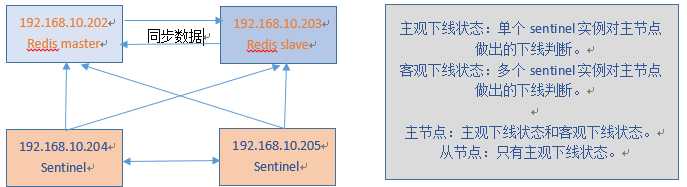
上图是一主一从节点,加上两个部署了sentinel的集群,sentinel集群之间会互相通信,沟通交流redis节点的状态,做出相应的判断并进行处理,这里的主观下线状态和客观下线状态是比较重要的状态,它们决定了是否进行故障转移
可以 通过订阅指定的频道信息,当服务器出现故障得时候通知管理员
客户端可以将 Sentinel 看作是一个只提供了订阅功能的 Redis 服务器,你不可以使用 PUBLISH 命令向这个服务器发送信息,但你可以用 SUBSCRIBE 命令或者 PSUBSCRIBE 命令, 通过订阅给定的频道来获取相应的事件提醒。 一个频道能够接收和这个频道的名字相同的事件。 比如说, 名为 +sdown 的频道就可以接收所有实例进入主观下线(SDOWN)状态的事件。
个人认为,Sentinel实现的最主要的一个功能就是能做到自动故障迁移,即当某一个master挂了的时候,可以自动的将某一个slave提升为新的master,且原master的所有slave也都自动的将自己的master改为新提升的master,这样我们的程序的可用性大大提高了。只要redis安装完成,Sentinel就安装完成了,Sentinel集成在redis里了。
Sentinel支持集群(可以部署在多台机器上,也可以在一台物理机上通过多端口实现伪集群部署)
很显然,只使用单个sentinel进程来监控redis集群是不可靠的,当sentinel进程宕掉后(sentinel本身也有单点问题,single-point-of-failure)整个集群系统将无法按照预期的方式运行。所以有必要将sentinel集群,这样有几个好处:
1)即使有一些sentinel进程宕掉了,依然可以进行redis集群的主备切换;
2)如果只有一个sentinel进程,如果这个进程运行出错,或者是网络堵塞,那么将无法实现redis集群的主备切换(单点问题);
3)如果有多个sentinel,redis的客户端可以随意地连接任意一个sentinel来获得关于redis集群中的信息。
sentinel集群注意事项
1)只有Sentinel 集群中大多数服务器认定master主观下线时master才会被认定为客观下线,才可以进行故障迁移,也就是说,即使不管我们在sentinel monitor中设置的数是多少,就算是满足了该值,只要达不到大多数,就不会发生故障迁移。
2)官方建议sentinel至少部署三台,且分布在不同机器。这里主要考虑到sentinel的可用性,假如我们只部署了两台sentinel,且quorum设置为1,也可以实现自动故障迁移,但假如其中一台sentinel挂了,就永远不会触发自动故障迁移,因为永远达不到大多数sentinel认定master主观下线了。
3)sentinel monitor配置中的master IP尽量不要写127.0.0.1或localhost,因为客户端,如jedis获取master是根据这个获取的,若这样配置,jedis获取的ip则是127.0.0.1,这样就可能导致程序连接不上master
4)当sentinel 启动后会自动的修改sentinel.conf文件,如已发现的master的slave信息,和集群中其它sentinel 的信息等,这样即使重启sentinel也能保持原来的状态。注意,当集群服务器调整时,如更换sentinel的机器,或者新配置一个sentinel,请不要直接复制原来运行过得sentinel配置文件,因为其里面自动生成了以上说的那些信息,我们应该复制一个新的配置文件或者把自动生成的信息给删掉。
5)当发生故障迁移的时候,master的变更记录与slave更换master的修改会自动同步到redis的配置文件,这样即使重启redis也能保持变更后的状态。
每个 Sentinel 都需要定期执行的任务
每个 Sentinel 以每秒钟一次的频率向它所知的主服务器、从服务器以及其他 Sentinel 实例发送一个 PING 命令。
如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 那么这个实例会被 Sentinel 标记为主观下线。 一个有效回复可以是: +PONG 、 -LOADING 或者 -MASTERDOWN 。
如果一个主服务器被标记为主观下线, 那么正在监视这个主服务器的所有 Sentinel 要以每秒一次的频率确认主服务器的确进入了主观下线状态。
如果一个主服务器被标记为主观下线, 并且有足够数量的 Sentinel (至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断, 那么这个主服务器被标记为客观下线。
在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有主服务器和从服务器发送 INFO 命令。 当一个主服务器被 Sentinel 标记为客观下线时, Sentinel 向下线主服务器的所有从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
当没有足够数量的 Sentinel 同意主服务器已经下线, 主服务器的客观下线状态就会被移除。 当主服务器重新向 Sentinel 的PING 命令返回有效回复时, 主服务器的主管下线状态就会被移除。
Sentinel之间和Slaves之间的自动发现机制
虽然sentinel集群中各个sentinel都互相连接彼此来检查对方的可用性以及互相发送消息。但是你不用在任何一个sentinel配置任何其它的sentinel的节点。因为sentinel利用了master的发布/订阅机制去自动发现其它也监控了统一master的sentinel节点。
通过向名为__sentinel__:hello的管道中发送消息来实现。
同样,你也不需要在sentinel中配置某个master的所有slave的地址,sentinel会通过询问master来得到这些slave的地址的。
每个sentinel通过向每个master和slave的发布/订阅频道__sentinel__:hello每秒发送一次消息,来宣布它的存在。
每个sentinel也订阅了每个master和slave的频道__sentinel__:hello的内容,来发现未知的sentinel,当检测到了新的sentinel,则将其加入到自身维护的master监控列表中。
每个sentinel发送的消息中也包含了其当前维护的最新的master配置。如果某个sentinel发现
自己的配置版本低于接收到的配置版本,则会用新的配置更新自己的master配置。
在为一个master添加一个新的sentinel前,sentinel总是检查是否已经有sentinel与新的sentinel的进程号或者是地址是一样的。如果是那样,这个sentinel将会被删除,而把新的sentinel添加上去。
sentinel和redis身份验证
当一个master配置为需要密码才能连接时,客户端和slave在连接时都需要提供密码。
master通过requirepass设置自身的密码,不提供密码无法连接到这个master。
slave通过masterauth来设置访问master时的密码。
但是当使用了sentinel时,由于一个master可能会变成一个slave,一个slave也可能会变成master,所以需要同时设置上述两个配置项。
Sentinel API
在默认情况下, Sentinel 使用 TCP 端口 26379 (普通 Redis 服务器使用的是 6379 )。Sentinel 接受 Redis 协议格式的命令请求, 所以你可以使用 redis-cli 或者任何其他 Redis 客户端来与 Sentinel 进行通讯。有两种方式可以和 Sentinel 进行通讯:
1)是通过直接发送命令来查询被监视 Redis 服务器的当前状态, 以及 Sentinel 所知道的关于其他 Sentinel 的信息, 诸如此类。
2)是使用发布与订阅功能, 通过接收 Sentinel 发送的通知: 当执行故障转移操作, 或者某个被监视的服务器被判断为主观下线或者客观下线时, Sentinel 就会发送相应的信息。
Sentinel命令(即登录到sentinel节点后执行的命令,比如执行"redis-cli -h 192.168.10.203 -p 26379"命令后,才可以执行下面命令)
PING :返回 PONG 。
SENTINEL masters :列出所有被监视的主服务器,以及这些主服务器的当前状态;
SENTINEL slaves <master name> :列出给定主服务器的所有从服务器,以及这些从服务器的当前状态;
SENTINEL get-master-addr-by-name <master name> : 返回给定名字的主服务器的 IP 地址和端口号。 如果这个主服务器正在执行故障转移操作, 或者针对这个主服务器的故障转移操作已经完成, 那么这个命令返回新的主服务器的 IP 地址和端口号;
SENTINEL reset <pattern> : 重置所有名字和给定模式 pattern 相匹配的主服务器。 pattern 参数是一个 Glob 风格的模式。 重置操作清楚主服务器目前的所有状态, 包括正在执行中的故障转移, 并移除目前已经发现和关联的, 主服务器的所有从服务器和 Sentinel ;
SENTINEL failover <master name> : 当主服务器失效时, 在不询问其他 Sentinel 意见的情况下, 强制开始一次自动故障迁移。 (不过发起故障转移的 Sentinel 会向其他 Sentinel 发送一个新的配置,其他 Sentinel 会根据这个配置进行相应的更新)
SENTINEL MONITOR <name> <ip> <port> <quorum> 这个命令告诉sentinel去监听一个新的master
SENTINEL REMOVE <name> 命令sentinel放弃对某个master的监听
SENTINEL SET <name> <option> <value> 这个命令很像Redis的CONFIG SET命令,用来改变指定master的配置。支持多个<option><value>。例如以下实例:SENTINEL SET objects-cache-master down-after-milliseconds 1000
只要是配置文件中存在的配置项,都可以用SENTINEL SET命令来设置。这个还可以用来设置master的属性,比如说quorum(票数),而不需要先删除master,再重新添加master。例如:SENTINEL SET objects-cache-master quorum 5
客户端可以通过SENTINEL get-master-addr-by-name <master name>获取当前的主服务器IP地址和端口号,以及SENTINEL slaves <master name>获取所有的Slaves信息。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
[root@redis-master ~]# redis-cli -h 192.168.10.202 -p 6379 INFO|grep rolerole:slave[root@redis-master ~]# redis-cli -h 192.168.10.203 -p 6379 INFO|grep rolerole:slave[root@redis-master ~]# redis-cli -h 192.168.10.205 -p 6379 INFO|grep rolerole:master登录任意一个节点的sentinel,进行相关命令的操作(下面命令例子中的redisMaster是sentinel监控redis主从状态时定义的master名称)1)sentinel masters 罗列所有sentinel 监视相关的master[root@redis-master ~]# redis-cli -h 192.168.10.205 -p 26379 192.168.10.205:26379> sentinel masters 2)sentinel master masterName 列出一个master相关的的信息[root@redis-master ~]# redis-cli -h 192.168.10.205 -p 26379 192.168.10.205:26379> sentinel master redisMaster3)sentinel slaves masterName 列出一个master相应的slave组相关的数据[root@redis-master ~]# redis-cli -h 192.168.10.205 -p 26379 192.168.10.205:26379> sentinel slaves redisMaster4)sentinel sentinels masterName 列出master相关的sentinels组其他相关的信息[root@redis-master ~]# redis-cli -h 192.168.10.205 -p 26379 192.168.10.205:26379> sentinel sentinels redisMaster5)sentinel get-master-addr-by-name masterName 获取master-name相关的 ip addr 的信息[root@redis-master ~]# redis-cli -h 192.168.10.205 -p 26379 192.168.10.205:26379> sentinel get-master-addr-by-name redisMaster1) "192.168.10.205"2) "6379" |
增加或删除Sentinel
由于有sentinel自动发现机制,所以添加一个sentinel到你的集群中非常容易,你所需要做的只是监控到某个Master上,然后新添加的sentinel就能获得其他sentinel的信息以及master所有的slaves。
如果你需要添加多个sentinel,建议你一个接着一个添加,这样可以预防网络隔离带来的问题。你可以每个30秒添加一个sentinel。最后你可以用SENTINEL MASTER mastername来检查一下是否所有的sentinel都已经监控到了master。
删除一个sentinel显得有点复杂:因为sentinel永远不会删除一个已经存在过的sentinel,即使它已经与组织失去联系很久了。
要想删除一个sentinel,应该遵循如下步骤:
1)停止所要删除的sentinel
2)发送一个SENTINEL RESET * 命令给所有其它的sentinel实例,如果你想要重置指定master上面的sentinel,只需要把*号改为特定的名字,注意,需要一个接一个发,每次发送的间隔不低于30秒。
3)检查一下所有的sentinels是否都有一致的当前sentinel数。使用SENTINEL MASTER mastername 来查询。
删除旧master或者不可达slave
sentinel永远会记录好一个Master的slaves,即使slave已经与组织失联好久了。这是很有用的,因为sentinel集群必须有能力把一个恢复可用的slave进行重新配置。
并且,failover后,失效的master将会被标记为新master的一个slave,这样的话,当它变得可用时,就会从新master上复制数据。
然后,有时候你想要永久地删除掉一个slave(有可能它曾经是个master),你只需要发送一个SENTINEL RESET master命令给所有的sentinels,它们将会更新列表里能够正确地复制master数据的slave。
发布与订阅信息(sentinel的日志文件里可以看到这些信息)
客户端可以将 Sentinel 看作是一个只提供了订阅功能的 Redis 服务器: 你不可以使用 PUBLISH 命令向这个服务器发送信息, 但你可以用 SUBSCRIBE 命令或者 PSUBSCRIBE 命令, 通过订阅给定的频道来获取相应的事件提醒。
一个频道能够接收和这个频道的名字相同的事件。 比如说, 名为 +sdown 的频道就可以接收所有实例进入主观下线(SDOWN)状态的事件。
通过执行 "PSUBSCRIBE * "命令可以接收所有事件信息(即订阅所有消息)。
以下列出的是客户端可以通过订阅来获得的频道和信息的格式: 第一个英文单词是频道/事件的名字, 其余的是数据的格式。
注意, 当格式中包含 instance details 字样时, 表示频道所返回的信息中包含了以下用于识别目标实例的内容.
以下是所有可以收到的消息的消息格式,如果你订阅了所有消息的话。第一个单词是频道的名字,其它是数据的格式。
注意:以下的instance details的格式是:
<instance-type> <name> <ip> <port> @ <master-name> <master-ip> <master-port>
如果这个redis实例是一个master,那么@之后的消息就不会显示。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
+reset-master <instance details> -- 当master被重置时. +slave <instance details> -- 当检测到一个slave并添加进slave列表时. +failover-state-reconf-slaves <instance details> -- Failover状态变为reconf-slaves状态时 +failover-detected <instance details> -- 当failover发生时 +slave-reconf-sent <instance details> -- sentinel发送SLAVEOF命令把它重新配置时 +slave-reconf-inprog <instance details> -- slave被重新配置为另外一个master的slave,但数据复制还未发生时。 +slave-reconf-done <instance details> -- slave被重新配置为另外一个master的slave并且数据复制已经与master同步时。 -dup-sentinel <instance details> -- 删除指定master上的冗余sentinel时 (当一个sentinel重新启动时,可能会发生这个事件). +sentinel <instance details> -- 当master增加了一个sentinel时。 +sdown <instance details> -- 进入SDOWN状态时; -sdown <instance details> -- 离开SDOWN状态时。 +odown <instance details> -- 进入ODOWN状态时。 -odown <instance details> -- 离开ODOWN状态时。 +new-epoch <instance details> -- 当前配置版本被更新时。 +try-failover <instance details> -- 达到failover条件,正等待其他sentinel的选举。 +elected-leader <instance details> -- 被选举为去执行failover的时候。 +failover-state-select-slave <instance details> -- 开始要选择一个slave当选新master时。 no-good-slave <instance details> -- 没有合适的slave来担当新master selected-slave <instance details> -- 找到了一个适合的slave来担当新master failover-state-send-slaveof-noone <instance details> -- 当把选择为新master的slave的身份进行切换的时候。 failover-end-for-timeout <instance details> -- failover由于超时而失败时。 failover-end <instance details> -- failover成功完成时。 switch-master <master name> <oldip> <oldport> <newip> <newport> -- 当master的地址发生变化时。通常这是客户端最感兴趣的消息了。 +tilt -- 进入Tilt模式。 -tilt -- 退出Tilt模式。 |
可以看出,使用Sentinel命令和发布订阅两种机制就能很好的实现和客户端的集成整合:
使用get-master-addr-by-name和slaves指令可以获取当前的Master和Slaves的地址和信息;而当发生故障转移时,即Master发生切换,可以通过订阅的+switch-master事件获得最新的Master信息。
sentinel.conf中的notification-script
在sentinel.conf中可以配置多个sentinel notification-script <master name> <shell script-path>, 如sentinel notification-script mymaster ./check.sh
这个是在群集failover时会触发执行指定的脚本。脚本的执行结果若为1,即稍后重试(最大重试次数为10);若为2,则执行结束。并且脚本最大执行时间为60秒,超时会被终止执行。
目前会存在该脚本被执行多次的问题,网上查找资料获得的解释是:脚本分为两个级别, SENTINEL_LEADER 和 SENTINEL_OBSERVER ,前者仅由领头 Sentinel 执行(一个 Sentinel),而后者由监视同一个 master 的所有 Sentinel 执行(多个 Sentinel)。
无failover时的配置纠正
即使当前没有failover正在进行,sentinel依然会使用当前配置去设置监控的master。特别是:
1)根据最新配置确认为slaves的节点却声称自己是master(上文例子中被网络隔离后的的redis3),这时它们会被重新配置为当前master的slave。
2)如果slaves连接了一个错误的master,将会被改正过来,连接到正确的master。
Slave选举与优先级
当一个sentinel准备好了要进行failover,并且收到了其他sentinel的授权,那么就需要选举出一个合适的slave来做为新的master。
slave的选举主要会评估slave的以下几个方面:
1)与master断开连接的次数
2)Slave的优先级
3)数据复制的下标(用来评估slave当前拥有多少master的数据)
4)进程ID
如果一个slave与master失去联系超过10次,并且每次都超过了配置的最大失联时间(down-after-milliseconds),如果sentinel在进行failover时发现slave失联,那么这个slave就会被sentinel认为不适合用来做新master的。
更严格的定义是,如果一个slave持续断开连接的时间超过
(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state
就会被认为失去选举资格。
符合上述条件的slave才会被列入master候选人列表,并根据以下顺序来进行排序:
1)sentinel首先会根据slaves的优先级来进行排序,优先级越小排名越靠前。
2)如果优先级相同,则查看复制的下标,哪个从master接收的复制数据多,哪个就靠前。
3)如果优先级和下标都相同,就选择进程ID较小的那个。
一个redis无论是master还是slave,都必须在配置中指定一个slave优先级。要注意到master也是有可能通过failover变成slave的。
如果一个redis的slave优先级配置为0,那么它将永远不会被选为master。但是它依然会从master哪里复制数据。
故障转移
所谓故障转移就是当master宕机,选一个合适的slave来晋升为master的操作,redis-sentinel会自动完成这个,不需要我们手动来实现。
一次故障转移操作大致分为以下流程:
发现主服务器已经进入客观下线状态。
对我们的当前集群进行自增, 并尝试在这个集群中当选。
如果当选失败, 那么在设定的故障迁移超时时间的两倍之后, 重新尝试当选。 如果当选成功, 那么执行以下步骤:
选出一个从服务器,并将它升级为主服务器。
向被选中的从服务器发送 SLAVEOF NO ONE 命令,让它转变为主服务器。
通过发布与订阅功能, 将更新后的配置传播给所有其他 Sentinel , 其他 Sentinel 对它们自己的配置进行更新。
向已下线主服务器的从服务器发送 SLAVEOF 命令, 让它们去复制新的主服务器。
当所有从服务器都已经开始复制新的主服务器时, 领头 Sentinel 终止这次故障迁移操作。
每当一个 Redis 实例被重新配置(reconfigured) —— 无论是被设置成主服务器、从服务器、又或者被设置成其他主服务器的从服务器 —— Sentinel 都会向被重新配置的实例发送一个 CONFIG REWRITE 命令, 从而确保这些配置会持久化在硬盘里。
Sentinel 使用以下规则来选择新的主服务器:
在失效主服务器属下的从服务器当中, 那些被标记为主观下线、已断线、或者最后一次回复 PING 命令的时间大于五秒钟的从服务器都会被淘汰。
在失效主服务器属下的从服务器当中, 那些与失效主服务器连接断开的时长超过 down-after 选项指定的时长十倍的从服务器都会被淘汰。
在经历了以上两轮淘汰之后剩下来的从服务器中, 我们选出复制偏移量(replication offset)最大的那个从服务器作为新的主服务器; 如果复制偏移量不可用, 或者从服务器的复制偏移量相同, 那么带有最小运行 ID 的那个从服务器成为新的主服务器。
Sentinel 自动故障迁移的一致性特质
Sentinel 自动故障迁移使用 Raft 算法来选举领头(leader) Sentinel , 从而确保在一个给定的纪元(epoch)里, 只有一个领头产生。
这表示在同一个纪元中, 不会有两个 Sentinel 同时被选中为领头, 并且各个 Sentinel 在同一个纪元中只会对一个领头进行投票。
更高的配置纪元总是优于较低的纪元, 因此每个 Sentinel 都会主动使用更新的纪元来代替自己的配置。
简单来说, 可以将 Sentinel 配置看作是一个带有版本号的状态。 一个状态会以最后写入者胜出(last-write-wins)的方式(也即是,最新的配置总是胜出)传播至所有其他 Sentinel 。
举个例子, 当出现网络分割(network partitions)时, 一个 Sentinel 可能会包含了较旧的配置, 而当这个 Sentinel 接到其他 Sentinel 发来的版本更新的配置时, Sentinel 就会对自己的配置进行更新。
如果要在网络分割出现的情况下仍然保持一致性, 那么应该使用 min-slaves-to-write 选项, 让主服务器在连接的从实例少于给定数量时停止执行写操作, 与此同时, 应该在每个运行 Redis 主服务器或从服务器的机器上运行 Redis Sentinel 进程。
Sentinel 状态的持久化
Sentinel 的状态会被持久化在 Sentinel 配置文件里面。每当 Sentinel 接收到一个新的配置, 或者当领头 Sentinel 为主服务器创建一个新的配置时, 这个配置会与配置纪元一起被保存到磁盘里面。这意味着停止和重启 Sentinel 进程都是安全的。
Sentinel 在非故障迁移的情况下对实例进行重新配置
即使没有自动故障迁移操作在进行, Sentinel 总会尝试将当前的配置设置到被监视的实例上面。 特别是:
根据当前的配置, 如果一个从服务器被宣告为主服务器, 那么它会代替原有的主服务器, 成为新的主服务器, 并且成为原有主服务器的所有从服务器的复制对象。
那些连接了错误主服务器的从服务器会被重新配置, 使得这些从服务器会去复制正确的主服务器。
不过, 在以上这些条件满足之后, Sentinel 在对实例进行重新配置之前仍然会等待一段足够长的时间, 确保可以接收到其他 Sentinel 发来的配置更新, 从而避免自身因为保存了过期的配置而对实例进行了不必要的重新配置。
总结来说,故障转移分为三个步骤:
1)从下线的主服务的所有从服务里面挑选一个从服务,将其转成主服务
sentinel状态数据结构中保存了主服务的所有从服务信息,领头sentinel按照如下的规则从从服务列表中挑选出新的主服务;
删除列表中处于下线状态的从服务;
删除最近5秒没有回复过领头sentinel info信息的从服务;
删除与已下线的主服务断开连接时间超过 down-after-milliseconds*10毫秒的从服务,这样就能保留从的数据比较新(没有过早的与主断开连接);
领头sentinel从剩下的从列表中选择优先级高的,如果优先级一样,选择偏移量最大的(偏移量大说明复制的数据比较新),如果偏移量一样,选择运行id最小的从服务。
2)已下线主服务的所有从服务改为复制新的主服务
挑选出新的主服务之后,领头sentinel 向原主服务的从服务发送 slaveof 新主服务 的命令,复制新master。
3)将已下线的主服务设置成新的主服务的从服务,当其回复正常时,复制新的主服务,变成新的主服务的从服务
同理,当已下线的服务重新上线时,sentinel会向其发送slaveof命令,让其成为新主的从。
温馨提示:还可以向任意sentinel发生sentinel failover <masterName> 进行手动故障转移,这样就不需要经过上述主客观和选举的过程。
sentinel.conf文件配置参数解释
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
1)sentinel monitor mymaster 192.168.10.202 6379 2Sentine监听的maste地址,第一个参数是给master起的名字,第二个参数为master IP,第三个为master端口,第四个为当该master挂了的时候,若想将该master判为失效,在Sentine集群中必须至少2个Sentine同意才行,只要该数量不达标,则就不会发生故障迁移。也就是说只要有2个sentinel认为master下线,就认为该master客观下线,启动failover并选举产生新的master。通常最后一个参数不能多于启动的sentinel实例数。这个配置是sentinel需要监控的master/slaver信息,格式为sentinel monitor <mastername> <masterIP> <masterPort> <quorum> 其中<quorum>应该小于集群中slave的个数,当失效的节点数超过了<quorum>,则认为整个体系结构失效 不过要注意, 无论你设置要多少个 Sentinel 同意才能判断一个服务器失效, 一个 Sentinel 都需要获得系统中多数(majority) Sentinel 的支持, 才能发起一次自动故障迁移,并预留一个给定的配置纪元 (configuration Epoch ,一个配置纪元就是一个新主服务器配置的版本号)。 换句话说, 在只有少数(minority) Sentinel 进程正常运作的情况下, Sentinel 是不能执行自动故障迁移的。 -----------------------------------------------------------------------------------------------2)sentinel down-after-milliseconds mymaster 30000表示master被当前sentinel实例认定为失效的间隔时间。master在多长时间内一直没有给Sentine返回有效信息,则认定该master主观下线。也就是说如果多久没联系上redis-servevr,认为这个redis-server进入到失效(SDOWN)状态。 如果服务器在给定的毫秒数之内, 没有返回 Sentinel 发送的 PING 命令的回复, 或者返回一个错误, 那么 Sentinel 将这个服务器标记为主观下线(subjectively down,简称 SDOWN )。不过只有一个 Sentinel 将服务器标记为主观下线并不一定会引起服务器的自动故障迁移: 只有在足够数量的 Sentinel 都将一个服务器标记为主观下线之后, 服务器才会被标记为客观下线(objectively down, 简称 ODOWN ), 这时自动故障迁移才会执行。将服务器标记为客观下线所需的 Sentinel 数量由对主服务器的配置决定。-----------------------------------------------------------------------------------------------3)sentinel parallel-syncs mymaster 2当在执行故障转移时,设置几个slave同时进行切换master,该值越大,则可能就有越多的slave在切换master时不可用,可以将该值设置为1,即一个一个来,这样在某个slave进行切换master同步数据时,其余的slave还能正常工作,以此保证每次只有一个从服务器处于不能处理命令请求的状态。 parallel-syncs 选项指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步, 这个数字越小, 完成故障转移所需的时间就越长。 如果从服务器被设置为允许使用过期数据集(参见对 redis.conf 文件中对 slave-serve-stale-data 选项的说明), 那么你可能不希望所有从服务器都在同一时间向新的主服务器发送同步请求,因为尽管复制过程的绝大部分步骤都不会阻塞从服务器, 但从服务器在载入主服务器发来的 RDB 文件时, 仍然会造成从服务器在一段时间内不能处理命令请求: 如果全部从服务器一起对新的主服务器进行同步, 那么就可能会造成所有从服务器在短时间内全部不可用的情况出现。当新master产生时,同时进行"slaveof"到新master并进行"SYNC"的slave个数。 默认为1,建议保持默认值 在salve执行salveof与同步时,将会终止客户端请求。 此值较大,意味着"集群"终止客户端请求的时间总和和较大。 此值较小,意味着"集群"在故障转移期间,多个salve向客户端提供服务时仍然使用旧数据。 -----------------------------------------------------------------------------------------------4)sentinel can-failover mymaster yes在sentinel检测到O_DOWN后,是否对这台redis启动failover机制-----------------------------------------------------------------------------------------------5)sentinel auth-pass mymaster 20180408设置sentinel连接的master和slave的密码,这个需要和redis.conf文件中设置的密码一样-----------------------------------------------------------------------------------------------6)sentinel failover-timeout mymaster 180000failover过期时间,当failover开始后,在此时间内仍然没有触发任何failover操作,当前sentinel将会认为此次failoer失败。 执行故障迁移超时时间,即在指定时间内没有大多数的sentinel 反馈master下线,该故障迁移计划则失效-----------------------------------------------------------------------------------------------7)sentinel config-epoch mymaster 0选项指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步。这个数字越小, 完成故障转移所需的时间就越长。-----------------------------------------------------------------------------------------------8)sentinel notification-script mymaster /var/redis/notify.sh当failover时,可以指定一个"通知"脚本用来告知当前集群的情况。脚本被允许执行的最大时间为60秒,如果超时,脚本将会被终止(KILL)-----------------------------------------------------------------------------------------------9)sentinel leader-epoch mymaster 0同时一时间最多0个slave可同时更新配置,建议数字不要太大,以免影响正常对外提供服务。 |
基于以上细节知识梳理,总结出sentinel的工作原理
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
首先要能理解SDOWN和ODOWN这两个词的含义,上面已经详细介绍了它们俩。在此再提一下:SDOWN:subjectively down,直接翻译的为"主观"失效,即当前sentinel实例认为某个redis服务为"不可用"状态.ODOWN:objectively down,直接翻译为"客观"失效,即多个sentinel实例都认为master处于"SDOWN"状态,那么此时master将处于ODOWN,ODOWN可以简单理解为master已经被集群确定为"不可用",将会开启failover.SDOWN适合于master和slave,但是ODOWN只会使用于master;当slave失效超过"down-after-milliseconds"后,那么所有sentinel实例都会将其标记为"SDOWN"。1) SDOWN与ODOWN转换过程:每个sentinel实例在启动后,都会和已知的slaves/master以及其他sentinels建立TCP连接,并周期性发送PING(默认为1秒)在交互中,如果redis-server无法在"down-after-milliseconds"时间内响应或者响应错误信息,都会被认为此redis-server处于SDOWN状态。如果SDOWN的server为master,那么此时sentinel实例将会向其他sentinel间歇性(一秒)发送"is-master-down-by-addr <ip> <port>"指令并获取响应信息,如果足够多的sentinel实例检测到master处于SDOWN,那么此时当前sentinel实例标记master为ODOWN...其他sentinel实例做同样的交互操作。配置项"sentinel monitor <mastername> <masterip> <masterport> <quorum>",如果检测到master处于SDOWN状态的slave个数达到<quorum>,那么此时此sentinel实例将会认为master处于ODOWN。每个sentinel实例将会间歇性(10秒)向master和slaves发送"INFO"指令,如果master失效且没有新master选出时,每1秒发送一次"INFO";"INFO"的主要目的就是获取并确认当前集群环境中slaves和master的存活情况。经过上述过程后,所有的sentinel对master失效达成一致后,开始failover.2) Sentinel与slaves"自动发现"机制:在sentinel的配置文件中(local-sentinel.conf),都指定了port,此port就是sentinel实例侦听其他sentinel实例建立链接的端口.在集群稳定后,最终会每个sentinel实例之间都会建立一个tcp链接,此链接中发送"PING"以及类似于"is-master-down-by-addr"指令集,可用用来检测其他sentinel实例的有效性以及"ODOWN"和"failover"过程中信息的交互.在sentinel之间建立连接之前,sentinel将会尽力和配置文件中指定的master建立连接.sentinel与master的连接中的通信主要是基于pub/sub来发布和接收信息,发布的信息内容包括当前sentinel实例的侦听端口:+sentinel sentinel 127.0.0.1:26579 127.0.0.1 26579 .... 发布的主题名称为"__sentinel__:hello";同时sentinel实例也是"订阅"此主题,以获得其他sentinel实例的信息.由此可见,环境首次构建时,在默认master存活的情况下,所有的sentinel实例可以通过pub/sub即可获得所有的sentinel信息,此后每个sentinel实例即可以根据+sentinel信息中的"ip+port"和其他sentinel逐个建立tcp连接即可.不过需要提醒的是,每个sentinel实例均会间歇性(5秒)向"__sentinel__:hello"主题中发布自己的ip+port,目的就是让后续加入集群的sentinel实例也能或得到自己的信息。根据上文,我们知道在master有效的情况下,即可通过"INFO"指令获得当前master中已有的slave列表;此后任何slave加入集群,master都会向"主题中"发布"+slave 127.0.0.1:6579 ..",那么所有的sentinel也将立即获得slave信息,并和slave建立链接并通过PING检测其存活性.补充一下,每个sentinel实例都会保存其他sentinel实例的列表以及现存的master/slaves列表,各自的列表中不会有重复的信息(不可能出现多个tcp连接),对于sentinel将使用ip+port做唯一性标记,对于master/slaver将使用runid做唯一性标记,其中redis-server的runid在每次启动时都不同.3) Leader选举:其实在sentinels故障转移中,仍然需要一个"Leader"来调度整个过程:master的选举以及slave的重配置和同步。当集群中有多个sentinel实例时,如何选举其中一个sentinel为leader呢?在配置文件中"can-failover""quorum"参数,以及"is-master-down-by-addr"指令配合来完成整个过程。A) "can-failover"用来表明当前sentinel是否可以参与"failover"过程,如果为"YES"则表明它将有能力参与"Leader"的选举,否则它将作为"Observer",observer参与leader选举投票但不能被选举;B) "quorum"不仅用来控制master ODOWN状态确认,同时还用来选举leader时最小"赞同票"数;C) "is-master-down-by-addr",它可以用来检测"ip + port"的master是否已经处于SDOWN状态,不过此指令不仅能够获得master是否处于SDOWN,同时它还额外的返回当前sentinel本地"投票选举"的Leader信息(runid);每个sentinel实例都持有其他的sentinels信息,在Leader选举过程中(当为leader的sentinel实例失效时,有可能master server并没失效,注意分开理解),sentinel实例将从所有的sentinels集合中去除"can-failover = no"和状态为SDOWN的sentinels,在剩余的sentinels列表中按照runid按照"字典"顺序排序后,取出runid最小的sentinel实例,并将它"投票选举"为Leader,并在其他sentinel发送的"is-master-down-by-addr"指令时将推选的runid追加到响应中。每个sentinel实例都会检测"is-master-down-by-addr"的响应结果,如果"投票选举"的leader为自己,且状态正常的sentinels实例中,"赞同者"的自己的sentinel个数不小于(>=) 50% + 1,且不小与<quorum>,那么此sentinel就会认为选举成功且leader为自己。在sentinel.conf文件中,我们期望有足够多的sentinel实例配置"can-failover yes",这样能够确保当leader失效时,能够选举某个sentinel为leader,以便进行failover。如果leader无法产生,比如较少的sentinels实例有效,那么failover过程将无法继续.4) failover过程:在Leader触发failover之前,首先wait数秒(随即0~5),以便让其他sentinel实例准备和调整(有可能多个leader??),如果一切正常,那么leader就需要开始将一个salve提升为master,此slave必须为状态良好(不能处于SDOWN/ODOWN状态)且权重值最低(redis.conf中)的,当master身份被确认后,开始failoverA)"+failover-triggered": Leader开始进行failover,此后紧跟着"+failover-state-wait-start",wait数秒。B)"+failover-state-select-slave": Leader开始查找合适的slaveC)"+selected-slave": 已经找到合适的slaveD) "+failover-state-sen-slaveof-noone": Leader向slave发送"slaveof no one"指令,此时slave已经完成角色转换,此slave即为masterE) "+failover-state-wait-promotition": 等待其他sentinel确认slaveF)"+promoted-slave":确认成功G)"+failover-state-reconf-slaves": 开始对slaves进行reconfig操作。H)"+slave-reconf-sent":向指定的slave发送"slaveof"指令,告知此slave跟随新的masterI)"+slave-reconf-inprog": 此slave正在执行slaveof + SYNC过程,如过slave收到"+slave-reconf-sent"之后将会执行slaveof操作。J)"+slave-reconf-done": 此slave同步完成,此后leader可以继续下一个slave的reconfig操作。循环G)K)"+failover-end": 故障转移结束L)"+switch-master":故障转移成功后,各个sentinel实例开始监控新的master。 |
二、redis sentinel 主从切换(failover)的容灾环境部署记录
redis主从复制简单来说:
A)Redis的复制功能是支持多个数据库之间的数据同步。一类是主数据库(master)一类是从数据库(slave),主数据库可以进行读写操作,当发生写操作的时候自动将数据同步到从数据库,而从数据库一般是只读的,并接收主数据库同步过来的数据,一个主数据库可以有多个从数据库,而一个从数据库只能有一个主数据库。
B)通过redis的复制功能可以很好的实现数据库的读写分离,提高服务器的负载能力。主数据库主要进行写操作,而从数据库负责读操作。
Redis主从复制流程简图
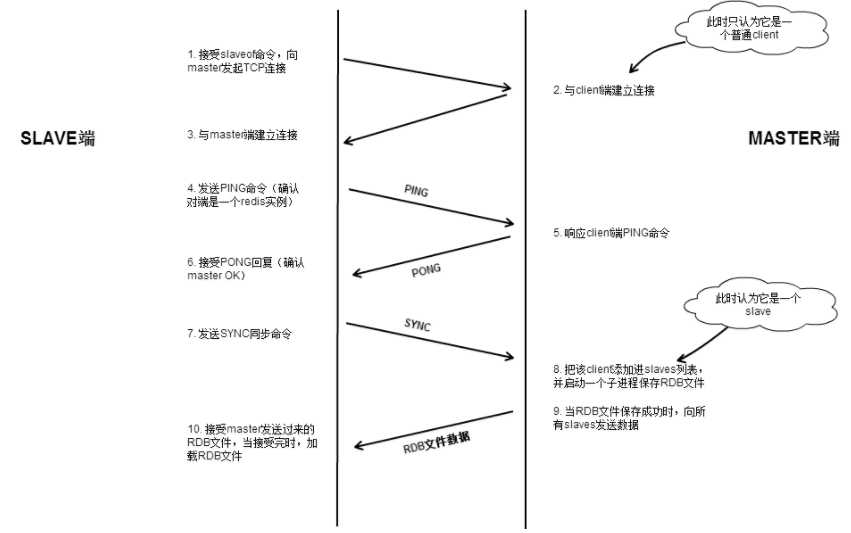
redis主从复制的大致过程:
1)当一个从数据库启动时,会向主数据库发送sync命令,
2)主数据库接收到sync命令后会开始在后台保存快照(执行rdb操作),并将保存期间接收到的命令缓存起来
3)当快照完成后,redis会将快照文件和所有缓存的命令发送给从数据库。
4)从数据库收到后,会载入快照文件并执行收到的缓存的命令。
注意:redis2.8之前的版本:当主从数据库同步的时候从数据库因为网络原因断开重连后会重新执行上述操作,不支持断点续传。redis2.8之后支持断点续传。
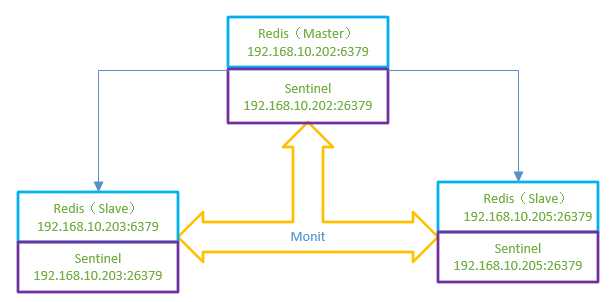
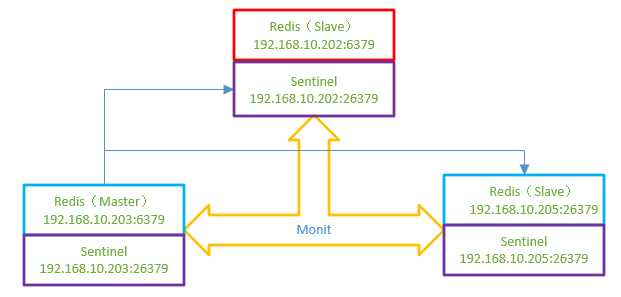
0)Redis主从结构支持一主多从+n个sentinel模式,信息如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
192.168.10.202 redis-master redis(6379)、sentinel(26379)192.168.10.203 redis-slave01 redis(6379)、sentinel(26379)192.168.10.205 redis-slave02 redis(6379)、sentinel(26379) 关闭三个节点机器的iptables和selinux(所有节点机器上都要操作)[root@redis-master ~]# /etc/init.d/iptables stop[root@redis-master ~]# vim /etc/sysconfig/selinux......SELINUX=disabled[root@redis-master ~]# setenforce 0[root@redis-master ~]# getenforcePermissive 注意:本案例采用1主2从+3 sentinel的集群模式,所有从节点的配置都一样。 |
a)redis服务器上各自存在一个Sentinel,监控本机redis的运行情况,并通知给闭路环上其它的redis节点;
b)当master发生异常(例如:宕机和断电等)导致不可运行时,Sentinel将通知给其它节点,而剩余节点上的Sentinel将重新选举出新的master,而原来的master重新恢复正常后,则一直扮演slave角色;
c)规定整个架构体系中,master提供读写服务,而slave只提供读取服务。
1)redis一键安装(三个节点上都要操作)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
[root@redis-master ~]# cd /usr/local/src/[root@redis-master src]# vim install_redis.sh #!/usr/bin/env bash# It‘s Used to be install redis.# Created on 2018/04/08 11:18.# @author: wangshibo.# Version: 1.0 function install_redis () {################################################################################################# cd /usr/local/src if [ ! -f " redis-4.0.1.tar.gz" ]; then wget http://download.redis.io/releases/redis-4.0.1.tar.gz fi cd /usr/local/src tar -zxvf /usr/local/src/redis-4.0.1.tar.gz cd redis-4.0.1 make PREFIX=/usr/local/redis install mkdir -p /usr/local/redis/{etc,var} rsync -avz redis.conf /usr/local/redis/etc/ sed -i ‘s@pidfile.*@pidfile /var/run/redis-server.pid@‘ /usr/local/redis/etc/redis.conf sed -i "s@logfile.*@logfile /usr/local/redis/var/redis.log@" /usr/local/redis/etc/redis.conf sed -i "s@^dir.*@dir /usr/local/redis/var@" /usr/local/redis/etc/redis.conf sed -i ‘s/daemonize no/daemonize yes/g‘ /usr/local/redis/etc/redis.conf sed -i ‘s/^# bind 127.0.0.1/bind 0.0.0.0/g‘ /usr/local/redis/etc/redis.conf #################################################################################################} install_redis[root@redis-master src]# chmod 755 install_redis.sh[root@redis-master src]# sh -x install_redis.sh |
2)redis启停脚本(三个节点上都要操作)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
|
[root@redis-master src]# vim /etc/init.d/redis-server#!/bin/bash## redis - this script starts and stops the redis-server daemon## chkconfig: - 85 15# description: Redis is a persistent key-value database# processname: redis-server# config: /usr/local/redis/etc/redis.conf# config: /etc/sysconfig/redis# pidfile: /usr/local/redis/var/redis-server.pid # Source function library.. /etc/rc.d/init.d/functions # Source networking configuration.. /etc/sysconfig/network # Check that networking is up.[ "$NETWORKING" = "no" ] && exit 0 redis="/usr/local/redis/bin/redis-server"prog=$(basename $redis) REDIS_CONF_FILE="/usr/local/redis/etc/redis.conf" [ -f /etc/sysconfig/redis ] && . /etc/sysconfig/redis lockfile=/var/lock/subsys/redis-server start() { [ -x $redis ] || exit 5 [ -f $REDIS_CONF_FILE ] || exit 6 echo -n $"Starting $prog: " daemon $redis $REDIS_CONF_FILE retval=$? echo [ $retval -eq 0 ] && touch $lockfile return $retval} stop() { echo -n $"Stopping $prog: " killproc $prog retval=$? echo [ $retval -eq 0 ] && rm -f $lockfile return $retval} restart() { stop start} reload() { echo -n $"Reloading $prog: " killproc $redis -HUP RETVAL=$? echo} force_reload() { restart} rh_status() { status $prog} rh_status_q() { rh_status >/dev/null 2>&1} case "$1" in start) rh_status_q && exit 0 $1 ;; stop) rh_status_q || exit 0 $1 ;; restart) $1 ;; reload) rh_status_q || exit 7 $1 ;; force-reload) force_reload ;; status) rh_status ;; condrestart|try-restart) rh_status_q || exit 0 ;; *) echo $"Usage: $0 {start|stop|status|restart|condrestart|try-restart|reload|force-reload}" exit 2esac执行权限[root@redis-master src]# chmod 755 /etc/init.d/redis-server |
3)redis-sentinel启停脚本示例(三个节点上都要操作)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
|
[root@redis-master src]# vim /etc/init.d/redis-sentinel#!/bin/bash## redis-sentinel - this script starts and stops the redis-server sentinel daemon## chkconfig: - 85 15# description: Redis sentinel# processname: redis-server# config: /usr/local/redis/etc/sentinel.conf# config: /etc/sysconfig/redis# pidfile: /usr/local/redis/var/redis-sentinel.pid # Source function library.. /etc/rc.d/init.d/functions # Source networking configuration.. /etc/sysconfig/network # Check that networking is up.[ "$NETWORKING" = "no" ] && exit 0 redis="/usr/local/redis/bin/redis-sentinel"prog=$(basename $redis) REDIS_CONF_FILE="/usr/local/redis/etc/sentinel.conf" [ -f /etc/sysconfig/redis ] && . /etc/sysconfig/redis lockfile=/var/lock/subsys/redis-sentinel start() { [ -x $redis ] || exit 5 [ -f $REDIS_CONF_FILE ] || exit 6 echo -n $"Starting $prog: " daemon $redis $REDIS_CONF_FILE --sentinel retval=$? echo [ $retval -eq 0 ] && touch $lockfile return $retval} stop() { echo -n $"Stopping $prog: " killproc $prog retval=$? echo [ $retval -eq 0 ] && rm -f $lockfile return $retval} restart() { stop start} reload() { echo -n $"Reloading $prog: " killproc $redis -HUP RETVAL=$? echo} force_reload() { restart} rh_status() { status $prog} rh_status_q() { rh_status >/dev/null 2>&1} case "$1" in start) rh_status_q && exit 0 $1 ;; stop) rh_status_q || exit 0 $1 ;; restart) $1 ;; reload) rh_status_q || exit 7 $1 ;; force-reload) force_reload ;; status) rh_status ;; condrestart|try-restart) rh_status_q || exit 0 ;; *) echo $"Usage: $0 {start|stop|status|restart|condrestart|try-restart|reload|force-reload}" exit 2esac执行权限:[root@redis-master src]# chmod 755 /etc/init.d/redis-sentinel |
4)配置redis.conf
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
|
a)编辑redis-master主节点的redis.conf文件[root@redis-master src]# mkdir -p /usr/local/redis/data/redis[root@redis-master src]# cp /usr/local/redis/etc/redis.conf /usr/local/redis/etc/redis.conf.bak[root@redis-master src]# vim /usr/local/redis/etc/redis.confbind 0.0.0.0daemonize yespidfile "/usr/local/redis/var/redis-server.pid"port 6379tcp-backlog 128timeout 0tcp-keepalive 0loglevel noticelogfile "/usr/local/redis/var/redis-server.log"databases 16save 900 1 save 300 10save 60 10000stop-writes-on-bgsave-error yesrdbcompression yesrdbchecksum yesdbfilename dump.rdbdir "/usr/local/redis/data/redis"#masterauth "20180408" #master设置密码保护,即slave连接master时的密码#requirepass "20180408" #设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH <password>命令提供密码,默认关闭slave-serve-stale-data yesslave-read-only yesrepl-diskless-sync norepl-diskless-sync-delay 5repl-disable-tcp-nodelay noslave-priority 100appendonly yes #打开aof持久化appendfilename "appendonly.aof"appendfsync everysec # 每秒一次aof写no-appendfsync-on-rewrite noauto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mbaof-load-truncated yeslua-time-limit 5000slowlog-log-slower-than 10000slowlog-max-len 128latency-monitor-threshold 0notify-keyspace-events ""hash-max-ziplist-entries 512hash-max-ziplist-value 64list-max-ziplist-entries 512list-max-ziplist-value 64set-max-intset-entries 512zset-max-ziplist-entries 128zset-max-ziplist-value 64hll-sparse-max-bytes 3000activerehashing yesclient-output-buffer-limit normal 0 0 0client-output-buffer-limit slave 256mb 64mb 60client-output-buffer-limit pubsub 32mb 8mb 60hz 10aof-rewrite-incremental-fsync yes注意:上面配置中masterauth和requirepass表示设置密码保护,如果设置了密码,则连接redis后需要执行"auth 20180408"密码后才能操作其他命令。这里我不设置密码。b)编辑redis-slave01和redis-slave02两个从节点的redis.conf文件[root@redis-slave01 src]# mkdir -p /usr/local/redis/data/redis[root@redis-slave01 src]# cp /usr/local/redis/etc/redis.conf /usr/local/redis/etc/redis.conf.bak[root@redis-slave01 src]# vim /usr/local/redis/etc/redis.confbind 0.0.0.0daemonize yespidfile "/usr/local/redis/var/redis-server.pid"port 6379tcp-backlog 128timeout 0tcp-keepalive 0loglevel noticelogfile "/usr/local/redis/var/redis-server.log"databases 16save 900 1 save 300 10save 60 10000stop-writes-on-bgsave-error yesrdbcompression yesrdbchecksum yesdbfilename dump.rdbdir "/usr/local/redis/data/redis"#masterauth "20180408" #requirepass "20180408" slaveof 192.168.10.202 6379 #相对主redis配置,多添加了此行 slave-serve-stale-data yesslave-read-only yes #从节点只读,不能写入repl-diskless-sync norepl-diskless-sync-delay 5repl-disable-tcp-nodelay noslave-priority 100appendonly yes appendfilename "appendonly.aof"appendfsync everysec no-appendfsync-on-rewrite noauto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mbaof-load-truncated yeslua-time-limit 5000slowlog-log-slower-than 10000slowlog-max-len 128latency-monitor-threshold 0notify-keyspace-events ""hash-max-ziplist-entries 512hash-max-ziplist-value 64list-max-ziplist-entries 512list-max-ziplist-value 64set-max-intset-entries 512zset-max-ziplist-entries 128zset-max-ziplist-value 64hll-sparse-max-bytes 3000activerehashing yesclient-output-buffer-limit normal 0 0 0client-output-buffer-limit slave 256mb 64mb 60client-output-buffer-limit pubsub 32mb 8mb 60hz 10aof-rewrite-incremental-fsync yes |
5)配置sentinel.conf(这个默认没有,需要自建)。三个节点的配置一样。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@redis-master src]# mkdir -p /usr/local/redis/data/sentinel[root@redis-master src]# vim /usr/local/redis/etc/sentinel.confport 26379pidfile "/usr/local/redis/var/redis-sentinel.pid"dir "/usr/local/redis/data/sentinel"daemonize yesprotected-mode nologfile "/usr/local/redis/var/redis-sentinel.log"sentinel monitor redisMaster 192.168.10.202 6379 2 sentinel down-after-milliseconds redisMaster 10000 sentinel parallel-syncs redisMaster 1 sentinel failover-timeout redisMaster 60000 |
6)启动redis和sentinel(三个节点都要操作)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
设置系统变量[root@redis-slave02 src]# vim /etc/profile.......export PATH=$PATH:/usr/local/redis/bin[root@redis-slave02 src]# source /etc/profile启动redis和sentinel[root@redis-master src]# /etc/init.d/redis-server startStarting redis-server: [ OK ][root@redis-master src]# /etc/init.d/redis-sentinel startStarting redis-sentinel: [ OK ][root@redis-master src]# lsof -i:6379COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEredis-ser 2297 root 6u IPv4 7819726 0t0 TCP *:6379 (LISTEN)redis-ser 2297 root 8u IPv4 7819778 0t0 TCP 192.168.10.202:6379->192.168.10.202:56226 (ESTABLISHED)redis-ser 2297 root 9u IPv4 7819780 0t0 TCP 192.168.10.202:6379->192.168.10.202:56228 (ESTABLISHED)redis-sen 2315 root 8u IPv4 7819777 0t0 TCP 192.168.10.202:56226->192.168.10.202:6379 (ESTABLISHED)redis-sen 2315 root 9u IPv4 7819779 0t0 TCP 192.168.10.202:56228->192.168.10.202:6379 (ESTABLISHED)[root@redis-master src]# lsof -i:26379COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEredis-sen 2315 root 6u IPv6 7819772 0t0 TCP *:26379 (LISTEN)redis-sen 2315 root 7u IPv4 7819773 0t0 TCP *:26379 (LISTEN) |
7)查看redis和sentinel信息
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
|
1)查看三个节点的redis的主从关系[root@redis-master src]# redis-cli -h 192.168.10.202 -p 6379 INFO|grep rolerole:master[root@redis-master src]# redis-cli -h 192.168.10.203 -p 6379 INFO|grep rolerole:slave[root@redis-master src]# redis-cli -h 192.168.10.205 -p 6379 INFO|grep rolerole:slave 从上面信息可以看出,192.168.10.202是master,192.168.10.203和192.168.10.205是slave 2)查看Master节点信息:[root@redis-master src]# redis-cli -h 192.168.10.202 -p 6379 info Replication# Replicationrole:masterconnected_slaves:2slave0:ip=192.168.10.203,port=6379,state=online,offset=61480,lag=0slave1:ip=192.168.10.205,port=6379,state=online,offset=61480,lag=0master_replid:96a1fd63d0ad9e7903851a82382e32d690667bccmaster_replid2:0000000000000000000000000000000000000000master_repl_offset:61626second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:61626 从上面信息看出,此时192.168.10.202的角色为master,有两个slave(203和205)被连接成功. 此时打开master的sentinel.conf,在末尾可看到如下自动写入的内容:[root@redis-master src]# cat /usr/local/redis/etc/sentinel.confport 26379pidfile "/usr/local/redis/var/redis-sentinel.pid"dir "/usr/local/redis/data/sentinel"daemonize yesprotected-mode nologfile "/usr/local/redis/var/redis-sentinel.log"sentinel myid c165761901b5ea3cd2d622bbf13f4c99eb73c1bcsentinel monitor redisMaster 192.168.10.202 6379 2sentinel down-after-milliseconds redisMaster 10000sentinel failover-timeout redisMaster 60000# Generated by CONFIG REWRITEsentinel config-epoch redisMaster 0sentinel leader-epoch redisMaster 0sentinel known-slave redisMaster 192.168.10.203 6379sentinel known-slave redisMaster 192.168.10.205 6379sentinel known-sentinel redisMaster 192.168.10.205 26379 cc25d5f0e37803e888732d63deae3761c9f91e1dsentinel known-sentinel redisMaster 192.168.10.203 26379 e1505ffc65f787871febfde2f27b762f70cddd71sentinel current-epoch 0 [root@redis-master ~]# redis-cli -h 192.168.10.205 -p 26379 info Sentinel# Sentinelsentinel_masters:1sentinel_tilt:0sentinel_running_scripts:0sentinel_scripts_queue_length:0sentinel_simulate_failure_flags:0master0:name=redisMaster,status=ok,address=192.168.10.202:6379,slaves=2,sentinels=33)查看Slave节点信息: 先查看salve01节点信息[root@redis-slave01 src]# redis-cli -h 192.168.10.203 -p 6379 info Replication# Replicationrole:slavemaster_host:192.168.10.202master_port:6379master_link_status:upmaster_last_io_seconds_ago:0master_sync_in_progress:0slave_repl_offset:96744slave_priority:100slave_read_only:1connected_slaves:0master_replid:96a1fd63d0ad9e7903851a82382e32d690667bccmaster_replid2:0000000000000000000000000000000000000000master_repl_offset:96744second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:96744 此时192.168.10.203的角色为slave,它们所属的master为220。此时打开slave的sentinel.conf,在末尾可看到如下自动写入的内容:[root@redis-slave01 src]# cat /usr/local/redis/etc/sentinel.confport 26379pidfile "/usr/local/redis/var/redis-sentinel.pid"dir "/usr/local/redis/data/sentinel"daemonize yesprotected-mode nologfile "/usr/local/redis/var/redis-sentinel.log"sentinel myid e1505ffc65f787871febfde2f27b762f70cddd71sentinel monitor redisMaster 192.168.10.202 6379 2sentinel down-after-milliseconds redisMaster 10000sentinel failover-timeout redisMaster 60000# Generated by CONFIG REWRITEsentinel config-epoch redisMaster 0sentinel leader-epoch redisMaster 0sentinel known-slave redisMaster 192.168.10.203 6379sentinel known-slave redisMaster 192.168.10.205 6379sentinel known-sentinel redisMaster 192.168.10.205 26379 cc25d5f0e37803e888732d63deae3761c9f91e1dsentinel known-sentinel redisMaster 192.168.10.202 26379 c165761901b5ea3cd2d622bbf13f4c99eb73c1bcsentinel current-epoch 0[root@redis-slave01 ~]# redis-cli -h 192.168.10.203 -p 26379 info Sentinel# Sentinelsentinel_masters:1sentinel_tilt:0sentinel_running_scripts:0sentinel_scripts_queue_length:0sentinel_simulate_failure_flags:0master0:name=redisMaster,status=ok,address=192.168.10.202:6379,slaves=2,sentinels=3同样查看slave02节点的信息[root@redis-slave02 src]# redis-cli -h 192.168.10.205 -p 6379 info Replication# Replicationrole:slavemaster_host:192.168.10.202master_port:6379master_link_status:upmaster_last_io_seconds_ago:0master_sync_in_progress:0slave_repl_offset:99678slave_priority:100slave_read_only:1connected_slaves:0master_replid:96a1fd63d0ad9e7903851a82382e32d690667bccmaster_replid2:0000000000000000000000000000000000000000master_repl_offset:99678second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:170repl_backlog_histlen:99509 [root@redis-slave02 src]# cat /usr/local/redis/etc/sentinel.confport 26379pidfile "/usr/local/redis/var/redis-sentinel.pid"dir "/usr/local/redis/data/sentinel"daemonize yesprotected-mode nologfile "/usr/local/redis/var/redis-sentinel.log"sentinel myid cc25d5f0e37803e888732d63deae3761c9f91e1dsentinel monitor redisMaster 192.168.10.202 6379 2sentinel down-after-milliseconds redisMaster 10000sentinel failover-timeout redisMaster 60000# Generated by CONFIG REWRITEsentinel config-epoch redisMaster 0sentinel leader-epoch redisMaster 0sentinel known-slave redisMaster 192.168.10.205 6379sentinel known-slave redisMaster 192.168.10.203 6379sentinel known-sentinel redisMaster 192.168.10.203 26379 e1505ffc65f787871febfde2f27b762f70cddd71sentinel known-sentinel redisMaster 192.168.10.202 26379 c165761901b5ea3cd2d622bbf13f4c99eb73c1bcsentinel current-epoch 0[root@redis-slave02 ~]# redis-cli -h 192.168.10.205 -p 26379 info Sentinel# Sentinelsentinel_masters:1sentinel_tilt:0sentinel_running_scripts:0sentinel_scripts_queue_length:0sentinel_simulate_failure_flags:0master0:name=redisMaster,status=ok,address=192.168.10.202:6379,slaves=2,sentinels=3 |
8)客户端写入测试数据
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
客户端连接master节点,写入一条数据[root@redis-master src]# redis-cli -h 192.168.10.202 -p 6379192.168.10.202:6379> set name kevin;OK192.168.10.202:6379> get name;"kevin";然后客户端再连接任意slave节点,通过get获取上面的那条数据[root@redis-master src]# redis-cli -h 192.168.10.203 -p 6379192.168.10.203:6379> get name"kevin;"192.168.10.203:6379> set name grace;(error) READONLY You can‘t write against a read only slave.192.168.10.203:6379> [root@redis-master src]# redis-cli -h 192.168.10.205 -p 6379192.168.10.205:6379> get name"kevin;"192.168.10.205:6379> set name grace;(error) READONLY You can‘t write against a read only slave.192.168.10.205:6379> 由上面测试信息可知,master节点可以写入,可以读取;而slave节点默认只能读取,不能写入!这就实现了主从复制,读写分离了! |
9)模拟故障(通过sentinel实现主从切换,sentinel也要部署多台,即集群模式,防止单台sentinel挂掉情况)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
|
1)关掉任意一个slave节点(比如关闭掉slave01节点),所有节点的sentinel都可以检测到,出现如下示例信息:[root@redis-master src]# redis-cli -h 192.168.10.203 -p 6379192.168.10.203:6379> get name"kevin;"192.168.10.203:6379> set name grace;(error) READONLY You can‘t write against a read only slave.192.168.10.203:6379> shutdown not connected> 说明:shutdown命令表示关闭redis从上可看出203被sentinel检测到已处于关闭状态,此时再来查看剩余节点的主从信息,它们的角色不会发生变化,只是master上的connected_slaves变为了1。[root@redis-master src]# redis-cli -h 192.168.10.202 -p 6379 info replication# Replicationrole:masterconnected_slaves:1slave0:ip=192.168.10.205,port=6379,state=online,offset=219376,lag=1master_replid:96a1fd63d0ad9e7903851a82382e32d690667bccmaster_replid2:0000000000000000000000000000000000000000master_repl_offset:219376second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:219376查看sentinel日志(任意节点上查看),发现203节点已经进入"+sdown"状态[root@redis-master src]# tail -f /usr/local/redis/var/redis-sentinel.log 2315:X 08 May 18:49:51.429 * Increased maximum number of open files to 10032 (it was originally set to 1024).2315:X 08 May 18:49:51.431 * Running mode=sentinel, port=26379.2315:X 08 May 18:49:51.431 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.2315:X 08 May 18:49:51.463 # Sentinel ID is c165761901b5ea3cd2d622bbf13f4c99eb73c1bc2315:X 08 May 18:49:51.463 # +monitor master redisMaster 192.168.10.202 6379 quorum 22315:X 08 May 18:50:11.544 * +slave slave 192.168.10.203:6379 192.168.10.203 6379 @ redisMaster 192.168.10.202 63792315:X 08 May 18:50:11.574 * +slave slave 192.168.10.205:6379 192.168.10.205 6379 @ redisMaster 192.168.10.202 63792315:X 08 May 18:50:15.088 * +sentinel sentinel e1505ffc65f787871febfde2f27b762f70cddd71 192.168.10.203 26379 @ redisMaster 192.168.10.202 63792315:X 08 May 18:50:16.075 * +sentinel sentinel cc25d5f0e37803e888732d63deae3761c9f91e1d 192.168.10.205 26379 @ redisMaster 192.168.10.202 63792315:X 08 May 19:06:07.669 # +sdown slave 192.168.10.203:6379 192.168.10.203 6379 @ redisMaster 192.168.10.202 6379然后重启上面被关闭的slave节点(即192.168.10.203),所有节点的sentinel都可以检测到,可看出221又被sentinel检测到已处于可用状态,此时再来查看节点的主从信息,它们的角色仍然不会发生变化,master上的connected_slaves又变为了2[root@redis-slave01 src]# /etc/init.d/redis-server restartStopping redis-server: [FAILED]Starting redis-server: [ OK ][root@redis-slave01 src]# /etc/init.d/redis-server restartStopping redis-server: [ OK ]Starting redis-server: [ OK ][root@redis-master src]# redis-cli -h 192.168.10.202 -p 6379 info replication# Replicationrole:masterconnected_slaves:2slave0:ip=192.168.10.205,port=6379,state=online,offset=268216,lag=0slave1:ip=192.168.10.203,port=6379,state=online,offset=268070,lag=1master_replid:96a1fd63d0ad9e7903851a82382e32d690667bccmaster_replid2:0000000000000000000000000000000000000000master_repl_offset:268216second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:268216查看sentinel日志(任意节点上查看),发现203节点已经进入"-sdown"状态[root@redis-master src]# tail -f /usr/local/redis/var/redis-sentinel.log 2315:X 08 May 18:49:51.429 * Increased maximum number of open files to 10032 (it was originally set to 1024).2315:X 08 May 18:49:51.431 * Running mode=sentinel, port=26379.2315:X 08 May 18:49:51.431 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.2315:X 08 May 18:49:51.463 # Sentinel ID is c165761901b5ea3cd2d622bbf13f4c99eb73c1bc2315:X 08 May 18:49:51.463 # +monitor master redisMaster 192.168.10.202 6379 quorum 22315:X 08 May 18:50:11.544 * +slave slave 192.168.10.203:6379 192.168.10.203 6379 @ redisMaster 192.168.10.202 63792315:X 08 May 18:50:11.574 * +slave slave 192.168.10.205:6379 192.168.10.205 6379 @ redisMaster 192.168.10.202 63792315:X 08 May 18:50:15.088 * +sentinel sentinel e1505ffc65f787871febfde2f27b762f70cddd71 192.168.10.203 26379 @ redisMaster 192.168.10.202 63792315:X 08 May 18:50:16.075 * +sentinel sentinel cc25d5f0e37803e888732d63deae3761c9f91e1d 192.168.10.205 26379 @ redisMaster 192.168.10.202 63792315:X 08 May 19:06:07.669 # +sdown slave 192.168.10.203:6379 192.168.10.203 6379 @ redisMaster 192.168.10.202 63792315:X 08 May 19:10:14.965 * +reboot slave 192.168.10.203:6379 192.168.10.203 6379 @ redisMaster 192.168.10.202 63792315:X 08 May 19:10:15.020 # -sdown slave 192.168.10.203:6379 192.168.10.203 6379 @ redisMaster 192.168.10.202 6379=======================================================================================================2)关掉master节点(即192.168.10.202),待所有节点的sentinel都检测到后(稍等一会,2-3秒钟时间),再来查看两个Slave节点的主从信息,发现其中一个节点的角色通过选举后会成为master节点了![root@redis-master src]# redis-cli -h 192.168.10.202 -p 6379192.168.10.202:6379> shutdownnot connected> 查看sentinel日志(任意节点上查看),发现202节点已经进入"+sdown"状态[root@redis-master src]# tail -f /usr/local/redis/var/redis-sentinel.log2315:X 08 May 19:17:03.722 # +failover-state-reconf-slaves master redisMaster 192.168.10.202 63792315:X 08 May 19:17:03.760 * +slave-reconf-sent slave 192.168.10.203:6379 192.168.10.203 6379 @ redisMaster 192.168.10.202 63792315:X 08 May 19:17:04.015 * +slave-reconf-inprog slave 192.168.10.203:6379 192.168.10.203 6379 @ redisMaster 192.168.10.202 63792315:X 08 May 19:17:04.459 # -odown master redisMaster 192.168.10.202 63792315:X 08 May 19:17:05.047 * +slave-reconf-done slave 192.168.10.203:6379 192.168.10.203 6379 @ redisMaster 192.168.10.202 63792315:X 08 May 19:17:05.131 # +failover-end master redisMaster 192.168.10.202 63792315:X 08 May 19:17:05.131 # +switch-master redisMaster 192.168.10.202 6379 192.168.10.205 63792315:X 08 May 19:17:05.131 * +slave slave 192.168.10.203:6379 192.168.10.203 6379 @ redisMaster 192.168.10.205 63792315:X 08 May 19:17:05.131 * +slave slave 192.168.10.202:6379 192.168.10.202 6379 @ redisMaster 192.168.10.205 63792315:X 08 May 19:17:15.170 # +sdown slave 192.168.10.202:6379 192.168.10.202 6379 @ redisMaster 192.168.10.205 6379[root@redis-slave01 src]# redis-cli -h 192.168.10.203 -p 6379 INFO|grep rolerole:slave[root@redis-slave01 src]# redis-cli -h 192.168.10.205 -p 6379 INFO|grep role role:master[root@redis-slave01 src]# redis-cli -h 192.168.10.205 -p 6379 info replication# Replicationrole:masterconnected_slaves:1slave0:ip=192.168.10.203,port=6379,state=online,offset=348860,lag=1master_replid:a51f87958cea0b1e8fe2c83542ca6cebace53bf7master_replid2:96a1fd63d0ad9e7903851a82382e32d690667bccmaster_repl_offset:349152second_repl_offset:342824repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:170repl_backlog_histlen:348983[root@redis-slave01 src]# redis-cli -h 192.168.10.203 -p 6379 info replication# Replicationrole:slavemaster_host:192.168.10.205master_port:6379master_link_status:upmaster_last_io_seconds_ago:0master_sync_in_progress:0slave_repl_offset:347546slave_priority:100slave_read_only:1connected_slaves:0master_replid:a51f87958cea0b1e8fe2c83542ca6cebace53bf7master_replid2:96a1fd63d0ad9e7903851a82382e32d690667bccmaster_repl_offset:347546second_repl_offset:342824repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:283207repl_backlog_histlen:64340由上可知,当master节点(即192.168.10.202)的redis关闭后,slave02节点(即192.168.10.205)变成了新的master节点,而slave01(即192.168.10.203)成为了slave02的从节点!192.168.10.205节点此时被选举为master,此时打开的205节点的redis.conf文件,slaveof配置项已被自动删除了。而203从节点的redis.conf文件中slaveof配置项的值被自动修改为192.168.10.205 6379。[root@redis-slave02 src]# cat /usr/local/redis/etc/redis.conf|grep slaveof[root@redis-slave01 src]# cat /usr/local/redis/etc/redis.conf|grep slaveofslaveof 192.168.10.205 6379在这个新master上(即192.168.10.205)执行诸如set这样的写入操作将被成功执行[root@redis-slave01 src]# redis-cli -h 192.168.10.205 -p 6379192.168.10.205:6379> set name beijing;OK[root@redis-master src]# redis-cli -h 192.168.10.203 -p 6379192.168.10.203:6379> get name"beijing;"192.168.10.203:6379> set name tianjin;(error) READONLY You can‘t write against a read only slave.192.168.10.203:6379> 重启192.168.10.202节点的redis,待所有节点的sentinel都检测到后,再来查看所有节点的主从信息,此时192.168.10.205节点的master角色不会被重新抢占,而192.168.10.202节点的角色会从原来的master变为了slave。[root@redis-master src]# /etc/init.d/redis-server restartStopping redis-server: [FAILED]Starting redis-server: [ OK ][root@redis-master src]# /etc/init.d/redis-server restartStopping redis-server: [ OK ]Starting redis-server: [ OK ][root@redis-master src]# redis-cli -h 192.168.10.202 -p 6379 INFO|grep rolerole:slave[root@redis-master src]# redis-cli -h 192.168.10.203 -p 6379 INFO|grep rolerole:slave[root@redis-master src]# redis-cli -h 192.168.10.205 -p 6379 INFO|grep rolerole:master[root@redis-master src]# redis-cli -h 192.168.10.205 -p 6379 info replication# Replicationrole:masterconnected_slaves:2slave0:ip=192.168.10.203,port=6379,state=online,offset=545410,lag=1slave1:ip=192.168.10.202,port=6379,state=online,offset=545410,lag=1master_replid:a51f87958cea0b1e8fe2c83542ca6cebace53bf7master_replid2:96a1fd63d0ad9e7903851a82382e32d690667bccmaster_repl_offset:545556second_repl_offset:342824repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:170repl_backlog_histlen:545387[root@redis-master src]# redis-cli -h 192.168.10.202 -p 6379192.168.10.202:6379> get name"beijing;"此时登录192.168.10.202节点的redis,执行"get name"得到的值为beijing,而不是原来的kevin,因为192.168.10.202节点的redis重启后会自动从新的master中同步数据。此时打开192.168.10.202节点的redis.conf文件,会在末尾找到如下信息:[root@redis-master src]# cat /usr/local/redis/etc/redis.conf|grep slaveofslaveof 192.168.10.205 6379到此,已经验证出了redis sentinel可以自行实现主从的故障切换了! |
10)客户端如何连接redis sentinel?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
|
客户端配置连接的是sentinel信息,比如连接sentinel.conf文件中定义的master名称。在sentinel监听时,当master节点挂了,它会在slave节点中自动选举出新的master节点,而当挂了的老master节点重新恢复后就会成为新的slave节点。对于客户端来说,redis主从切换后它不需要修改连接配置。下面列出几个客户端连接redis sentinel的例子1)java客户端在jedis中使用redis sentinel哨兵方式连接<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans"> <bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig"> <property name="maxTotal" value="1000"/> <property name="maxIdle" value="10"/> <property name="minIdle" value="1"/> <property name="maxWaitMillis" value="30000"/> <property name="testOnBorrow" value="true"/> <property name="testOnReturn" value="true"/> <property name="testWhileIdle" value="true"/> </bean> <bean id="cacheService" class="sentinel.CacheServiceImpl" destroy-method="destroy"> <property name="jedisSentinlePool"> <bean class="redis.clients.jedis.JedisSentinelPool"> <constructor-arg index="0" value="mymaster" /> <constructor-arg index="1"> <set> <value>192.168.10.202:26379</value> <value>192.168.10.203:26379</value> <value>192.168.10.205:26379</value> </set> </constructor-arg> <constructor-arg index="2" ref="jedisPoolConfig" /> </bean> </property> </bean></beans>2)python连接redis sentinel集群(需要安装python redis客户端,即执行"pip install redis")#!/usr/bin/env python# -*- coding:utf-8 -*-import redisfrom redis.sentinel import Sentinel# 连接哨兵服务器(主机名也可以用域名)sentinel = Sentinel([(‘192.168.10.202‘, 26379), (‘192.168.10.203‘, 26379), (‘192.168.10.205‘, 26379) ], socket_timeout=0.5)# 获取主服务器地址master = sentinel.discover_master(‘mymaster‘)print(master)# 输出:(‘192.168.10.202‘, 26379)# 获取从服务器地址slave = sentinel.discover_slaves(‘mymaster‘)print(slave)# 输出:[(‘192.168.10.203‘, 26379), (‘192.168.10.205‘, 26379), (‘172.31.0.5‘, 26379)]# 获取主服务器进行写入master = sentinel.master_for(‘mymaster‘, socket_timeout=0.5, password=‘redis_auth_pass‘, db=15)w_ret = master.set(‘foo‘, ‘bar‘)# 输出:True# # 获取从服务器进行读取(默认是round-roubin)slave = sentinel.slave_for(‘mymaster‘, socket_timeout=0.5, password=‘redis_auth_pass‘, db=15)r_ret = slave.get(‘foo‘)print(r_ret)# # 输出:bar3)Java客户端连接Redis(单sentinel).下面例子中好的redisMaster和20180408是在sentinel.conf中定义的master名称和连接密码package com.hiifit.cloudplatform.gaia.test;import java.util.HashSet;import java.util.Set;import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisSentinelPool;public class RedisSentinelTest { @SuppressWarnings("deprecation") public static void main(String[] args) { Set<String> sentinels = new HashSet<String>(); String hostAndPort1 = "192.168.10.205:26379"; sentinels.add(hostAndPort1); String clusterName = "redisMaster"; String password = "20180408"; JedisSentinelPool redisSentinelJedisPool = new JedisSentinelPool(clusterName,sentinels,password); Jedis jedis = null; try { jedis = redisSentinelJedisPool.getResource(); jedis.set("key", "value"); } catch (Exception e) { e.printStackTrace(); } finally { redisSentinelJedisPool.returnBrokenResource(jedis); } redisSentinelJedisPool.close(); }} |
---------------------
作者:散尽浮华
来源:CNBLOGS
原文:https://www.cnblogs.com/kevingrace/p/9004460.html
版权声明:本文为作者原创文章,转载请附上博文链接!
内容解析By:CSDN,CNBLOG博客文章一键转载插件
[转]Redis哨兵模式(sentinel)学习总结及部署记录(主从复制、读写分离、主从切换)
标签:自己的 load() col discover selected == 连通 自动 脚本
原文地址:https://www.cnblogs.com/admans/p/11623333.html