标签:int 获取 open string mic span 字符 pos log
响应对象的属性:
|
1
2
3
4
5
6
7
8
9
10
|
# 获取响应对象中的内容是str格式text# 获取响应对象中的内容是二进制格式的content# 获取响应状态码status_code# 获取响应头信息headers# 获取请求的urlurl |
import requests url = "https://www.cnblogs.com/songzhixue/p/10717975.html" # 获得一个响应对象 response = requests.get(url=url) # 调用响应对象中的text属性获取请求结果为字符串形式 print(response.text)
方式一:
import requests
url = "http://www.baidu.com/s?wd=周杰伦"
# requests模块可以自动将url中的汉字进行转码
response = requests.get(url).text
with open("./zhou.html","w",encoding="utf-8") as fp:
fp.write(response)
方式二:
将参数以字典的形式传给params参数

import requests
choice = input("请输入搜索条件>>>:").strip()
params = {
"wd":choice
}
# https://www.baidu.com/s?wd=周杰伦
url = "http://www.baidu.com/s?"
# 带参数的get请求
response = requests.get(url,params)
# 获取响应状态码
response.status_code
请求头以字典的方式传给headers参数
import requests
choice = input("请输入搜索条件>>>:").strip()
params = {
"wd":choice
}
# https://www.baidu.com/s?wd=周杰伦
url = "http://www.baidu.com/s?"
# 封装请求头信息
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36‘
}
# 带参数的get请求
response = requests.get(url,params,headers=headers)
# 获取响应状态码
response.status_code
豆瓣登录
开发者抓包工具抓取post请求的登录信息
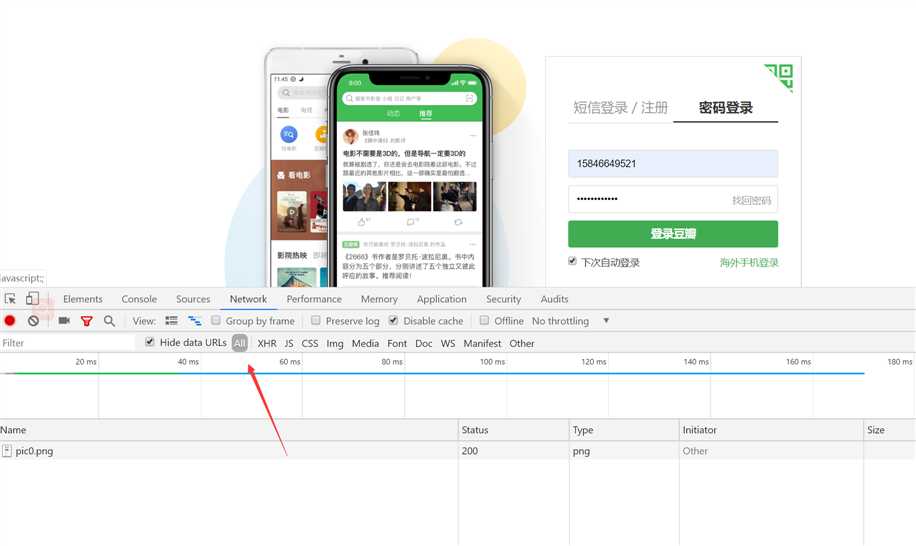
### 抓取豆瓣影评###
import json
import requests
# url = "https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20"
# 获取ajax的请求网址(基于ajax的get请求)
url = ‘https://movie.douban.com/j/search_subjects?‘
# 自定义请求头
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36‘,
}
# 构建请求参数
params = {
‘type‘: ‘movie‘,
‘tag‘: ‘热门‘,
‘sort‘: ‘recommend‘,
‘page_limit‘: ‘100‘, # 显示多少数据
‘page_start‘: ‘1‘, # 从第几页开始显示
}
# 请求目标url
response = requests.get(url=url,params=params,headers=headers)
# 拿到响应数据,json格式的字符串
json_str = response.text
# 对响应数据反序列化得到字典
code = json.loads(json_str)
# 在字典中取出想要的数据
for dic in code["subjects"]:
rate = dic["rate"]
title = dic["title"]
print(title,rate)
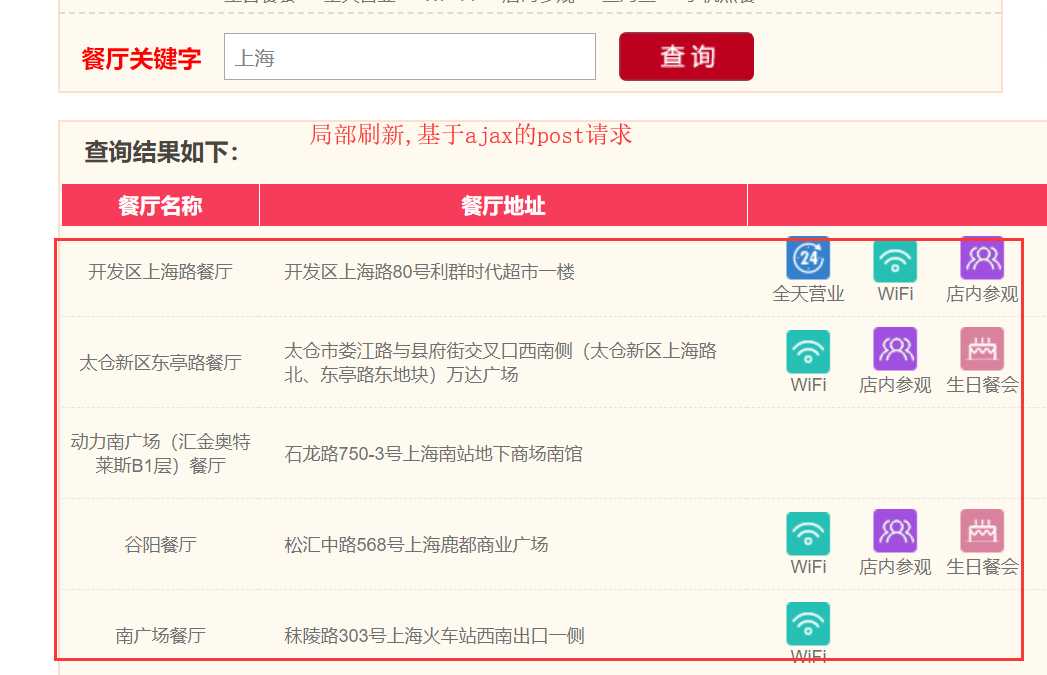
### 抓取肯德基餐厅位置信息###
import json
import requests
url = ‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘
data = {
‘cname‘: ‘‘,
‘pid‘: ‘‘,
‘keyword‘: ‘上海‘,# 查询城市
‘pageIndex‘:‘1‘, # 显示第几页的数据
‘pageSize‘: ‘10‘, # 一页显示多少数据
}
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36‘
}
response = requests.post(url=url,data=data,headers=headers)
response.text
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import requests# www.goubanjia.com# 快代理# 西祠代理url = "http://www.baidu.com/s?wd=ip"prox = { "http":"39.137.69.10:8080", "http":"111.13.134.22:80",}# 参数proxiesresponse = requests.get(url=url,proxies=prox).textwith open("./daili.html","w",encoding="utf-8") as fp: fp.write(response) print("下载成功") |
标签:int 获取 open string mic span 字符 pos log
原文地址:https://www.cnblogs.com/youxiu123/p/11624345.html