标签:根据 display ack 位置 定义 image 共同点 util 取值
---恢复内容开始---
Set接口是Collection接口的子接口,是一种不允许重复元素的集合。
LinkedHashSet是有序,不允许重复,允许加入NULL的集合。
它也是以HashCode值来决定元素的存储位置,同时还使用了链表来维护元素的顺序,这就使得它按照插入的顺序有序排列。相比Hashset多维护了链表,因此性能略低于HashSet。
TreeSet是有序,不允许重复,不允许NULL的集合。底层使用红黑树算法,擅长范围查询。
如果 this>obj ,返回1,
如果 this=obj ,返回0,
如果 this<obj ,返回-1。
通过该方法定义的规则比较之后,按照升序排列。
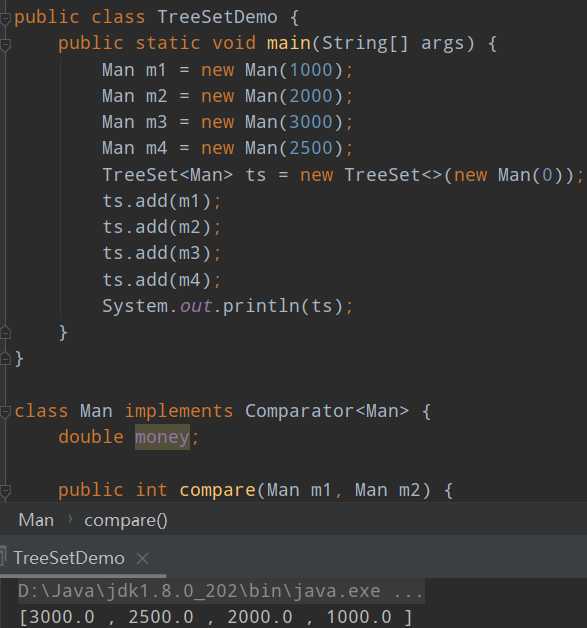
如下,按照money多少降序排列:

1 package com.vi.collection.set; 2 3 import java.util.Comparator; 4 import java.util.TreeSet; 5 6 public class TreeSetDemo { 7 public static void main(String[] args) { 8 Man m1 = new Man(1000); 9 Man m2 = new Man(2000); 10 Man m3 = new Man(3000); 11 Man m4 = new Man(2500); 12 TreeSet<Man> ts = new TreeSet<>(new Man(0)); 13 ts.add(m1); 14 ts.add(m2); 15 ts.add(m3); 16 ts.add(m4); 17 System.out.println(ts); 18 } 19 } 20 21 class Man implements Comparator<Man> { 22 double money; 23 24 public int compare(Man m1, Man m2) { 25 if (m2.money > m1.money) 26 return 1; 27 if (m2.money == m1.money) 28 return 0; 29 return -1; 30 } 31 32 public Man(double money) { 33 this.money = money; 34 } 35 36 public String toString(){ 37 return money+" "; 38 } 39 40 }
五、对以上三种Set进行比较
共同点:
1.都不允许存入重复值
2.都是线程不安全的(解决办法:使用Collections.synchronizedSet()方法)
不同点:
1.TreeSet不允许NULL值,HashSet和LinkedList可以存入空值
2.HashSet是无序的底层采用哈希表算法,查询效率高,通过equals()和hashCode()共同判断对象是否相等,即要求存入的对象重写equals()和hashCode()保持一致性;
LinkedList底层采用了哈希表和链表的结构,既保证了元素的添加顺序,也保证了查询效率,性能略低于HashSet;
TreeSet不保证元素的添加顺序,但是会按照自然排序或定制规则对集合中元素进行排序,底层采用了红黑树算法(树结构比较适合范围查询)。
标签:根据 display ack 位置 定义 image 共同点 util 取值
原文地址:https://www.cnblogs.com/blogforvi/p/11626793.html
