标签:完成 压缩文件 连续 pytho 随机数 空格 常用 保留 压缩
CSV:Comma-Separated Value,逗号分隔值文件 显示:表格状态 源文件:换行和逗号分隔行列的格式化文本,每一行的数据表示一条记录 由于csv便于展示,读取和写入,所以很多地方也是用csv的格式存储和传输中小型的数据,为了方便教学,我们会经常操作csv格式的文件,但是操作数据库中的数据也是很容易的实现的
加载数据:
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)
各参数以及解释:
fname:文件、字符串或产生器,可以是.gz或bz2压缩文件
dtype:数据类型,可选,CSV的字符串以什么数据类型读入数组中,默认np.float
delimiter:分割字符串,默认是任何空格,*改为逗号*
skiprows:跳过前x行,一般跳过第一行表头
usecols:读取指定的列,索引,元组类型
unpack:如果True,读入属性将分别写入不同数组变量,False读入数据只写入一个数组变量,默认False
numpy读取数据:
现在这里有一个英国和美国各自youtube1000多个视频的点击,喜欢,不喜欢,评论数量(["views","likes","dislikes","comment_total"])的csv,运用刚刚所学习的知识,我们尝试来对其进行操作 。(需要具体数据可以加Q:1259553287)
数据来源:https://www.kaggle.com/datasnaek/youtube/data
import numpy as np GB_data_path = "F:\BaiduNetdiskDownload\youtube_video_data\GB_video_data_numbers.csv" #加载文件,读取数据为数组(unpack默认False,只写入一个数组变量) #参数一文件路径,参数二,逗号分割,参数三数据类型,参数四读入属性分别写入不同变量 t2 = np.loadtxt(GB_data_path,delimiter=",",dtype="int") """ delimiter:指定边界符号是什么,不指定会导致数据为一个整体的字符串而报错 dtype:默认情况下对数值大的数据会变为科学计数的方式 unpack:默认是False,默认情况下有多少条数据就会有多少行 True(1)的情况下,每一行数据会组成一行,原始数据有多少列,加载出来的数据就会有多少行 相当于转置的效果 """ print(t2)
转置是一种变换,对于numpy中的数组来说,就是在对角线方向交换数据,目的也是为了更方便的去处理数据
#numpy的转置 t2.T t2.transpose() t2.swapaxes(1,0) #上面三种方法效果一样的
那么,结合之前的所学的matplotlib把英国和美国的数据呈现出来?
看到这个问题,我们应该考虑什么?
我们想要反映出什么样的结果,解决什么问题?
选择什么样的呈现方式?
数据还需要做什么样的处理?
写代码
接下来需要对数据进行相关操作:
对于刚刚加载出来的数据,我如果只想选择其中的某一列(行)我们应该怎么做呢? 其实操作很简单,和python中列表的操作一样。
import numpy as np t1 = np.arange(12).reshape(3,4) print(t1) #取行 print(t1[2],t1[1],t1[0]) #取连续的多行 print(t1[1:]) #取不连续的多列 print(t2[:,[0,2]]) #取不连续的多行 print(t1[[0,2]]) print(t1[1,1:]) print(t1[:,1]) #取多个不相邻的点 #选出来的结果是(0,0)(2,2) print(t1[[0,2],[0,2]])
t1[1:]=0
修改行列的值,我们能够很容易的实现,但是如果条件更复杂呢?
比如我们想要把t中小于6的数字替换为3如下操作。
t1<6
t1[t1<6]=3
那么问题来了:
如果我们想把t中小于6的数字替换为0,把大于6的替换为9,应该怎么做??
np.where(t1<6,0,9)
那么问题来了:
如果我们想把t中小于6的数字替换为0,把大于9的替换为1,应该怎么做??
t1.clip(6,9)
上面的操作:
小于6的替换为6,大于9的替换为了9,注意nan不会被替换,那么nan是什么?
nan(NAN,Nan):not a number表示不是一个数字
什么时候numpy中会出现nan:
当我们读取本地的文件为float的时候,如果有缺失,就会出现nan 当做了一个不合适的计算的时候(比如无穷大(inf)减去无穷大)
inf(-inf,inf):infinity,inf表示正无穷,-inf表示负无穷,什么时候回出现inf包括(-inf,+inf)比如一个数字除以0,(python中直接会报错,numpy中是一个inf或者-inf)
那么如何指定一个nan或者inf呢?注意他们的type类型
numpy中的nan的注意点:
1、两个nan是不相等的 np.nan==np.nan(False)
2、np.nan != np.nan
3、利用以上特性,可以判断数组中nan的个数 np.count_nonzero(t1 != t1)
4、由于2,那么如何判断一个数字是否为nan呢?通过np.isnan(a)来判断,返回bool类型比如希望把nan替换为0 t[np.isnan(t)] = 0
5、nan和任何值计算都为nan
那么问题来了,在一组数据中单纯的把nan替换为0,合适么?会带来什么样的影响? 比如,全部替换为0后,替换之前的平均值如果大于0,替换之后的均值肯定会变小,所以更一般的方式是把缺失的数值替换为均值(中值)或者是直接删除有缺失值的一行 那么问题来了: 如何计算一组数据的中值或者是均值 如何删除有缺失数据的那一行(列)[在pandas中介绍]
求和:t1.sum(axis=None)
均值:t1.mean(a,axis=None)受离群点的影响较大
中值:np.median(t,axis=None)
最大值:t1.max(axis=None)
最小值:t1.min(axis=None)
极值:np.ptp(t1,axis=None)即最大值和最小值之差
标准差:t1.std(axis=None)(
标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值 反映出数据的波动稳定情况,越大表示波动越大,约不稳定
)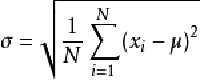
默认返回多维数组的全部的统计结果,如果指定axis则返回一个当前轴上的结果
t1中存在nan值,如何操作把其中的nan填充为每一列的均值
t = array([[ 0., 1., 2., 3., 4., 5.],
[ 6., 7., nan, 9., 10., 11.],
[ 12., 13., 14., nan, 16., 17.],
[ 18., 19., 20., 21., 22., 23.]])

小结
如何选择一行或者多行的数据(列)?
如何给选取的行或者列赋值?
如何大于把大于10的值替换为10?
np.where如何使用? np.clip如何使用?
如何转置(交换轴)?
读取和保存数据为csv np.nan和np.inf是什么?
常用的统计函数你记得几个?
标准差反映出数据的什么信息?
英国和美国各自youtube1000的数据结合之前的matplotlib绘制出各自的评论数量的直方图
(只需要绘制一个国家就可以知道另一个怎么绘制,绘制直方图需要确定组距,并计算出组数)
刚开始绘制所有评论数发现评论数大部分处于5000以下,因此我们应该取5000以下的绘制,并重新估计组距
import numpy as np from matplotlib import pyplot as plt plt.rc("font",family="SimHei",) GB_data_path = "F:\BaiduNetdiskDownload\youtube_video_data\GB_video_data_numbers.csv" #加载文件,读取数据为数组(unpack默认False,只写入一个数组变量) #参数一文件路径,参数二,逗号分割,参数三数据类型,参数四读入属性分别写入不同变量 t2 = np.loadtxt(GB_data_path,delimiter=",",dtype="int") """ 点击、喜欢、不喜欢,评论数量 """ print(t2) t3 = t2[:,-1] t3 = t3[t3<5000] print(t3) d = 100 sum_bins = (t3.max()-t3.min())//d print(t3.max(),t3.min()) plt.figure(figsize=(20,8),dpi=80) plt.hist(t3,sum_bins,) plt.xlabel("评论数量") plt.ylabel("评论数量的视频数") plt.title("评论数量分布直方图") plt.show()
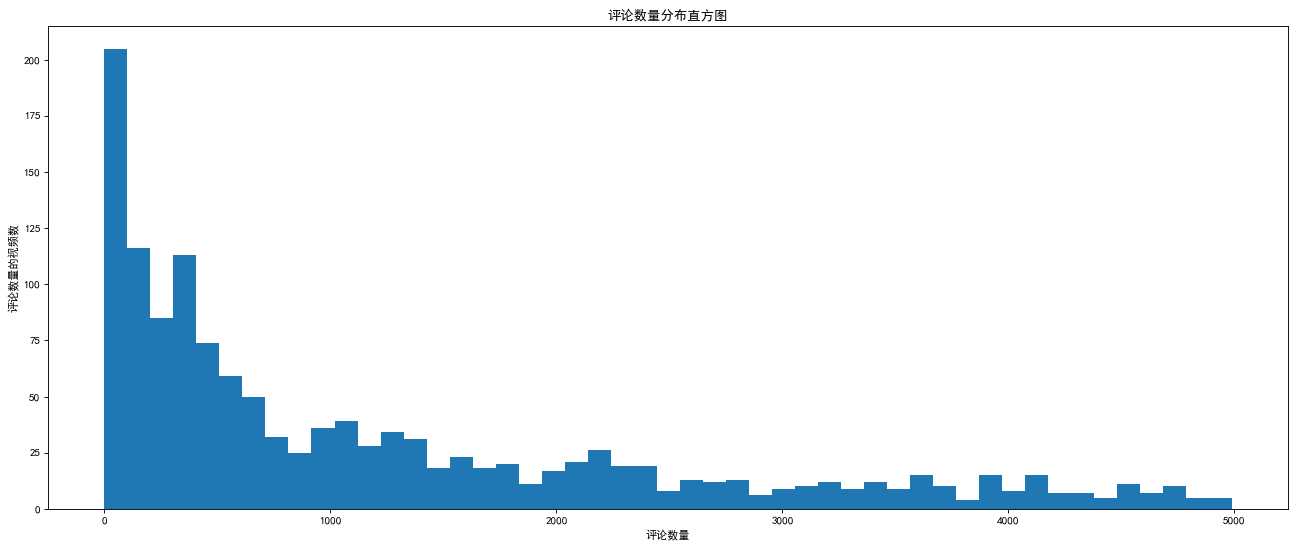
备注:如果组数除不尽,会出现到后面网格不整齐的现象
希望了解英国的youtube中视频的评论数和喜欢数的关系,应该如何绘制改图
(分析:我们只需要做出来一个的就可以将另一个完成,需要了解评论数和喜欢数的关系,当要看出谁与谁的关系的时候,那么散点图可以更好地看出两变量之间的关系!!!)
import numpy as np from matplotlib import pyplot as plt plt.rc("font",family="SimHei",) GB_data_path = "F:\BaiduNetdiskDownload\youtube_video_data\GB_video_data_numbers.csv" #加载文件,读取数据为数组(unpack默认False,只写入一个数组变量) #参数一文件路径,参数二,逗号分割,参数三数据类型,参数四读入属性分别写入不同变量 t2 = np.loadtxt(GB_data_path,delimiter=",",dtype="int") """ 点击、喜欢、不喜欢,评论数量 """ print(t2) #选择出喜欢数小于500000的全部数据 all_data =t2[t2[:,1]<=500000] #获取评论数 content = all_data[:,-1] like = all_data[:,1] plt.figure(figsize=(15,6),dpi=100) plt.scatter(content,like) plt.xlabel("评论数") plt.ylabel("喜欢数") plt.title("评论与喜欢之间的关系图") plt.show()
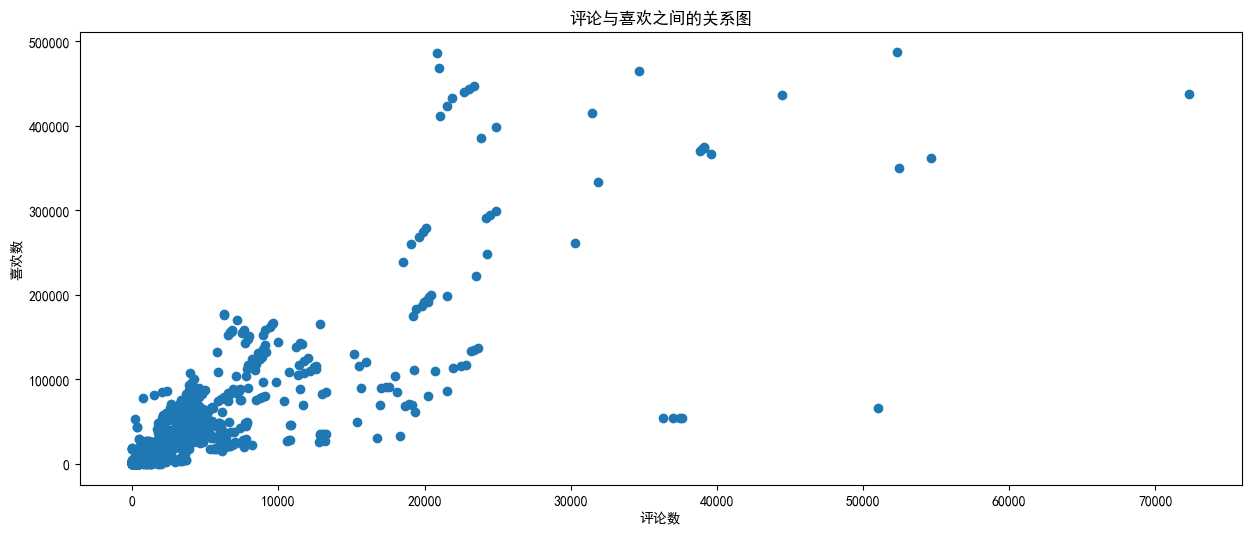
可以看出评论数增加喜欢数也在增加。
现在我希望把之前案例中两个国家的数据方法一起来研究分析,那么应该怎么做?
np.vstack((t1,t2))#竖直拼接 np.hstack((t1,t2))#水平拼接
数组的行列交换
数组水平或者竖直拼接很简单,但是拼接之前应该注意什么? 竖直拼接的时候:每一列代表的意义相同!!!否则牛头不对马嘴 如果每一列的意义不同,这个时候应该交换某一组的数的列,让其和另外一类相同 那么问题来了? 如何交换某个数组的行或者列呢?
例如:
import numpy as np t = np.arange(12,24).reshape(3,4) print(t) #行与行交换 t[[0,2],:] = t[[2,0],:] print(t)
import numpy as np t = np.arange(12,24).reshape(3,4) print(t) #列与列交换 t[:,[0,3]] = t[:,[3,0]] print(t)
现在希望把之前案例中两个国家的数据方法一起来研究分析,同时保留国家的信息(每条数据的国家来源),应该怎么办
numpy更多好用的方法:
1、获取最大值最小值的位置
1)np.argmax(t,axis=0)
2) np.argmin(t,axis=1)
2、创建一个全为0的数组:np.zeros((3,4))
3、创建一个全为1的数组:np.ones((3,4))
4、创建一个对角线为1的正方形数组(方阵):np.eye(3)
import numpy as np t = np.arange(12,24).reshape(3,4) print(t) print(np.argmax(t,axis=0))#必须是行元素之间比 #[2 2 2 2]索引的是位置 print(np.argmin(t,axis=1))#[0 0 0]
import numpy as np print(np.zeros((3,4))) """ [[0. 0. 0. 0.] [0. 0. 0. 0.] [0. 0. 0. 0.]]""" print(np.ones((3,4))) """ [[1. 1. 1. 1.] [1. 1. 1. 1.] [1. 1. 1. 1.]]""" print(np.eye(4)) """ [[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]] """
有了这些方法,那么刚才的问题就可以迎刃而解啦。用0代表美国,1代表英国,先分别拼接在对应的位置上,在将美国和英国垂直拼接。就可以对相关操作啦。
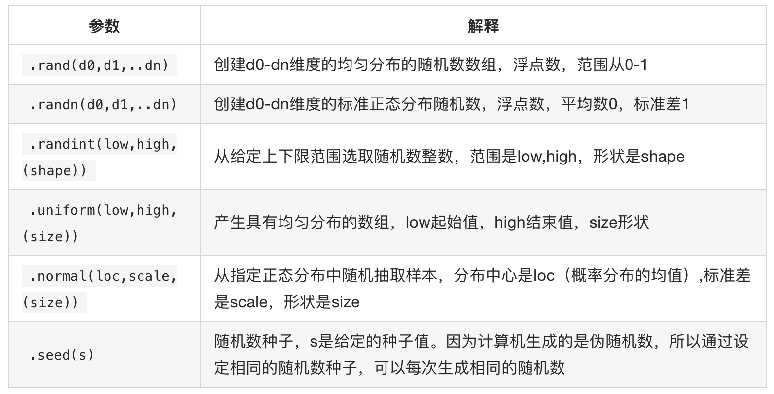
分布的补充:
均匀分布:
在相同的大小范围内的出现概率是等可能的
正态分布:
呈钟型,两头低,中间高,左右对称
numpy的注意点copy和view:
a=b 完全不复制,a和b相互影响
a = b[:],视图的操作,一种切片,会创建新的对象a,但是a的数据完全由b保管,他们两个的数据变化是一致的,
a = b.copy(),复制,a和b互不影响
标签:完成 压缩文件 连续 pytho 随机数 空格 常用 保留 压缩
原文地址:https://www.cnblogs.com/lishuntao/p/11625997.html